 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Residual Flow as Dynamic Motion from Stereo Videos
Sep 16, 2019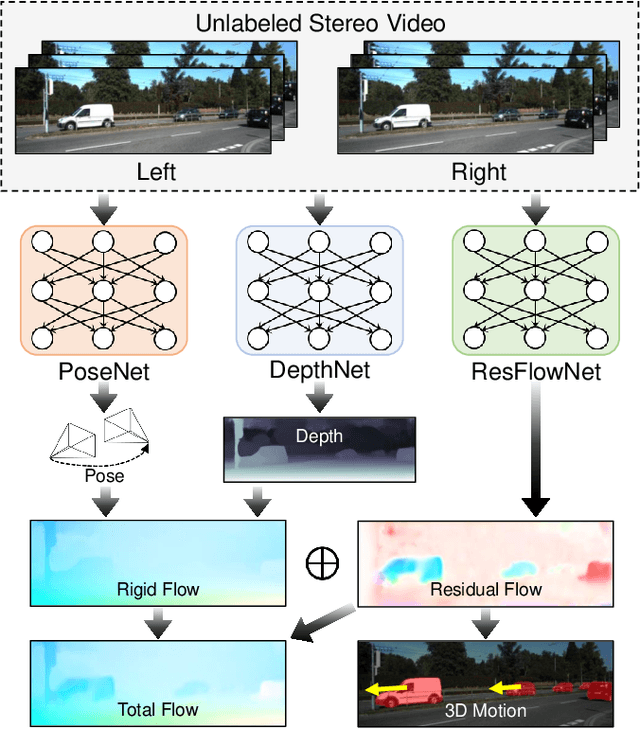
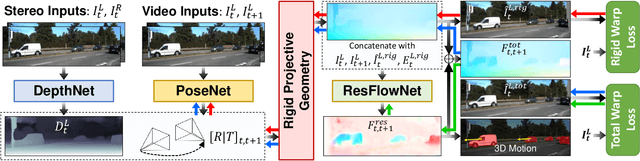
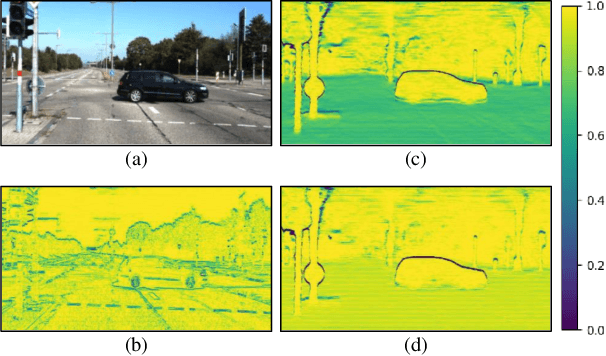
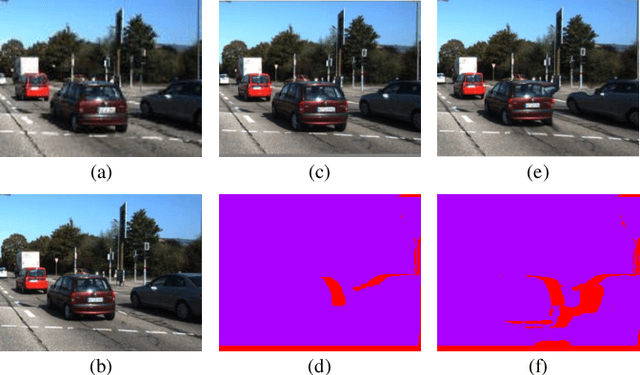
We present a method for decomposing the 3D scene flow observed from a moving stereo rig into stationary scene elements and dynamic object motion. Our unsupervised learning framework jointly reasons about the camera motion, optical flow, and 3D motion of moving objects. Three cooperating networks predict stereo matching, camera motion, and residual flow, which represents the flow component due to object motion and not from camera motion. Based on rigid projective geometry, the estimated stereo depth is used to guide the camera motion estimation, and the depth and camera motion are used to guide the residual flow estimation. We also explicitly estimate the 3D scene flow of dynamic objects based on the residual flow and scene depth. Experiments on the KITTI dataset demonstrate the effectiveness of our approach and show that our method outperforms other state-of-the-art algorithms on the optical flow and visual odometry tasks.
Visuomotor Understanding for Representation Learning of Driving Scenes
Sep 16, 2019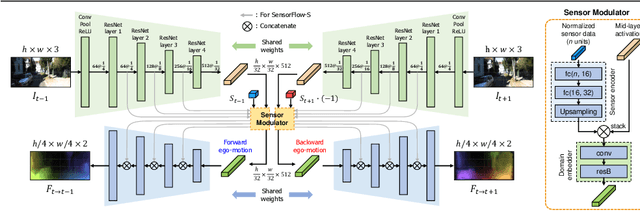
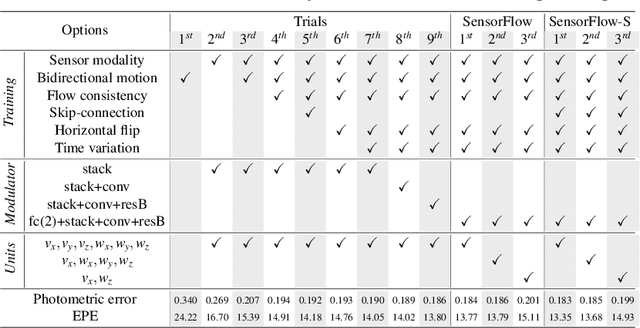
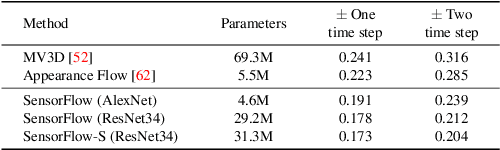
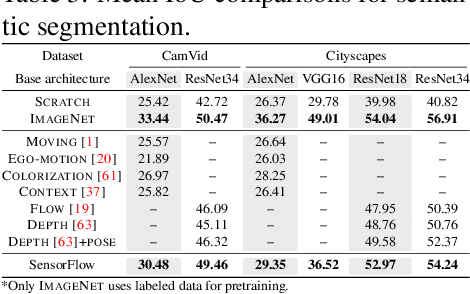
Dashboard cameras capture a tremendous amount of driving scene video each day. These videos are purposefully coupled with vehicle sensing data, such as from the speedometer and inertial sensors, providing an additional sensing modality for free. In this work, we leverage the large-scale unlabeled yet naturally paired data for visual representation learning in the driving scenario. A representation is learned in an end-to-end self-supervised framework for predicting dense optical flow from a single frame with paired sensing data. We postulate that success on this task requires the network to learn semantic and geometric knowledge in the ego-centric view. For example, forecasting a future view to be seen from a moving vehicle requires an understanding of scene depth, scale, and movement of objects. We demonstrate that our learned representation can benefit other tasks that require detailed scene understanding and outperforms competing unsupervised representations on semantic segmentation.
DPSNet: End-to-end Deep Plane Sweep Stereo
May 02, 2019
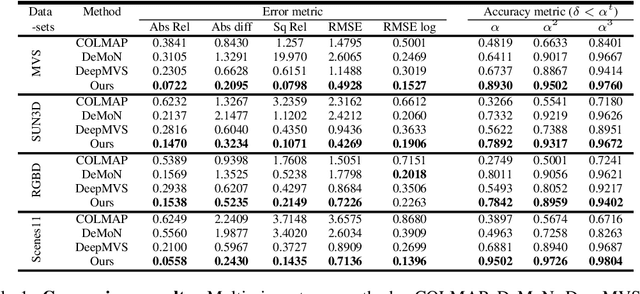
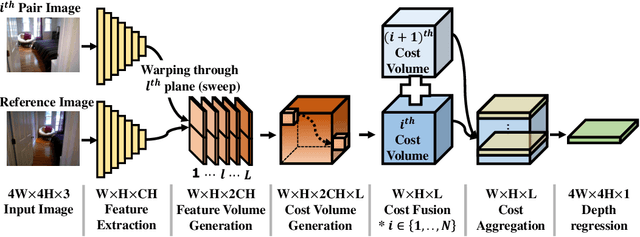
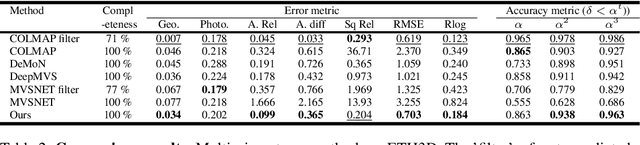
Multiview stereo aims to reconstruct scene depth from images acquired by a camera under arbitrary motion. Recent methods address this problem through deep learning, which can utilize semantic cues to deal with challenges such as textureless and reflective regions. In this paper, we present a convolutional neural network called DPSNet (Deep Plane Sweep Network) whose design is inspired by best practices of traditional geometry-based approaches for dense depth reconstruction. Rather than directly estimating depth and/or optical flow correspondence from image pairs as done in many previous deep learning methods, DPSNet takes a plane sweep approach that involves building a cost volume from deep features using the plane sweep algorithm, regularizing the cost volume via a context-aware cost aggregation, and regressing the dense depth map from the cost volume. The cost volume is constructed using a differentiable warping process that allows for end-to-end training of the network. Through the effective incorporation of conventional multiview stereo concepts within a deep learning framework, DPSNet achieves state-of-the-art reconstruction results on a variety of challenging datasets.
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
Apr 25, 2019
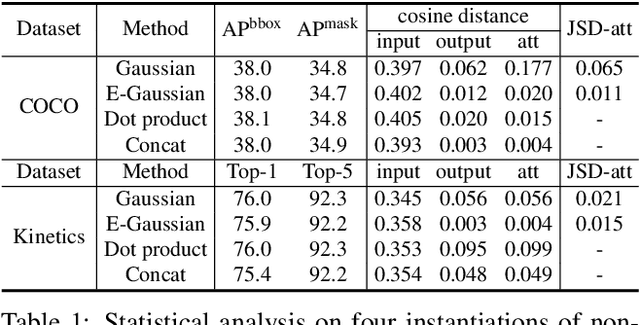

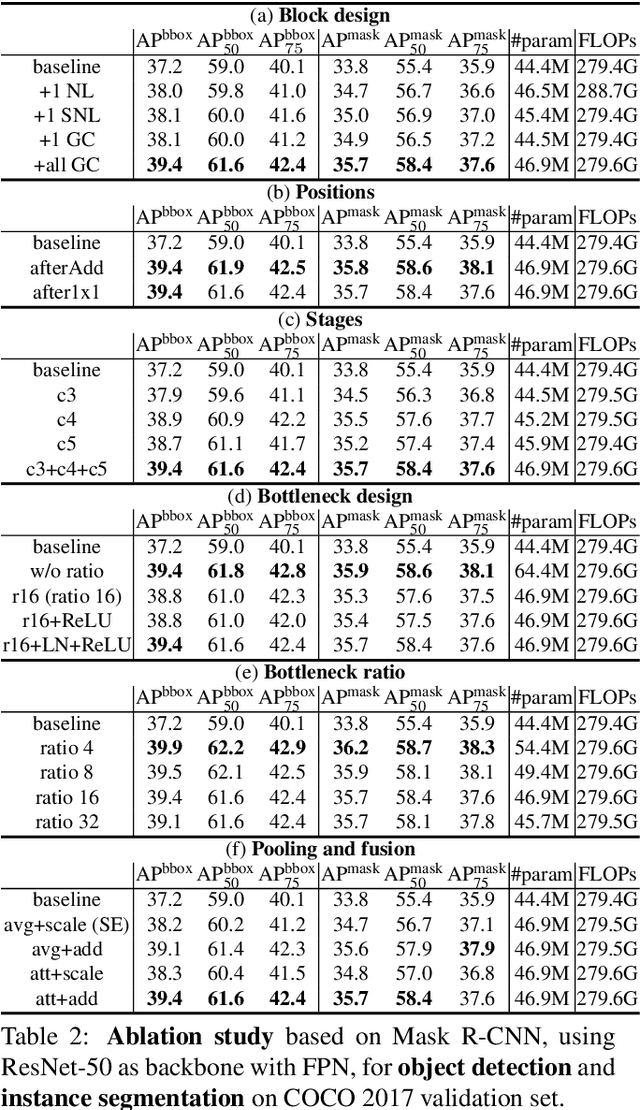
The Non-Local Network (NLNet) presents a pioneering approach for capturing long-range dependencies, via aggregating query-specific global context to each query position. However, through a rigorous empirical analysis, we have found that the global contexts modeled by non-local network are almost the same for different query positions within an image. In this paper, we take advantage of this finding to create a simplified network based on a query-independent formulation, which maintains the accuracy of NLNet but with significantly less computation. We further observe that this simplified design shares similar structure with Squeeze-Excitation Network (SENet). Hence we unify them into a three-step general framework for global context modeling. Within the general framework, we design a better instantiation, called the global context (GC) block, which is lightweight and can effectively model the global context. The lightweight property allows us to apply it for multiple layers in a backbone network to construct a global context network (GCNet), which generally outperforms both simplified NLNet and SENet on major benchmarks for various recognition tasks. The code and configurations are released at https://github.com/xvjiarui/GCNet.
Local Relation Networks for Image Recognition
Apr 25, 2019
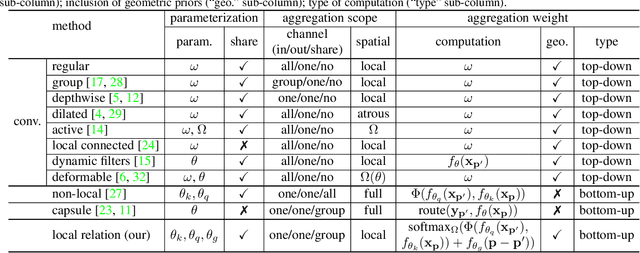
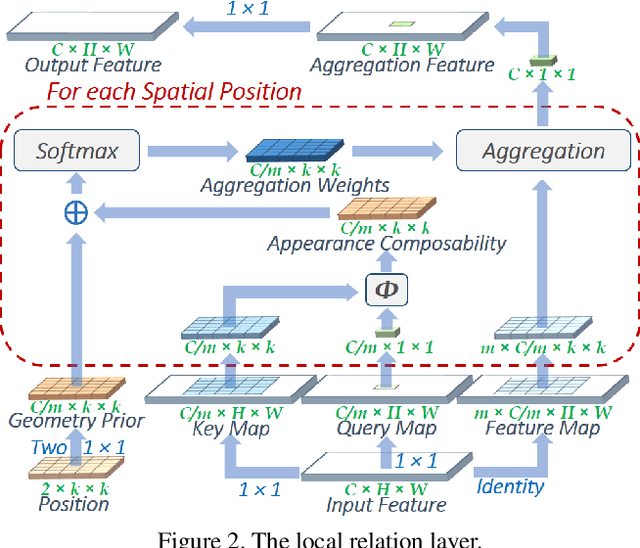
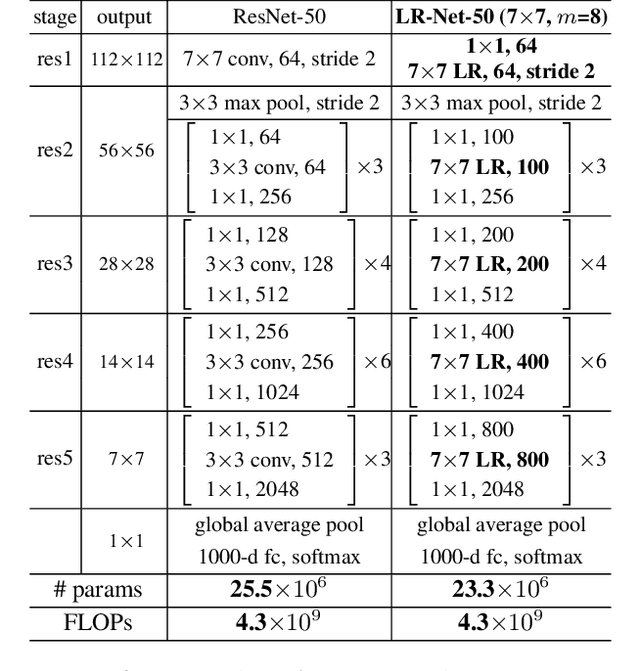
The convolution layer has been the dominant feature extractor in computer vision for years. However, the spatial aggregation in convolution is basically a pattern matching process that applies fixed filters which are inefficient at modeling visual elements with varying spatial distributions. This paper presents a new image feature extractor, called the local relation layer, that adaptively determines aggregation weights based on the compositional relationship of local pixel pairs. With this relational approach, it can composite visual elements into higher-level entities in a more efficient manner that benefits semantic inference. A network built with local relation layers, called the Local Relation Network (LR-Net), is found to provide greater modeling capacity than its counterpart built with regular convolution on large-scale recognition tasks such as ImageNet classification.
RepPoints: Point Set Representation for Object Detection
Apr 25, 2019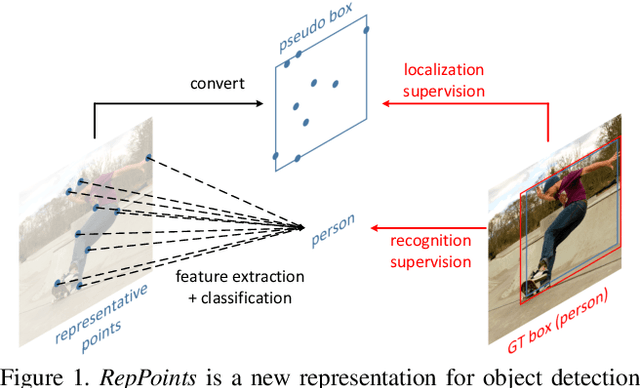
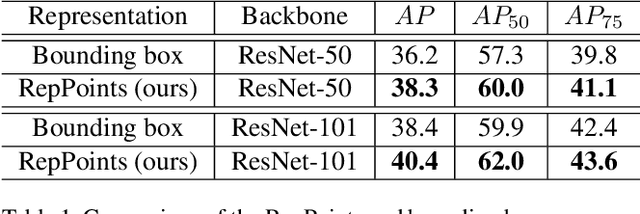
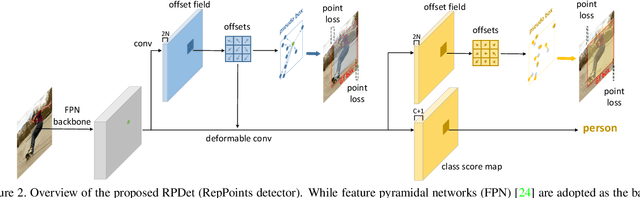
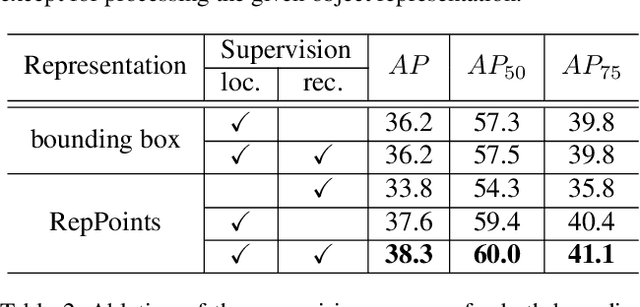
Modern object detectors rely heavily on rectangular bounding boxes, such as anchors, proposals and the final predictions, to represent objects at various recognition stages. The bounding box is convenient to use but provides only a coarse localization of objects and leads to a correspondingly coarse extraction of object features. In this paper, we present \textbf{RepPoints} (representative points), a new finer representation of objects as a set of sample points useful for both localization and recognition. Given ground truth localization and recognition targets for training, RepPoints learn to automatically arrange themselves in a manner that bounds the spatial extent of an object and indicates semantically significant local areas. They furthermore do not require the use of anchors to sample a space of bounding boxes. We show that an anchor-free object detector based on RepPoints, implemented without multi-scale training and testing, can be as effective as state-of-the-art anchor-based detection methods, with 42.8 AP and 65.0 $AP_{50}$ on the COCO test-dev detection benchmark.
An Empirical Study of Spatial Attention Mechanisms in Deep Networks
Apr 11, 2019

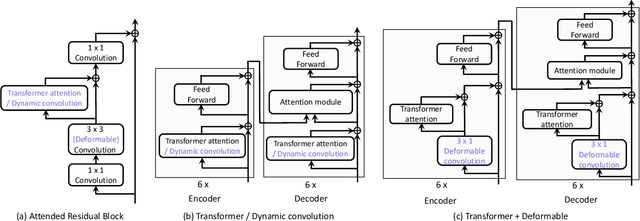
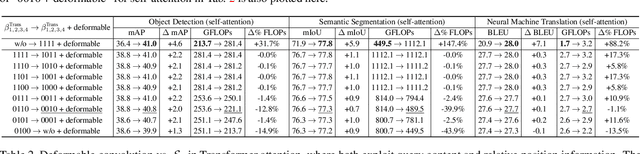
Attention mechanisms have become a popular component in deep neural networks, yet there has been little examination of how different influencing factors and methods for computing attention from these factors affect performance. Toward a better general understanding of attention mechanisms, we present an empirical study that ablates various spatial attention elements within a generalized attention formulation, encompassing the dominant Transformer attention as well as the prevalent deformable convolution and dynamic convolution modules. Conducted on a variety of applications, the study yields significant findings about spatial attention in deep networks, some of which run counter to conventional understanding. For example, we find that the query and key content comparison in Transformer attention is negligible for self-attention, but vital for encoder-decoder attention. A proper combination of deformable convolution with key content only saliency achieves the best accuracy-efficiency tradeoff in self-attention. Our results suggest that there exists much room for improvement in the design of attention mechanisms.
Mimicking the In-Camera Color Pipeline for Camera-Aware Object Compositing
Mar 27, 2019
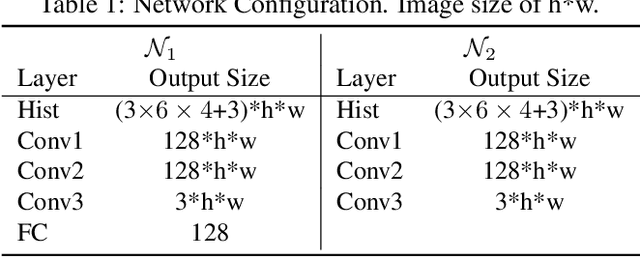
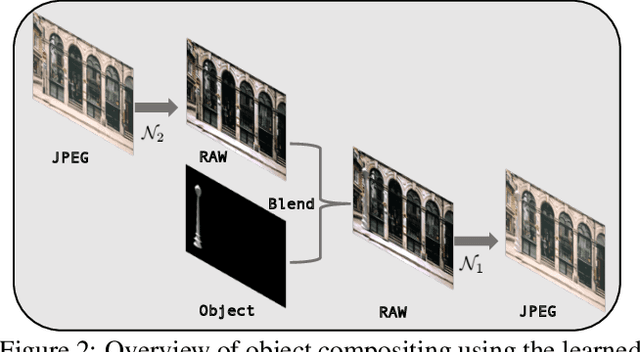
We present a method for compositing virtual objects into a photograph such that the object colors appear to have been processed by the photo's camera imaging pipeline. Compositing in such a camera-aware manner is essential for high realism, and it requires the color transformation in the photo's pipeline to be inferred, which is challenging due to the inherent one-to-many mapping that exists from a scene to a photo. To address this problem for the case of a single photo taken from an unknown camera, we propose a dual-learning approach in which the reverse color transformation (from the photo to the scene) is jointly estimated. Learning of the reverse transformation is used to facilitate learning of the forward mapping, by enforcing cycle consistency of the two processes. We additionally employ a feature sharing schema to extract evidence from the target photo in the reverse mapping to guide the forward color transformation. Our dual-learning approach achieves object compositing results that surpass those of alternative techniques.
Angle-Closure Detection in Anterior Segment OCT based on Multi-Level Deep Network
Feb 10, 2019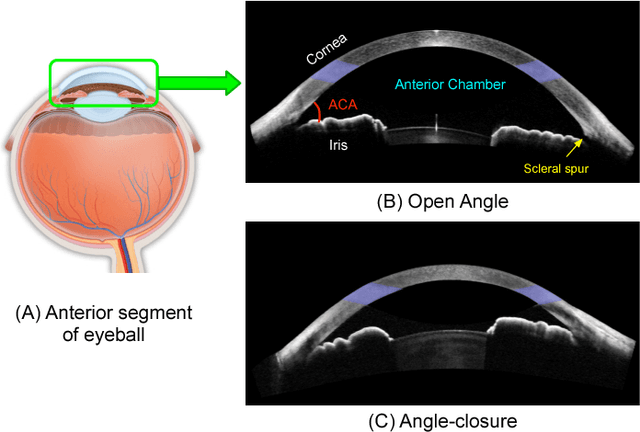

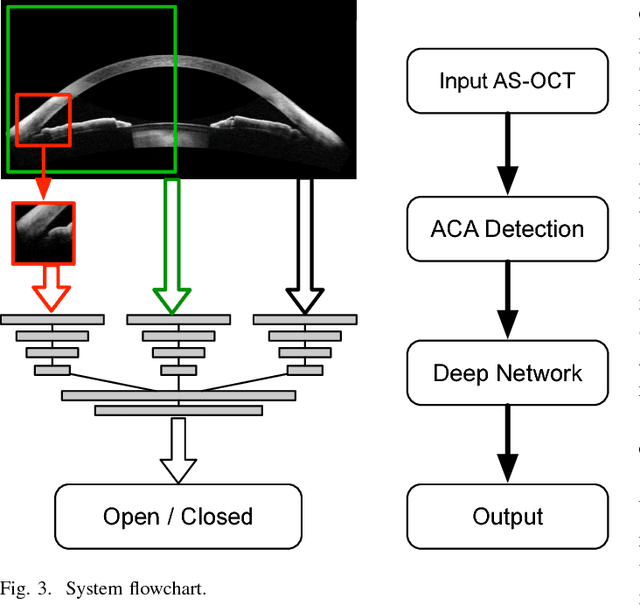
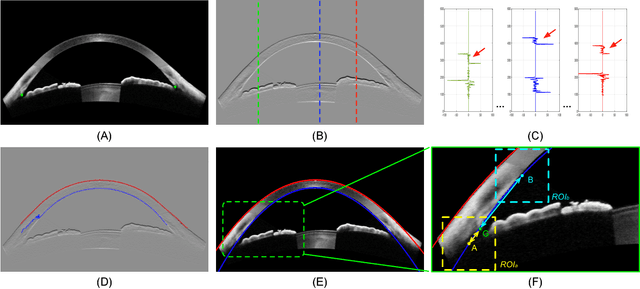
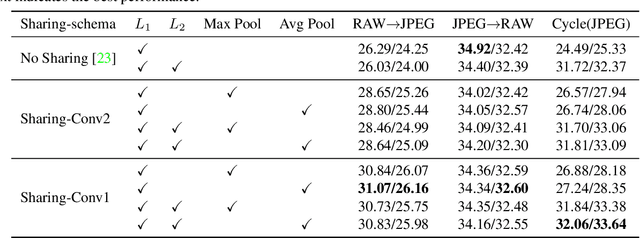
Irreversible visual impairment is often caused by primary angle-closure glaucoma, which could be detected via Anterior Segment Optical Coherence Tomography (AS-OCT). In this paper, an automated system based on deep learning is presented for angle-closure detection in AS-OCT images. Our system learns a discriminative representation from training data that captures subtle visual cues not modeled by handcrafted features. A Multi-Level Deep Network (MLDN) is proposed to formulate this learning, which utilizes three particular AS-OCT regions based on clinical priors: the global anterior segment structure, local iris region, and anterior chamber angle (ACA) patch. In our method, a sliding window based detector is designed to localize the ACA region, which addresses ACA detection as a regression task. Then, three parallel sub-networks are applied to extract AS-OCT representations for the global image and at clinically-relevant local regions. Finally, the extracted deep features of these sub-networks are concatenated into one fully connected layer to predict the angle-closure detection result. In the experiments, our system is shown to surpass previous detection methods and other deep learning systems on two clinical AS-OCT datasets.
Deep Metric Transfer for Label Propagation with Limited Annotated Data
Dec 20, 2018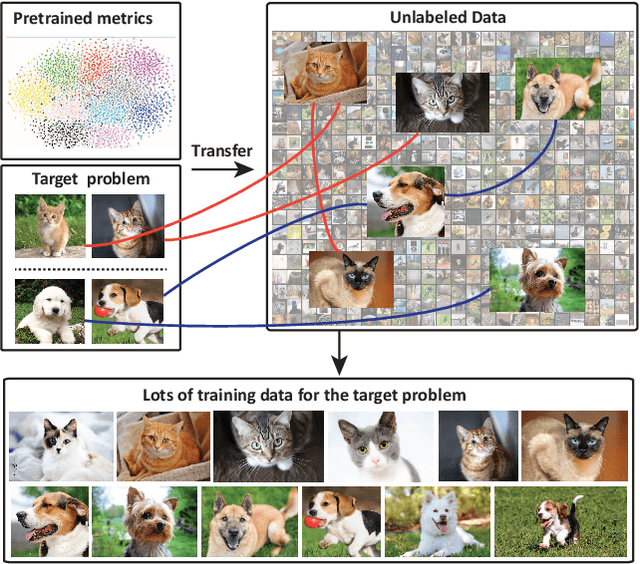
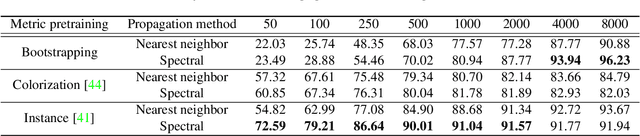
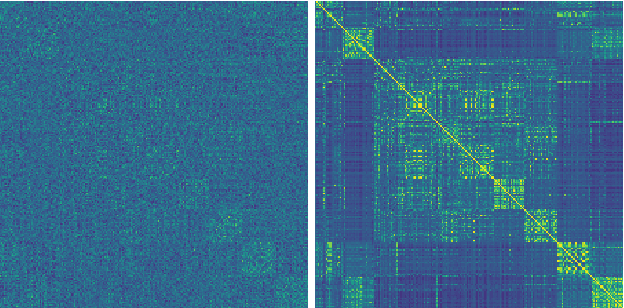
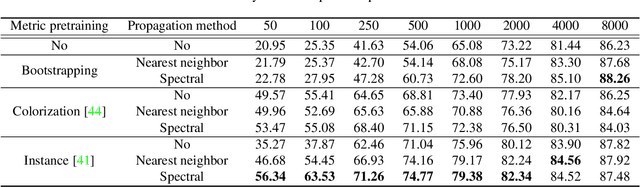
We study object recognition under the constraint that each object class is only represented by very few observations. In such cases, naive supervised learning would lead to severe over-fitting in deep neural networks due to limited training data. We tackle this problem by creating much more training data through label propagation from the few labeled examples to a vast collection of unannotated images. Our main insight is that such a label propagation scheme can be highly effective when the similarity metric used for propagation is learned and transferred from other related domains with lots of data. We test our approach on semi-supervised learning, transfer learning and few-shot recognition, where we learn our similarity metric using various supervised/unsupervised pretraining methods, and transfer it to unlabeled data across different data distributions. By taking advantage of unlabeled data in this way, we achieve significant improvements on all three tasks. Notably, our approach outperforms current state-of-the-art techniques by an absolute $20\%$ for semi-supervised learning on CIFAR10, $10\%$ for transfer learning from ImageNet to CIFAR10, and $6\%$ for few-shot recognition on mini-ImageNet, when labeled examples are limited.