 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNViSII: A Scriptable Tool for Photorealistic Image Generation
May 28, 2021

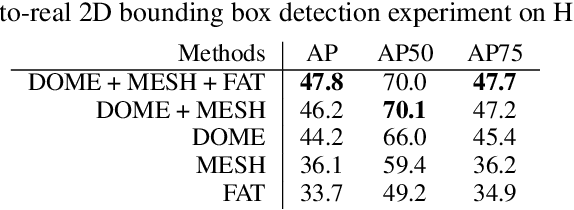

We present a Python-based renderer built on NVIDIA's OptiX ray tracing engine and the OptiX AI denoiser, designed to generate high-quality synthetic images for research in computer vision and deep learning. Our tool enables the description and manipulation of complex dynamic 3D scenes containing object meshes, materials, textures, lighting, volumetric data (e.g., smoke), and backgrounds. Metadata, such as 2D/3D bounding boxes, segmentation masks, depth maps, normal maps, material properties, and optical flow vectors, can also be generated. In this work, we discuss design goals, architecture, and performance. We demonstrate the use of data generated by path tracing for training an object detector and pose estimator, showing improved performance in sim-to-real transfer in situations that are difficult for traditional raster-based renderers. We offer this tool as an easy-to-use, performant, high-quality renderer for advancing research in synthetic data generation and deep learning.
DexYCB: A Benchmark for Capturing Hand Grasping of Objects
Apr 09, 2021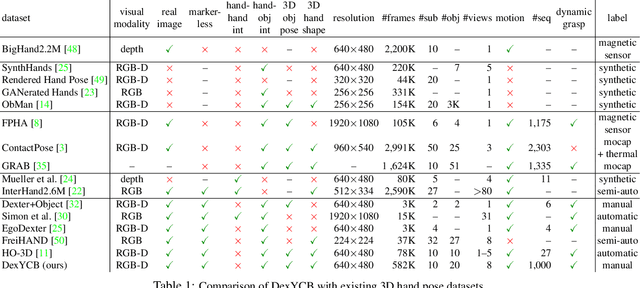

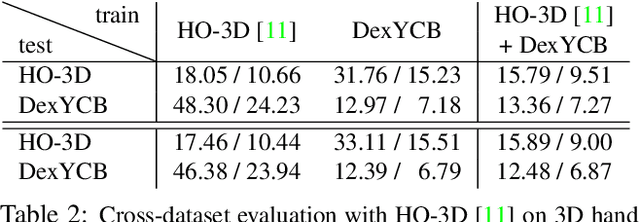

We introduce DexYCB, a new dataset for capturing hand grasping of objects. We first compare DexYCB with a related one through cross-dataset evaluation. We then present a thorough benchmark of state-of-the-art approaches on three relevant tasks: 2D object and keypoint detection, 6D object pose estimation, and 3D hand pose estimation. Finally, we evaluate a new robotics-relevant task: generating safe robot grasps in human-to-robot object handover. Dataset and code are available at https://dex-ycb.github.io.
Deep Two-View Structure-from-Motion Revisited
Apr 01, 2021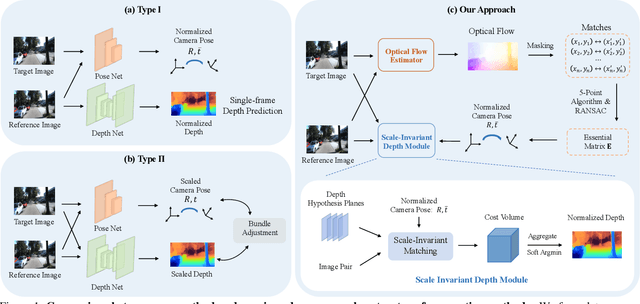
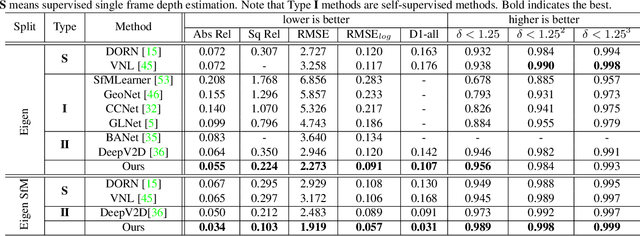


Two-view structure-from-motion (SfM) is the cornerstone of 3D reconstruction and visual SLAM. Existing deep learning-based approaches formulate the problem by either recovering absolute pose scales from two consecutive frames or predicting a depth map from a single image, both of which are ill-posed problems. In contrast, we propose to revisit the problem of deep two-view SfM by leveraging the well-posedness of the classic pipeline. Our method consists of 1) an optical flow estimation network that predicts dense correspondences between two frames; 2) a normalized pose estimation module that computes relative camera poses from the 2D optical flow correspondences, and 3) a scale-invariant depth estimation network that leverages epipolar geometry to reduce the search space, refine the dense correspondences, and estimate relative depth maps. Extensive experiments show that our method outperforms all state-of-the-art two-view SfM methods by a clear margin on KITTI depth, KITTI VO, MVS, Scenes11, and SUN3D datasets in both relative pose and depth estimation.
Multi-view Fusion for Multi-level Robotic Scene Understanding
Mar 25, 2021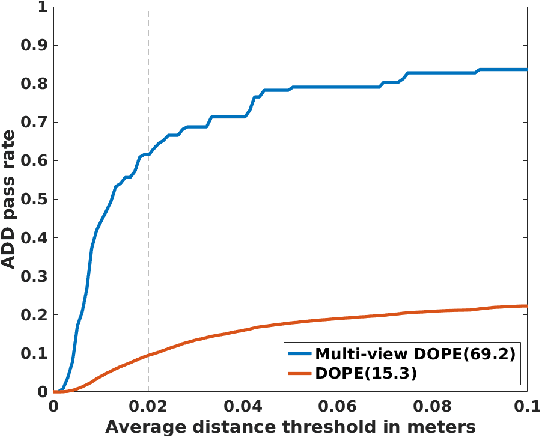

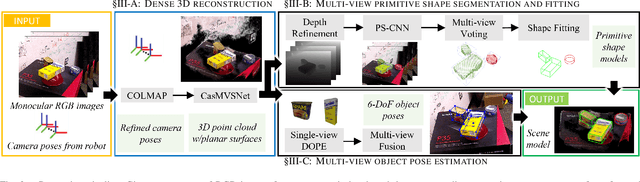

We present a system for multi-level scene awareness for robotic manipulation. Given a sequence of camera-in-hand RGB images, the system calculates three types of information: 1) a point cloud representation of all the surfaces in the scene, for the purpose of obstacle avoidance. 2) the rough pose of unknown objects from categories corresponding to primitive shapes (e.g., cuboids and cylinders), and 3) full 6-DoF pose of known objects. By developing and fusing recent techniques in these domains, we provide a rich scene representation for robot awareness. We demonstrate the importance of each of these modules, their complementary nature, and the potential benefits of the system in the context of robotic manipulation.
Hierarchical Planning for Long-Horizon Manipulation with Geometric and Symbolic Scene Graphs
Dec 14, 2020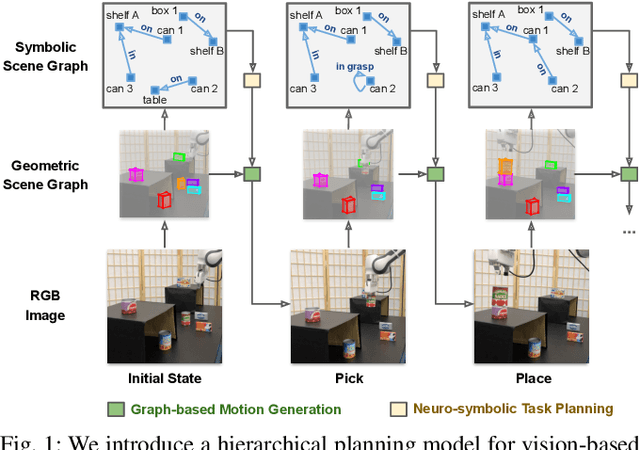
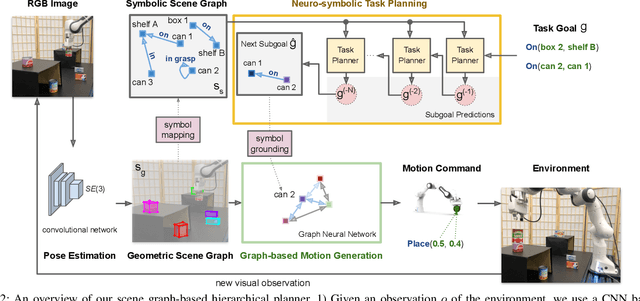

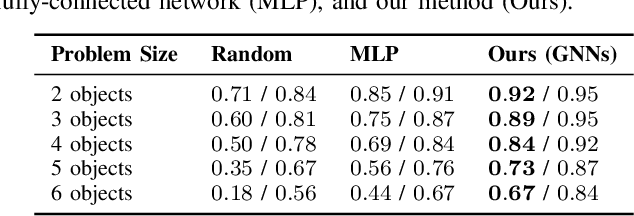
We present a visually grounded hierarchical planning algorithm for long-horizon manipulation tasks. Our algorithm offers a joint framework of neuro-symbolic task planning and low-level motion generation conditioned on the specified goal. At the core of our approach is a two-level scene graph representation, namely geometric scene graph and symbolic scene graph. This hierarchical representation serves as a structured, object-centric abstraction of manipulation scenes. Our model uses graph neural networks to process these scene graphs for predicting high-level task plans and low-level motions. We demonstrate that our method scales to long-horizon tasks and generalizes well to novel task goals. We validate our method in a kitchen storage task in both physical simulation and the real world. Our experiments show that our method achieved over 70% success rate and nearly 90% of subgoal completion rate on the real robot while being four orders of magnitude faster in computation time compared to standard search-based task-and-motion planner.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020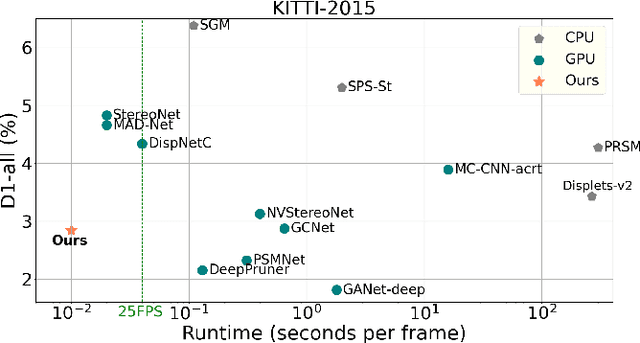

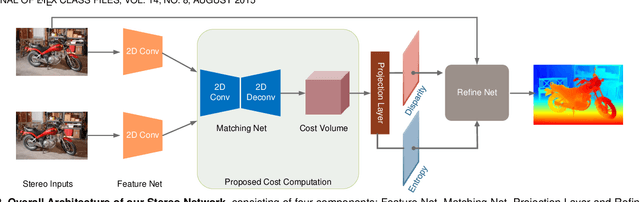
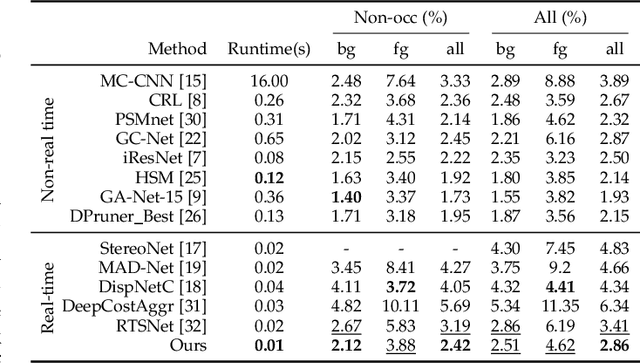
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
Fast Uncertainty Quantification for Deep Object Pose Estimation
Nov 16, 2020


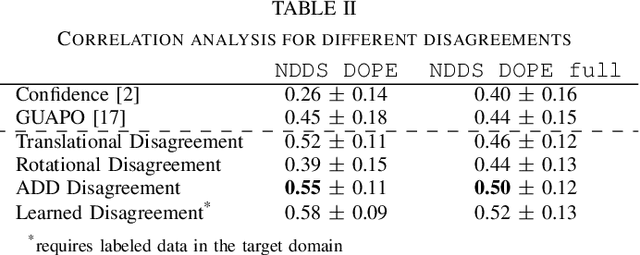
Deep learning-based object pose estimators are often unreliable and overconfident especially when the input image is outside the training domain, for instance, with sim2real transfer. Efficient and robust uncertainty quantification (UQ) in pose estimators is critically needed in many robotic tasks. In this work, we propose a simple, efficient, and plug-and-play UQ method for 6-DoF object pose estimation. We ensemble 2-3 pre-trained models with different neural network architectures and/or training data sources, and compute their average pairwise disagreement against one another to obtain the uncertainty quantification. We propose four disagreement metrics, including a learned metric, and show that the average distance (ADD) is the best learning-free metric and it is only slightly worse than the learned metric, which requires labeled target data. Our method has several advantages compared to the prior art: 1) our method does not require any modification of the training process or the model inputs; and 2) it needs only one forward pass for each model. We evaluate the proposed UQ method on three tasks where our uncertainty quantification yields much stronger correlations with pose estimation errors than the baselines. Moreover, in a real robot grasping task, our method increases the grasping success rate from 35% to 90%.
Joint Space Control via Deep Reinforcement Learning
Nov 12, 2020
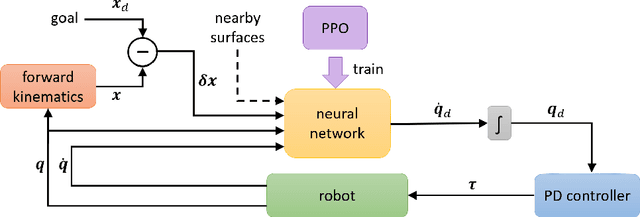

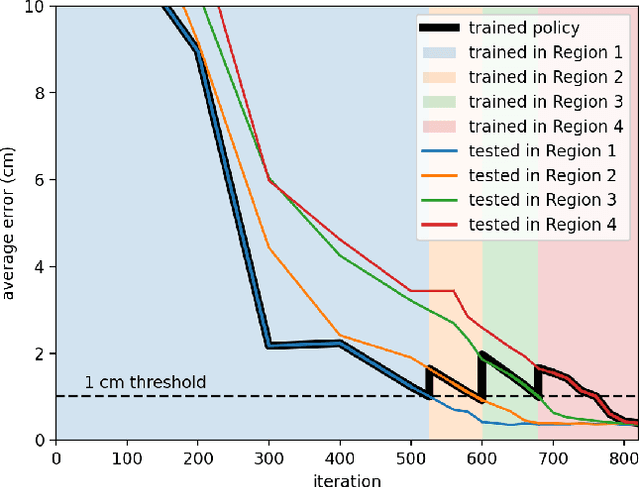
The dominant way to control a robot manipulator uses hand-crafted differential equations leveraging some form of inverse kinematics / dynamics. We propose a simple, versatile joint-level controller that dispenses with differential equations entirely. A deep neural network, trained via model-free reinforcement learning, is used to map from task space to joint space. Experiments show the method capable of achieving similar error to traditional methods, while greatly simplifying the process by automatically handling redundancy, joint limits, and acceleration / deceleration profiles. The basic technique is extended to avoid obstacles by augmenting the input to the network with information about the nearest obstacles. Results are shown both in simulation and on a real robot via sim-to-real transfer of the learned policy. We show that it is possible to achieve sub-centimeter accuracy, both in simulation and the real world, with a moderate amount of training.
Indirect Object-to-Robot Pose Estimation from an External Monocular RGB Camera
Aug 26, 2020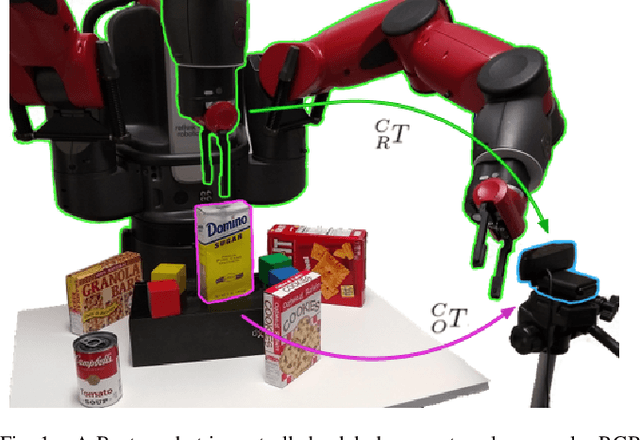


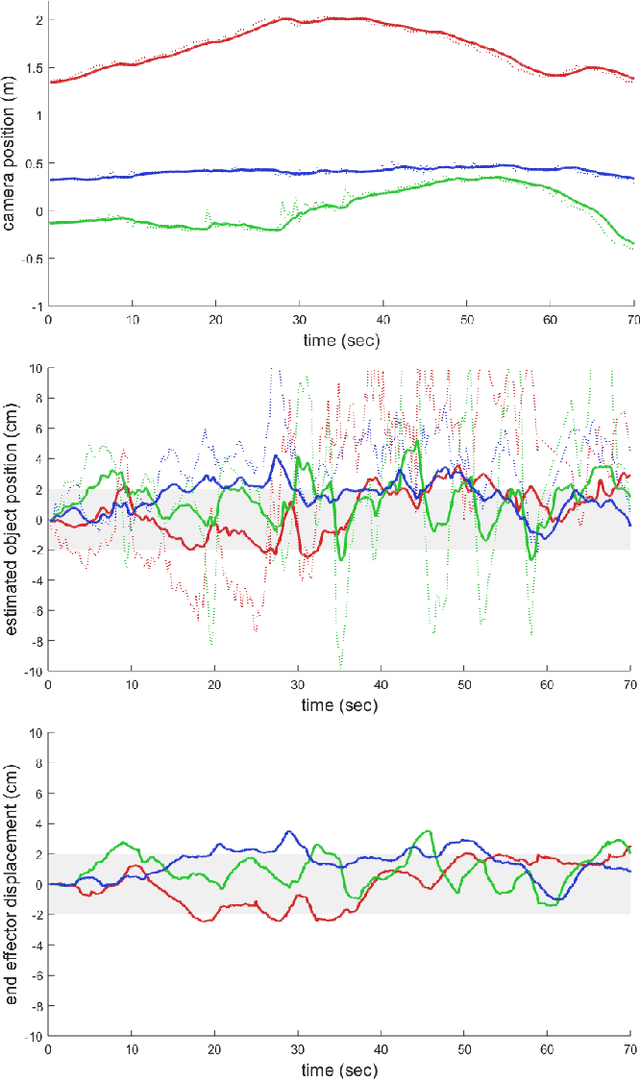
We present a robotic grasping system that uses a single external monocular RGB camera as input. The object-to-robot pose is computed indirectly by combining the output of two neural networks: one that estimates the object-to-camera pose, and another that estimates the robot-to-camera pose. Both networks are trained entirely on synthetic data, relying on domain randomization to bridge the sim-to-real gap. Because the latter network performs online camera calibration, the camera can be moved freely during execution without affecting the quality of the grasp. Experimental results analyze the effect of camera placement, image resolution, and pose refinement in the context of grasping several household objects. We also present results on a new set of 28 textured household toy grocery objects, which have been selected to be accessible to other researchers. To aid reproducibility of the research, we offer 3D scanned textured models, along with pre-trained weights for pose estimation.
Improving Deep Stereo Network Generalization with Geometric Priors
Aug 25, 2020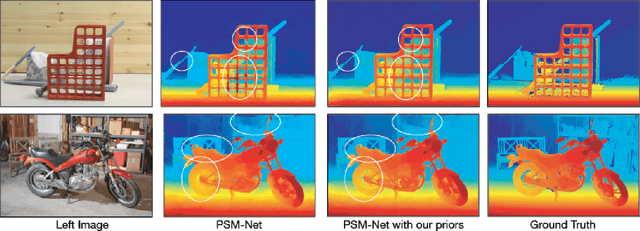
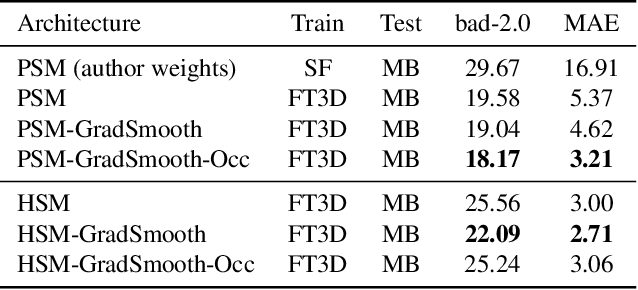
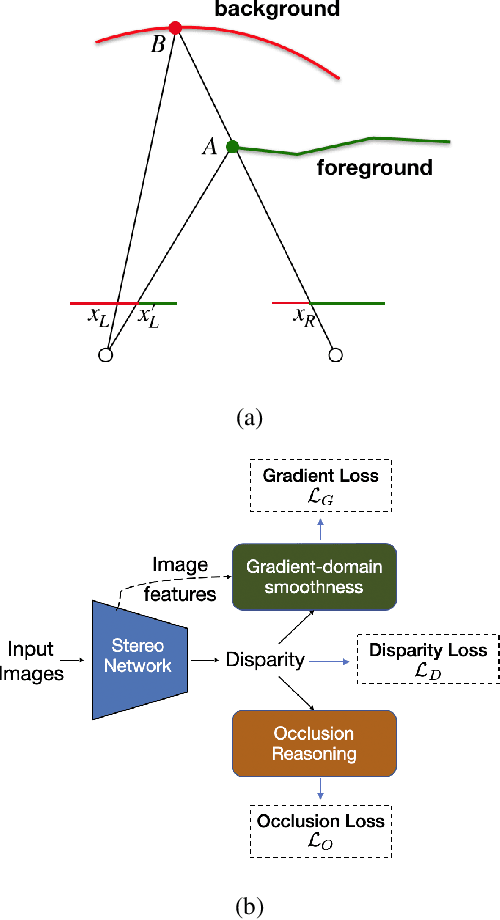
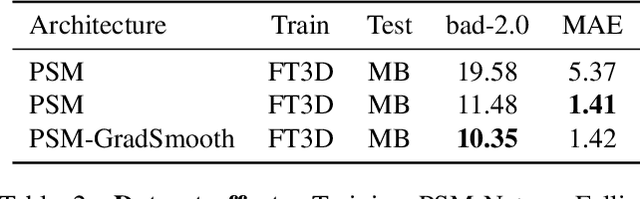
End-to-end deep learning methods have advanced stereo vision in recent years and obtained excellent results when the training and test data are similar. However, large datasets of diverse real-world scenes with dense ground truth are difficult to obtain and currently not publicly available to the research community. As a result, many algorithms rely on small real-world datasets of similar scenes or synthetic datasets, but end-to-end algorithms trained on such datasets often generalize poorly to different images that arise in real-world applications. As a step towards addressing this problem, we propose to incorporate prior knowledge of scene geometry into an end-to-end stereo network to help networks generalize better. For a given network, we explicitly add a gradient-domain smoothness prior and occlusion reasoning into the network training, while the architecture remains unchanged during inference. Experimentally, we show consistent improvements if we train on synthetic datasets and test on the Middlebury (real images) dataset. Noticeably, we improve PSM-Net accuracy on Middlebury from 5.37 MAE to 3.21 MAE without sacrificing speed.