 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Scaling Parallel Sequence Models to Foundation-Scale Vision Encoders
May 30, 2026Vision foundation models are bottlenecked by the quadratic cost of self-attention, which limits usable resolution and increases the cost of large-scale pretraining. Subquadratic alternatives such as linear attention and state-space models reduce this cost, but often serialize images into 1D token streams and weaken the 2D spatial structure important for vision. Generalized Spatial Propagation Networks (GSPN) instead propagate context directly on the 2D grid through line-scan recurrences, achieving near-linear complexity without positional embeddings, but have seen little use as foundation-scale encoders. We present C-GSPN, a foundation-scale vision encoder based on 2D spatial propagation. C-GSPN makes the operator practical through three improvements: (1) a fast GSPN CUDA kernel that fuses per-step launches into a single warp-specialized implementation with shared-memory tiling, coalesced access, and a compact multi-channel propagation, reaching over 90% of peak memory bandwidth and running up to 40--52x faster than the original GSPN implementation; (2) a compressed latent-space propagation block with fused normalization, which turns kernel-level speed into block- and model-level efficiency; and (3) a two-stage cross-operator distillation recipe that trains the new architecture from an attention teacher without the cost of from-scratch foundation-scale training. Distilled with 600M image-text pairs, C-GSPN matches an isomorphic ViT baseline with 15% fewer parameters, improves ADE20K segmentation by +2.1%, transfers to high resolution with a fraction of the data needed from scratch, and delivers a 4x end-to-end block speedup at 2K with single-pass, tiling-free inference.
MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views
Jun 09, 2020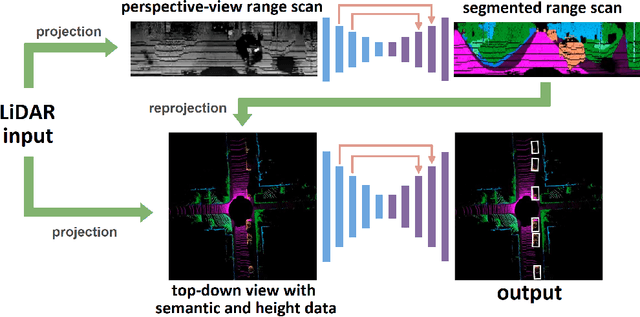
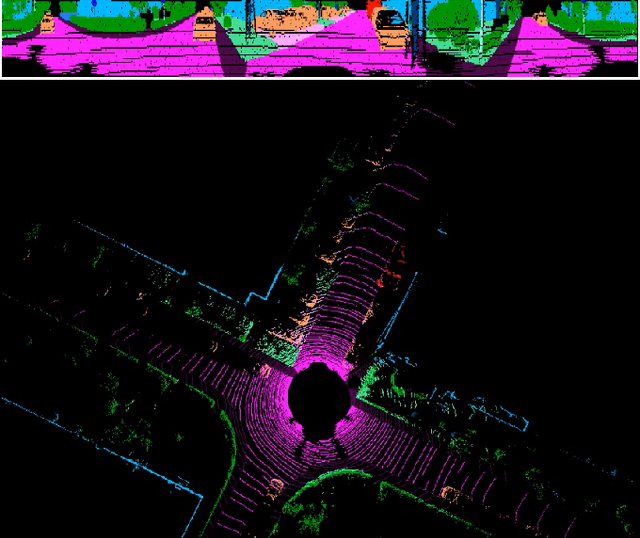


Autonomous driving requires the inference of actionable information such as detecting and classifying objects, and determining the drivable space. To this end, we present a two-stage deep neural network (MVLidarNet) for multi-class object detection and drivable segmentation using multiple views of a single LiDAR point cloud. The first stage processes the point cloud projected onto a perspective view in order to semantically segment the scene. The second stage then processes the point cloud (along with semantic labels from the first stage) projected onto a bird's eye view, to detect and classify objects. Both stages are simple encoder-decoders. We show that our multi-view, multi-stage, multi-class approach is able to detect and classify objects while simultaneously determining the drivable space using a single LiDAR scan as input, in challenging scenes with more than one hundred vehicles and pedestrians at a time. The system operates efficiently at 150 fps on an embedded GPU designed for a self-driving car, including a postprocessing step to maintain identities over time. We show results on both KITTI and a much larger internal dataset, thus demonstrating the method's ability to scale by an order of magnitude.
Learning Semantic Vector Representations of Source Code via a Siamese Neural Network
Apr 26, 2019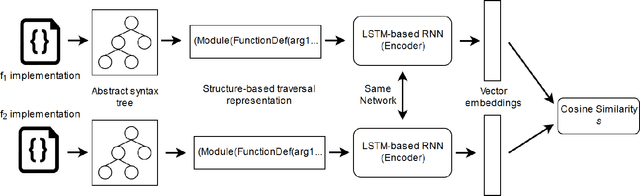



The abundance of open-source code, coupled with the success of recent advances in deep learning for natural language processing, has given rise to a promising new application of machine learning to source code. In this work, we explore the use of a Siamese recurrent neural network model on Python source code to create vectors which capture the semantics of code. We evaluate the quality of embeddings by identifying which problem from a programming competition the code solves. Our model significantly outperforms a bag-of-tokens embedding, providing promising results for improving code embeddings that can be used in future software engineering tasks.