 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccluded Human Pose Estimation based on Limb Joint Augmentation
Oct 13, 2024Human pose estimation aims at locating the specific joints of humans from the images or videos. While existing deep learning-based methods have achieved high positioning accuracy, they often struggle with generalization in occlusion scenarios. In this paper, we propose an occluded human pose estimation framework based on limb joint augmentation to enhance the generalization ability of the pose estimation model on the occluded human bodies. Specifically, the occlusion blocks are at first employed to randomly cover the limb joints of the human bodies from the training images, imitating the scene where the objects or other people partially occlude the human body. Trained by the augmented samples, the pose estimation model is encouraged to accurately locate the occluded keypoints based on the visible ones. To further enhance the localization ability of the model, this paper constructs a dynamic structure loss function based on limb graphs to explore the distribution of occluded joints by evaluating the dependence between adjacent joints. Extensive experimental evaluations on two occluded datasets, OCHuman and CrowdPose, demonstrate significant performance improvements without additional computation cost during inference.
Integrative Decoding: Improve Factuality via Implicit Self-consistency
Oct 02, 2024



Self-consistency-based approaches, which involve repeatedly sampling multiple outputs and selecting the most consistent one as the final response, prove to be remarkably effective in improving the factual accuracy of large language models. Nonetheless, existing methods usually have strict constraints on the task format, largely limiting their applicability. In this paper, we present Integrative Decoding (ID), to unlock the potential of self-consistency in open-ended generation tasks. ID operates by constructing a set of inputs, each prepended with a previously sampled response, and then processes them concurrently, with the next token being selected by aggregating of all their corresponding predictions at each decoding step. In essence, this simple approach implicitly incorporates self-consistency in the decoding objective. Extensive evaluation shows that ID consistently enhances factuality over a wide range of language models, with substantial improvements on the TruthfulQA (+11.2%), Biographies (+15.4%) and LongFact (+8.5%) benchmarks. The performance gains amplify progressively as the number of sampled responses increases, indicating the potential of ID to scale up with repeated sampling.
ReliOcc: Towards Reliable Semantic Occupancy Prediction via Uncertainty Learning
Sep 26, 2024



Vision-centric semantic occupancy prediction plays a crucial role in autonomous driving, which requires accurate and reliable predictions from low-cost sensors. Although having notably narrowed the accuracy gap with LiDAR, there is still few research effort to explore the reliability in predicting semantic occupancy from camera. In this paper, we conduct a comprehensive evaluation of existing semantic occupancy prediction models from a reliability perspective for the first time. Despite the gradual alignment of camera-based models with LiDAR in term of accuracy, a significant reliability gap persists. To addresses this concern, we propose ReliOcc, a method designed to enhance the reliability of camera-based occupancy networks. ReliOcc provides a plug-and-play scheme for existing models, which integrates hybrid uncertainty from individual voxels with sampling-based noise and relative voxels through mix-up learning. Besides, an uncertainty-aware calibration strategy is devised to further enhance model reliability in offline mode. Extensive experiments under various settings demonstrate that ReliOcc significantly enhances model reliability while maintaining the accuracy of both geometric and semantic predictions. Importantly, our proposed approach exhibits robustness to sensor failures and out of domain noises during inference.
GenMapping: Unleashing the Potential of Inverse Perspective Mapping for Robust Online HD Map Construction
Sep 13, 2024



Online High-Definition (HD) maps have emerged as the preferred option for autonomous driving, overshadowing the counterpart offline HD maps due to flexible update capability and lower maintenance costs. However, contemporary online HD map models embed parameters of visual sensors into training, resulting in a significant decrease in generalization performance when applied to visual sensors with different parameters. Inspired by the inherent potential of Inverse Perspective Mapping (IPM), where camera parameters are decoupled from the training process, we have designed a universal map generation framework, GenMapping. The framework is established with a triadic synergy architecture, including principal and dual auxiliary branches. When faced with a coarse road image with local distortion translated via IPM, the principal branch learns robust global features under the state space models. The two auxiliary branches are a dense perspective branch and a sparse prior branch. The former exploits the correlation information between static and moving objects, whereas the latter introduces the prior knowledge of OpenStreetMap (OSM). The triple-enhanced merging module is crafted to synergistically integrate the unique spatial features from all three branches. To further improve generalization capabilities, a Cross-View Map Learning (CVML) scheme is leveraged to realize joint learning within the common space. Additionally, a Bidirectional Data Augmentation (BiDA) module is introduced to mitigate reliance on datasets concurrently. A thorough array of experimental results shows that the proposed model surpasses current state-of-the-art methods in both semantic mapping and vectorized mapping, while also maintaining a rapid inference speed. The source code will be publicly available at https://github.com/lynn-yu/GenMapping.
Exploring the Acoustics of the Chinese Transverse Flute (dizi)
Sep 07, 2024



We investigate the acoustical characteristics of the Chinese transverse flute, the dizi, employing input impedance measurements, modeling and analysis. The input impedances for various fingerings of a bangdi in the key of F, a particular type of the dizi, are measured and compared to models using both the transfer matrix method and the Transfer Matrix Method with external Interaction (TMMI). In order to get more accurate modeling results, we provide specific transfer matrices for the unique components of the dizi, such as back end-holes, membrane hole and upstream branch. The matching volume length correction for holes drilled in a thick wall is also derived. Comparative analysis of modeling and measurement data validates the improved accuracy of TMMI, confirming the influence of radiated sound from closely spaced toneholes.
EPiC: Cost-effective Search-based Prompt Engineering of LLMs for Code Generation
Aug 20, 2024

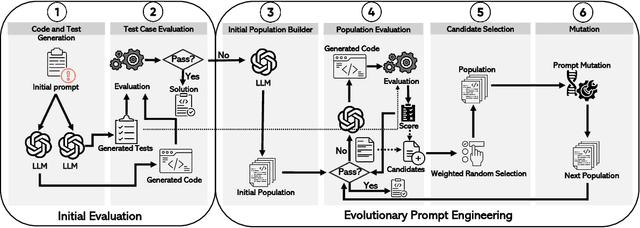
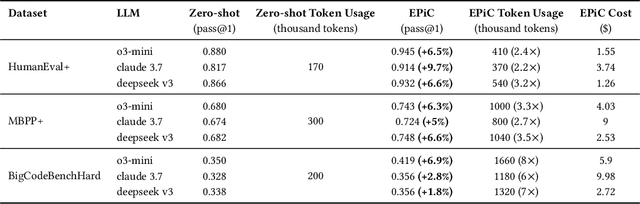
Large Language Models (LLMs) have seen increasing use in various software development tasks, especially in code generation. The most advanced recent methods attempt to incorporate feedback from code execution into prompts to help guide LLMs in generating correct code, in an iterative process. While effective, these methods could be costly and time-consuming due to numerous interactions with the LLM and the extensive token usage. To address this issue, we propose an alternative approach named Evolutionary Prompt Engineering for Code (EPiC), which leverages a lightweight evolutionary algorithm to evolve the original prompts toward better ones that produce high-quality code, with minimal interactions with LLM. Our evaluation against state-of-the-art (SOTA) LLM-based code generation models shows that EPiC outperforms all the baselines in terms of cost-effectiveness.
Understanding and Modeling Job Marketplace with Pretrained Language Models
Aug 08, 2024Job marketplace is a heterogeneous graph composed of interactions among members (job-seekers), companies, and jobs. Understanding and modeling job marketplace can benefit both job seekers and employers, ultimately contributing to the greater good of the society. However, existing graph neural network (GNN)-based methods have shallow understandings of the associated textual features and heterogeneous relations. To address the above challenges, we propose PLM4Job, a job marketplace foundation model that tightly couples pretrained language models (PLM) with job market graph, aiming to fully utilize the pretrained knowledge and reasoning ability to model member/job textual features as well as various member-job relations simultaneously. In the pretraining phase, we propose a heterogeneous ego-graph-based prompting strategy to model and aggregate member/job textual features based on the topological structure around the target member/job node, where entity type embeddings and graph positional embeddings are introduced accordingly to model different entities and their heterogeneous relations. Meanwhile, a proximity-aware attention alignment strategy is designed to dynamically adjust the attention of the PLM on ego-graph node tokens in the prompt, such that the attention can be better aligned with job marketplace semantics. Extensive experiments at LinkedIn demonstrate the effectiveness of PLM4Job.
Leveraging Adaptive Implicit Representation Mapping for Ultra High-Resolution Image Segmentation
Jul 31, 2024Implicit representation mapping (IRM) can translate image features to any continuous resolution, showcasing its potent capability for ultra-high-resolution image segmentation refinement. Current IRM-based methods for refining ultra-high-resolution image segmentation often rely on CNN-based encoders to extract image features and apply a Shared Implicit Representation Mapping Function (SIRMF) to convert pixel-wise features into segmented results. Hence, these methods exhibit two crucial limitations. Firstly, the CNN-based encoder may not effectively capture long-distance information, resulting in a lack of global semantic information in the pixel-wise features. Secondly, SIRMF is shared across all samples, which limits its ability to generalize and handle diverse inputs. To address these limitations, we propose a novel approach that leverages the newly proposed Adaptive Implicit Representation Mapping (AIRM) for ultra-high-resolution Image Segmentation. Specifically, the proposed method comprises two components: (1) the Affinity Empowered Encoder (AEE), a robust feature extractor that leverages the benefits of the transformer architecture and semantic affinity to model long-distance features effectively, and (2) the Adaptive Implicit Representation Mapping Function (AIRMF), which adaptively translates pixel-wise features without neglecting the global semantic information, allowing for flexible and precise feature translation. We evaluated our method on the commonly used ultra-high-resolution segmentation refinement datasets, i.e., BIG and PASCAL VOC 2012. The extensive experiments demonstrate that our method outperforms competitors by a large margin. The code is provided in supplementary material.
Closing the gap between open-source and commercial large language models for medical evidence summarization
Jul 25, 2024



Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance in summarizing medical evidence. Utilizing a benchmark dataset, MedReview, consisting of 8,161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the fine-tuned LLMs obtained an increase of 9.89 in ROUGE-L (95% confidence interval: 8.94-10.81), 13.21 in METEOR score (95% confidence interval: 12.05-14.37), and 15.82 in CHRF score (95% confidence interval: 13.89-16.44). The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were also manifested in both human and GPT4-simulated evaluations. Our results can be applied to guide model selection for tasks demanding particular domain knowledge, such as medical evidence summarization.
SDoH-GPT: Using Large Language Models to Extract Social Determinants of Health (SDoH)
Jul 24, 2024



Extracting social determinants of health (SDoH) from unstructured medical notes depends heavily on labor-intensive annotations, which are typically task-specific, hampering reusability and limiting sharing. In this study we introduced SDoH-GPT, a simple and effective few-shot Large Language Model (LLM) method leveraging contrastive examples and concise instructions to extract SDoH without relying on extensive medical annotations or costly human intervention. It achieved tenfold and twentyfold reductions in time and cost respectively, and superior consistency with human annotators measured by Cohen's kappa of up to 0.92. The innovative combination of SDoH-GPT and XGBoost leverages the strengths of both, ensuring high accuracy and computational efficiency while consistently maintaining 0.90+ AUROC scores. Testing across three distinct datasets has confirmed its robustness and accuracy. This study highlights the potential of leveraging LLMs to revolutionize medical note classification, demonstrating their capability to achieve highly accurate classifications with significantly reduced time and cost.