 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgress and Prospects in 3D Generative AI: A Technical Overview including 3D human
Jan 05, 2024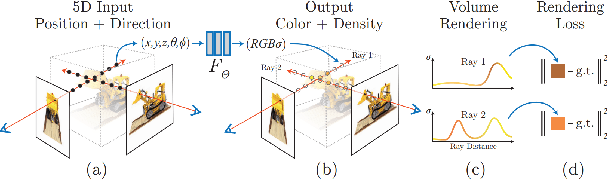


While AI-generated text and 2D images continue to expand its territory, 3D generation has gradually emerged as a trend that cannot be ignored. Since the year 2023 an abundant amount of research papers has emerged in the domain of 3D generation. This growth encompasses not just the creation of 3D objects, but also the rapid development of 3D character and motion generation. Several key factors contribute to this progress. The enhanced fidelity in stable diffusion, coupled with control methods that ensure multi-view consistency, and realistic human models like SMPL-X, contribute synergistically to the production of 3D models with remarkable consistency and near-realistic appearances. The advancements in neural network-based 3D storing and rendering models, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have accelerated the efficiency and realism of neural rendered models. Furthermore, the multimodality capabilities of large language models have enabled language inputs to transcend into human motion outputs. This paper aims to provide a comprehensive overview and summary of the relevant papers published mostly during the latter half year of 2023. It will begin by discussing the AI generated object models in 3D, followed by the generated 3D human models, and finally, the generated 3D human motions, culminating in a conclusive summary and a vision for the future.
General Object Foundation Model for Images and Videos at Scale
Dec 14, 2023



We present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEE accomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems. The model and code will be released at https://glee-vision.github.io .
Learning to Holistically Detect Bridges from Large-Size VHR Remote Sensing Imagery
Dec 05, 2023



Bridge detection in remote sensing images (RSIs) plays a crucial role in various applications, but it poses unique challenges compared to the detection of other objects. In RSIs, bridges exhibit considerable variations in terms of their spatial scales and aspect ratios. Therefore, to ensure the visibility and integrity of bridges, it is essential to perform holistic bridge detection in large-size very-high-resolution (VHR) RSIs. However, the lack of datasets with large-size VHR RSIs limits the deep learning algorithms' performance on bridge detection. Due to the limitation of GPU memory in tackling large-size images, deep learning-based object detection methods commonly adopt the cropping strategy, which inevitably results in label fragmentation and discontinuous prediction. To ameliorate the scarcity of datasets, this paper proposes a large-scale dataset named GLH-Bridge comprising 6,000 VHR RSIs sampled from diverse geographic locations across the globe. These images encompass a wide range of sizes, varying from 2,048*2,048 to 16,38*16,384 pixels, and collectively feature 59,737 bridges. Furthermore, we present an efficient network for holistic bridge detection (HBD-Net) in large-size RSIs. The HBD-Net presents a separate detector-based feature fusion (SDFF) architecture and is optimized via a shape-sensitive sample re-weighting (SSRW) strategy. Based on the proposed GLH-Bridge dataset, we establish a bridge detection benchmark including the OBB and HBB tasks, and validate the effectiveness of the proposed HBD-Net. Additionally, cross-dataset generalization experiments on two publicly available datasets illustrate the strong generalization capability of the GLH-Bridge dataset.
Dataset Condensation via Generative Model
Sep 14, 2023Dataset condensation aims to condense a large dataset with a lot of training samples into a small set. Previous methods usually condense the dataset into the pixels format. However, it suffers from slow optimization speed and large number of parameters to be optimized. When increasing image resolutions and classes, the number of learnable parameters grows accordingly, prohibiting condensation methods from scaling up to large datasets with diverse classes. Moreover, the relations among condensed samples have been neglected and hence the feature distribution of condensed samples is often not diverse. To solve these problems, we propose to condense the dataset into another format, a generative model. Such a novel format allows for the condensation of large datasets because the size of the generative model remains relatively stable as the number of classes or image resolution increases. Furthermore, an intra-class and an inter-class loss are proposed to model the relation of condensed samples. Intra-class loss aims to create more diverse samples for each class by pushing each sample away from the others of the same class. Meanwhile, inter-class loss increases the discriminability of samples by widening the gap between the centers of different classes. Extensive comparisons with state-of-the-art methods and our ablation studies confirm the effectiveness of our method and its individual component. To our best knowledge, we are the first to successfully conduct condensation on ImageNet-1k.
Free-ATM: Exploring Unsupervised Learning on Diffusion-Generated Images with Free Attention Masks
Aug 13, 2023Despite the rapid advancement of unsupervised learning in visual representation, it requires training on large-scale datasets that demand costly data collection, and pose additional challenges due to concerns regarding data privacy. Recently, synthetic images generated by text-to-image diffusion models, have shown great potential for benefiting image recognition. Although promising, there has been inadequate exploration dedicated to unsupervised learning on diffusion-generated images. To address this, we start by uncovering that diffusion models' cross-attention layers inherently provide annotation-free attention masks aligned with corresponding text inputs on generated images. We then investigate the problems of three prevalent unsupervised learning techniques ( i.e., contrastive learning, masked modeling, and vision-language pretraining) and introduce customized solutions by fully exploiting the aforementioned free attention masks. Our approach is validated through extensive experiments that show consistent improvements in baseline models across various downstream tasks, including image classification, detection, segmentation, and image-text retrieval. By utilizing our method, it is possible to close the performance gap between unsupervised pretraining on synthetic data and real-world scenarios.
Lowis3D: Language-Driven Open-World Instance-Level 3D Scene Understanding
Aug 01, 2023



Open-world instance-level scene understanding aims to locate and recognize unseen object categories that are not present in the annotated dataset. This task is challenging because the model needs to both localize novel 3D objects and infer their semantic categories. A key factor for the recent progress in 2D open-world perception is the availability of large-scale image-text pairs from the Internet, which cover a wide range of vocabulary concepts. However, this success is hard to replicate in 3D scenarios due to the scarcity of 3D-text pairs. To address this challenge, we propose to harness pre-trained vision-language (VL) foundation models that encode extensive knowledge from image-text pairs to generate captions for multi-view images of 3D scenes. This allows us to establish explicit associations between 3D shapes and semantic-rich captions. Moreover, to enhance the fine-grained visual-semantic representation learning from captions for object-level categorization, we design hierarchical point-caption association methods to learn semantic-aware embeddings that exploit the 3D geometry between 3D points and multi-view images. In addition, to tackle the localization challenge for novel classes in the open-world setting, we develop debiased instance localization, which involves training object grouping modules on unlabeled data using instance-level pseudo supervision. This significantly improves the generalization capabilities of instance grouping and thus the ability to accurately locate novel objects. We conduct extensive experiments on 3D semantic, instance, and panoptic segmentation tasks, covering indoor and outdoor scenes across three datasets. Our method outperforms baseline methods by a significant margin in semantic segmentation (e.g. 34.5%$\sim$65.3%), instance segmentation (e.g. 21.8%$\sim$54.0%) and panoptic segmentation (e.g. 14.7%$\sim$43.3%). Code will be available.
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Jul 09, 2023



Precise and controllable image editing is a challenging task that has attracted significant attention. Recently, DragGAN enables an interactive point-based image editing framework and achieves impressive editing results with pixel-level precision. However, since this method is based on generative adversarial networks (GAN), its generality is upper-bounded by the capacity of the pre-trained GAN models. In this work, we extend such an editing framework to diffusion models and propose DragDiffusion. By leveraging large-scale pretrained diffusion models, we greatly improve the applicability of interactive point-based editing in real world scenarios. While most existing diffusion-based image editing methods work on text embeddings, DragDiffusion optimizes the diffusion latent to achieve precise spatial control. Although diffusion models generate images in an iterative manner, we empirically show that optimizing diffusion latent at one single step suffices to generate coherent results, enabling DragDiffusion to complete high-quality editing efficiently. Extensive experiments across a wide range of challenging cases (e.g., multi-objects, diverse object categories, various styles, etc.) demonstrate the versatility and generality of DragDiffusion. Code: https://github.com/Yujun-Shi/DragDiffusion.
Intriguing Properties of Text-guided Diffusion Models
Jun 18, 2023



Text-guided diffusion models (TDMs) are widely applied but can fail unexpectedly. Common failures include: (i) natural-looking text prompts generating images with the wrong content, or (ii) different random samples of the latent variables that generate vastly different, and even unrelated, outputs despite being conditioned on the same text prompt. In this work, we aim to study and understand the failure modes of TDMs in more detail. To achieve this, we propose SAGE, an adversarial attack on TDMs that uses image classifiers as surrogate loss functions, to search over the discrete prompt space and the high-dimensional latent space of TDMs to automatically discover unexpected behaviors and failure cases in the image generation. We make several technical contributions to ensure that SAGE finds failure cases of the diffusion model, rather than the classifier, and verify this in a human study. Our study reveals four intriguing properties of TDMs that have not been systematically studied before: (1) We find a variety of natural text prompts producing images that fail to capture the semantics of input texts. We categorize these failures into ten distinct types based on the underlying causes. (2) We find samples in the latent space (which are not outliers) that lead to distorted images independent of the text prompt, suggesting that parts of the latent space are not well-structured. (3) We also find latent samples that lead to natural-looking images which are unrelated to the text prompt, implying a potential misalignment between the latent and prompt spaces. (4) By appending a single adversarial token embedding to an input prompt we can generate a variety of specified target objects, while only minimally affecting the CLIP score. This demonstrates the fragility of language representations and raises potential safety concerns.
InstMove: Instance Motion for Object-centric Video Segmentation
Mar 30, 2023Despite significant efforts, cutting-edge video segmentation methods still remain sensitive to occlusion and rapid movement, due to their reliance on the appearance of objects in the form of object embeddings, which are vulnerable to these disturbances. A common solution is to use optical flow to provide motion information, but essentially it only considers pixel-level motion, which still relies on appearance similarity and hence is often inaccurate under occlusion and fast movement. In this work, we study the instance-level motion and present InstMove, which stands for Instance Motion for Object-centric Video Segmentation. In comparison to pixel-wise motion, InstMove mainly relies on instance-level motion information that is free from image feature embeddings, and features physical interpretations, making it more accurate and robust toward occlusion and fast-moving objects. To better fit in with the video segmentation tasks, InstMove uses instance masks to model the physical presence of an object and learns the dynamic model through a memory network to predict its position and shape in the next frame. With only a few lines of code, InstMove can be integrated into current SOTA methods for three different video segmentation tasks and boost their performance. Specifically, we improve the previous arts by 1.5 AP on OVIS dataset, which features heavy occlusions, and 4.9 AP on YouTubeVIS-Long dataset, which mainly contains fast-moving objects. These results suggest that instance-level motion is robust and accurate, and hence serving as a powerful solution in complex scenarios for object-centric video segmentation.
SRFormer: Permuted Self-Attention for Single Image Super-Resolution
Mar 17, 2023Previous works have shown that increasing the window size for Transformer-based image super-resolution models (e.g., SwinIR) can significantly improve the model performance but the computation overhead is also considerable. In this paper, we present SRFormer, a simple but novel method that can enjoy the benefit of large window self-attention but introduces even less computational burden. The core of our SRFormer is the permuted self-attention (PSA), which strikes an appropriate balance between the channel and spatial information for self-attention. Our PSA is simple and can be easily applied to existing super-resolution networks based on window self-attention. Without any bells and whistles, we show that our SRFormer achieves a 33.86dB PSNR score on the Urban100 dataset, which is 0.46dB higher than that of SwinIR but uses fewer parameters and computations. We hope our simple and effective approach can serve as a useful tool for future research in super-resolution model design.