 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTR-DQ: Time-Rotation Diffusion Quantization
Mar 09, 2025Diffusion models have been widely adopted in image and video generation. However, their complex network architecture leads to high inference overhead for its generation process. Existing diffusion quantization methods primarily focus on the quantization of the model structure while ignoring the impact of time-steps variation during sampling. At the same time, most current approaches fail to account for significant activations that cannot be eliminated, resulting in substantial performance degradation after quantization. To address these issues, we propose Time-Rotation Diffusion Quantization (TR-DQ), a novel quantization method incorporating time-step and rotation-based optimization. TR-DQ first divides the sampling process based on time-steps and applies a rotation matrix to smooth activations and weights dynamically. For different time-steps, a dedicated hyperparameter is introduced for adaptive timing modeling, which enables dynamic quantization across different time steps. Additionally, we also explore the compression potential of Classifier-Free Guidance (CFG-wise) to establish a foundation for subsequent work. TR-DQ achieves state-of-the-art (SOTA) performance on image generation and video generation tasks and a 1.38-1.89x speedup and 1.97-2.58x memory reduction in inference compared to existing quantization methods.
FGS-SLAM: Fourier-based Gaussian Splatting for Real-time SLAM with Sparse and Dense Map Fusion
Mar 03, 2025



3D gaussian splatting has advanced simultaneous localization and mapping (SLAM) technology by enabling real-time positioning and the construction of high-fidelity maps. However, the uncertainty in gaussian position and initialization parameters introduces challenges, often requiring extensive iterative convergence and resulting in redundant or insufficient gaussian representations. To address this, we introduce a novel adaptive densification method based on Fourier frequency domain analysis to establish gaussian priors for rapid convergence. Additionally, we propose constructing independent and unified sparse and dense maps, where a sparse map supports efficient tracking via Generalized Iterative Closest Point (GICP) and a dense map creates high-fidelity visual representations. This is the first SLAM system leveraging frequency domain analysis to achieve high-quality gaussian mapping in real-time. Experimental results demonstrate an average frame rate of 36 FPS on Replica and TUM RGB-D datasets, achieving competitive accuracy in both localization and mapping.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025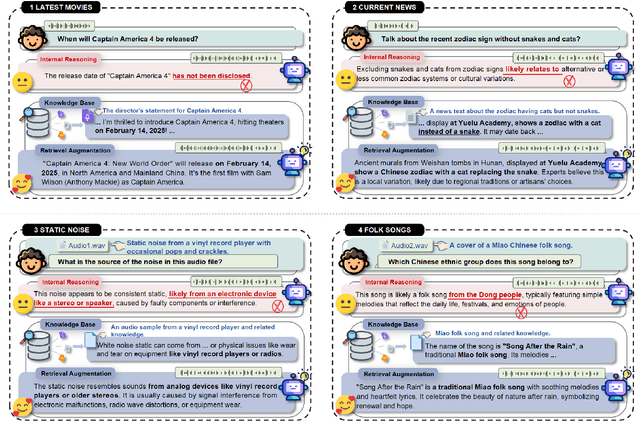
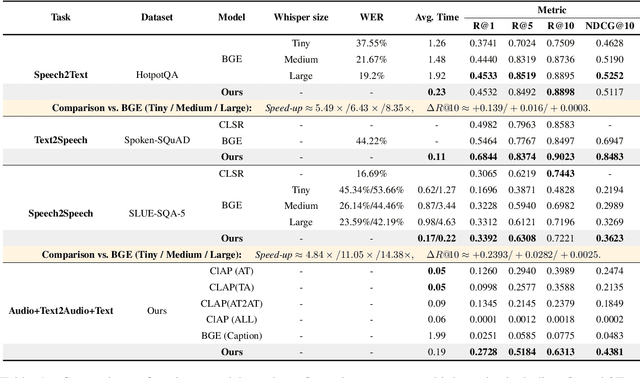
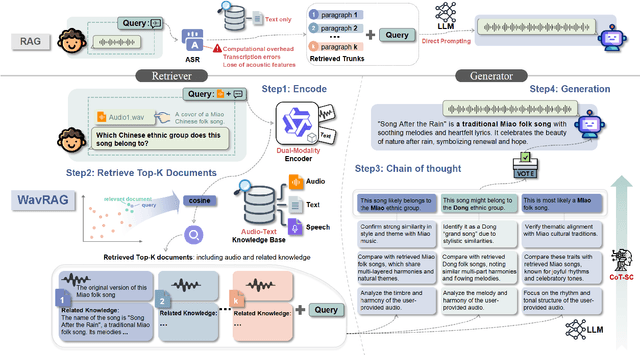
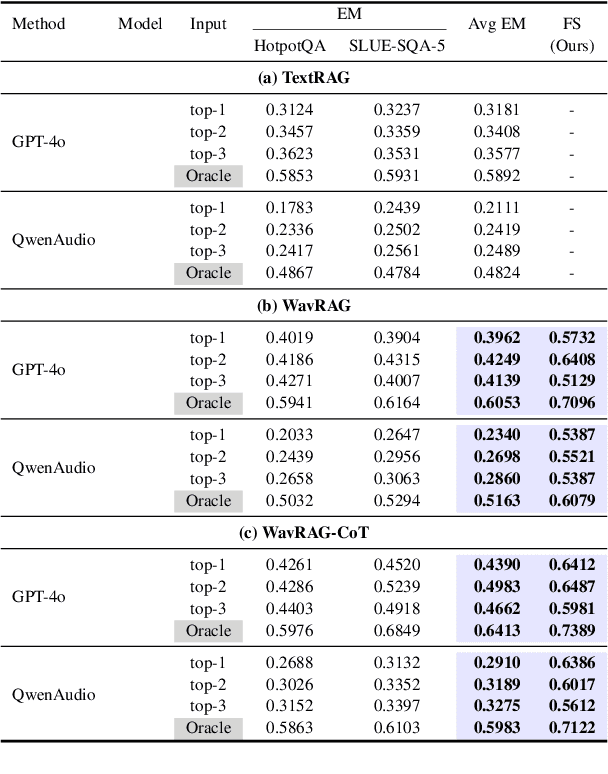
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
Active Advantage-Aligned Online Reinforcement Learning with Offline Data
Feb 11, 2025Online reinforcement learning (RL) enhances policies through direct interactions with the environment, but faces challenges related to sample efficiency. In contrast, offline RL leverages extensive pre-collected data to learn policies, but often produces suboptimal results due to limited data coverage. Recent efforts have sought to integrate offline and online RL in order to harness the advantages of both approaches. However, effectively combining online and offline RL remains challenging due to issues that include catastrophic forgetting, lack of robustness and sample efficiency. In an effort to address these challenges, we introduce A3 RL , a novel method that actively selects data from combined online and offline sources to optimize policy improvement. We provide theoretical guarantee that validates the effectiveness our active sampling strategy and conduct thorough empirical experiments showing that our method outperforms existing state-of-the-art online RL techniques that utilize offline data. Our code will be publicly available at: https://github.com/xuefeng-cs/A3RL.
DrugImproverGPT: A Large Language Model for Drug Optimization with Fine-Tuning via Structured Policy Optimization
Feb 11, 2025Finetuning a Large Language Model (LLM) is crucial for generating results towards specific objectives. This research delves into the realm of drug optimization and introduce a novel reinforcement learning algorithm to finetune a drug optimization LLM-based generative model, enhancing the original drug across target objectives, while retains the beneficial chemical properties of the original drug. This work is comprised of two primary components: (1) DrugImprover: A framework tailored for improving robustness and efficiency in drug optimization. It includes a LLM designed for drug optimization and a novel Structured Policy Optimization (SPO) algorithm, which is theoretically grounded. This algorithm offers a unique perspective for fine-tuning the LLM-based generative model by aligning the improvement of the generated molecule with the input molecule under desired objectives. (2) A dataset of 1 million compounds, each with OEDOCK docking scores on 5 human proteins associated with cancer cells and 24 binding sites from SARS-CoV-2 virus. We conduct a comprehensive evaluation of SPO and demonstrate its effectiveness in improving the original drug across target properties. Our code and dataset will be publicly available at: https://github.com/xuefeng-cs/DrugImproverGPT.
In-Context Meta LoRA Generation
Jan 30, 2025



Low-rank Adaptation (LoRA) has demonstrated remarkable capabilities for task specific fine-tuning. However, in scenarios that involve multiple tasks, training a separate LoRA model for each one results in considerable inefficiency in terms of storage and inference. Moreover, existing parameter generation methods fail to capture the correlations among these tasks, making multi-task LoRA parameter generation challenging. To address these limitations, we propose In-Context Meta LoRA (ICM-LoRA), a novel approach that efficiently achieves task-specific customization of large language models (LLMs). Specifically, we use training data from all tasks to train a tailored generator, Conditional Variational Autoencoder (CVAE). CVAE takes task descriptions as inputs and produces task-aware LoRA weights as outputs. These LoRA weights are then merged with LLMs to create task-specialized models without the need for additional fine-tuning. Furthermore, we utilize in-context meta-learning for knowledge enhancement and task mapping, to capture the relationship between tasks and parameter distributions. As a result, our method achieves more accurate LoRA parameter generation for diverse tasks using CVAE. ICM-LoRA enables more accurate LoRA parameter reconstruction than current parameter reconstruction methods and is useful for implementing task-specific enhancements of LoRA parameters. At the same time, our method occupies 283MB, only 1\% storage compared with the original LoRA.
Manga Generation via Layout-controllable Diffusion
Dec 26, 2024



Generating comics through text is widely studied. However, there are few studies on generating multi-panel Manga (Japanese comics) solely based on plain text. Japanese manga contains multiple panels on a single page, with characteristics such as coherence in storytelling, reasonable and diverse page layouts, consistency in characters, and semantic correspondence between panel drawings and panel scripts. Therefore, generating manga poses a significant challenge. This paper presents the manga generation task and constructs the Manga109Story dataset for studying manga generation solely from plain text. Additionally, we propose MangaDiffusion to facilitate the intra-panel and inter-panel information interaction during the manga generation process. The results show that our method particularly ensures the number of panels, reasonable and diverse page layouts. Based on our approach, there is potential to converting a large amount of textual stories into more engaging manga readings, leading to significant application prospects.
Large-Scale UWB Anchor Calibration and One-Shot Localization Using Gaussian Process
Dec 22, 2024



Ultra-wideband (UWB) is gaining popularity with devices like AirTags for precise home item localization but faces significant challenges when scaled to large environments like seaports. The main challenges are calibration and localization in obstructed conditions, which are common in logistics environments. Traditional calibration methods, dependent on line-of-sight (LoS), are slow, costly, and unreliable in seaports and warehouses, making large-scale localization a significant pain point in the industry. To overcome these challenges, we propose a UWB-LiDAR fusion-based calibration and one-shot localization framework. Our method uses Gaussian Processes to estimate anchor position from continuous-time LiDAR Inertial Odometry with sampled UWB ranges. This approach ensures accurate and reliable calibration with just one round of sampling in large-scale areas, I.e., 600x450 square meter. With the LoS issues, UWB-only localization can be problematic, even when anchor positions are known. We demonstrate that by applying a UWB-range filter, the search range for LiDAR loop closure descriptors is significantly reduced, improving both accuracy and speed. This concept can be applied to other loop closure detection methods, enabling cost-effective localization in large-scale warehouses and seaports. It significantly improves precision in challenging environments where UWB-only and LiDAR-Inertial methods fall short, as shown in the video \url{https://youtu.be/oY8jQKdM7lU }. We will open-source our datasets and calibration codes for community use.
Synchronized and Fine-Grained Head for Skeleton-Based Ambiguous Action Recognition
Dec 19, 2024



Skeleton-based action recognition using GCNs has achieved remarkable performance, but recognizing ambiguous actions, such as "waving" and "saluting", remains a significant challenge. Existing methods typically rely on a serial combination of GCNs and TCNs, where spatial and temporal features are extracted independently, leading to an unbalanced spatial-temporal information, which hinders accurate action recognition. Moreover, existing methods for ambiguous actions often overemphasize local details, resulting in the loss of crucial global context, which further complicates the task of differentiating ambiguous actions. To address these challenges, we propose a lightweight plug-and-play module called Synchronized and Fine-grained Head (SF-Head), inserted between GCN and TCN layers. SF-Head first conducts Synchronized Spatial-Temporal Extraction (SSTE) with a Feature Redundancy Loss (F-RL), ensuring a balanced interaction between the two types of features. It then performs Adaptive Cross-dimensional Feature Aggregation (AC-FA), with a Feature Consistency Loss (F-CL), which aligns the aggregated feature with their original spatial-temporal feature. This aggregation step effectively combines both global context and local details. Experimental results on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets demonstrate significant improvements in distinguishing ambiguous actions. Our code will be made available at https://github.com/HaoHuang2003/SFHead.
3DSceneEditor: Controllable 3D Scene Editing with Gaussian Splatting
Dec 02, 2024



The creation of 3D scenes has traditionally been both labor-intensive and costly, requiring designers to meticulously configure 3D assets and environments. Recent advancements in generative AI, including text-to-3D and image-to-3D methods, have dramatically reduced the complexity and cost of this process. However, current techniques for editing complex 3D scenes continue to rely on generally interactive multi-step, 2D-to-3D projection methods and diffusion-based techniques, which often lack precision in control and hamper real-time performance. In this work, we propose 3DSceneEditor, a fully 3D-based paradigm for real-time, precise editing of intricate 3D scenes using Gaussian Splatting. Unlike conventional methods, 3DSceneEditor operates through a streamlined 3D pipeline, enabling direct manipulation of Gaussians for efficient, high-quality edits based on input prompts.The proposed framework (i) integrates a pre-trained instance segmentation model for semantic labeling; (ii) employs a zero-shot grounding approach with CLIP to align target objects with user prompts; and (iii) applies scene modifications, such as object addition, repositioning, recoloring, replacing, and deletion directly on Gaussians. Extensive experimental results show that 3DSceneEditor achieves superior editing precision and speed with respect to current SOTA 3D scene editing approaches, establishing a new benchmark for efficient and interactive 3D scene customization.