 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Hierarchical Contrastive Learning with Decoupled Queries for Fine-grained Object Detection in Remote Sensing Images
Dec 30, 2025Fine-grained remote sensing datasets often use hierarchical label structures to differentiate objects in a coarse-to-fine manner, with each object annotated across multiple levels. However, embedding this semantic hierarchy into the representation learning space to improve fine-grained detection performance remains challenging. Previous studies have applied supervised contrastive learning at different hierarchical levels to group objects under the same parent class while distinguishing sibling subcategories. Nevertheless, they overlook two critical issues: (1) imbalanced data distribution across the label hierarchy causes high-frequency classes to dominate the learning process, and (2) learning semantic relationships among categories interferes with class-agnostic localization. To address these issues, we propose a balanced hierarchical contrastive loss combined with a decoupled learning strategy within the detection transformer (DETR) framework. The proposed loss introduces learnable class prototypes and equilibrates gradients contributed by different classes at each hierarchical level, ensuring that each hierarchical class contributes equally to the loss computation in every mini-batch. The decoupled strategy separates DETR's object queries into classification and localization sets, enabling task-specific feature extraction and optimization. Experiments on three fine-grained datasets with hierarchical annotations demonstrate that our method outperforms state-of-the-art approaches.
SUIT: Spatial-Spectral Union-Intersection Interaction Network for Hyperspectral Object Tracking
Aug 10, 2025



Hyperspectral videos (HSVs), with their inherent spatial-spectral-temporal structure, offer distinct advantages in challenging tracking scenarios such as cluttered backgrounds and small objects. However, existing methods primarily focus on spatial interactions between the template and search regions, often overlooking spectral interactions, leading to suboptimal performance. To address this issue, this paper investigates spectral interactions from both the architectural and training perspectives. At the architectural level, we first establish band-wise long-range spatial relationships between the template and search regions using Transformers. We then model spectral interactions using the inclusion-exclusion principle from set theory, treating them as the union of spatial interactions across all bands. This enables the effective integration of both shared and band-specific spatial cues. At the training level, we introduce a spectral loss to enforce material distribution alignment between the template and predicted regions, enhancing robustness to shape deformation and appearance variations. Extensive experiments demonstrate that our tracker achieves state-of-the-art tracking performance. The source code, trained models and results will be publicly available via https://github.com/bearshng/suit to support reproducibility.
RGB Pre-Training Enhanced Unobservable Feature Latent Diffusion Model for Spectral Reconstruction
Jul 17, 2025



Spectral reconstruction (SR) is a crucial problem in image processing that requires reconstructing hyperspectral images (HSIs) from the corresponding RGB images. A key difficulty in SR is estimating the unobservable feature, which encapsulates significant spectral information not captured by RGB imaging sensors. The solution lies in effectively constructing the spectral-spatial joint distribution conditioned on the RGB image to complement the unobservable feature. Since HSIs share a similar spatial structure with the corresponding RGB images, it is rational to capitalize on the rich spatial knowledge in RGB pre-trained models for spectral-spatial joint distribution learning. To this end, we extend the RGB pre-trained latent diffusion model (RGB-LDM) to an unobservable feature LDM (ULDM) for SR. As the RGB-LDM and its corresponding spatial autoencoder (SpaAE) already excel in spatial knowledge, the ULDM can focus on modeling spectral structure. Moreover, separating the unobservable feature from the HSI reduces the redundant spectral information and empowers the ULDM to learn the joint distribution in a compact latent space. Specifically, we propose a two-stage pipeline consisting of spectral structure representation learning and spectral-spatial joint distribution learning to transform the RGB-LDM into the ULDM. In the first stage, a spectral unobservable feature autoencoder (SpeUAE) is trained to extract and compress the unobservable feature into a 3D manifold aligned with RGB space. In the second stage, the spectral and spatial structures are sequentially encoded by the SpeUAE and the SpaAE, respectively. The ULDM is then acquired to model the distribution of the coded unobservable feature with guidance from the corresponding RGB images. Experimental results on SR and downstream relighting tasks demonstrate that our proposed method achieves state-of-the-art performance.
SSUMamba: Spatial-Spectral Selective State Space Model for Hyperspectral Image Denoising
May 06, 2024



Denoising hyperspectral images (HSIs) is a crucial preprocessing procedure due to the noise originating from intra-imaging mechanisms and environmental factors. Utilizing domain-specific knowledge of HSIs, such as spectral correlation, spatial self-similarity, and spatial-spectral correlation, is essential for deep learning-based denoising. Existing methods are often constrained by running time, space complexity, and computational complexity, employing strategies that explore these priors separately. While these strategies can avoid some redundant information, they inevitably overlook broader and more underlying long-range spatial-spectral information that positively impacts image restoration. This paper proposes a Spatial-Spectral Selective State Space Model-based U-shaped network, termed Spatial-Spectral U-Mamba (SSUMamba), for hyperspectral image denoising. We can obtain complete global spatial-spectral correlation within a module thanks to the linear space complexity in State Space Model (SSM) computations. We introduce a Spatial-Spectral Alternating Scan (SSAS) strategy for HSIs, which helps model the information flow in multiple directions in 3-D HSIs. Experimental results demonstrate that our method outperforms compared methods. The source code will be available at https://github.com/lronkitty/SSUMamba.
Hyperspectral Image Denoising via Spatial-Spectral Recurrent Transformer
Jan 09, 2024



Hyperspectral images (HSIs) often suffer from noise arising from both intra-imaging mechanisms and environmental factors. Leveraging domain knowledge specific to HSIs, such as global spectral correlation (GSC) and non-local spatial self-similarity (NSS), is crucial for effective denoising. Existing methods tend to independently utilize each of these knowledge components with multiple blocks, overlooking the inherent 3D nature of HSIs where domain knowledge is strongly interlinked, resulting in suboptimal performance. To address this challenge, this paper introduces a spatial-spectral recurrent transformer U-Net (SSRT-UNet) for HSI denoising. The proposed SSRT-UNet integrates NSS and GSC properties within a single SSRT block. This block consists of a spatial branch and a spectral branch. The spectral branch employs a combination of transformer and recurrent neural network to perform recurrent computations across bands, allowing for GSC exploitation beyond a fixed number of bands. Concurrently, the spatial branch encodes NSS for each band by sharing keys and values with the spectral branch under the guidance of GSC. This interaction between the two branches enables the joint utilization of NSS and GSC, avoiding their independent treatment. Experimental results demonstrate that our method outperforms several alternative approaches. The source code will be available at https://github.com/lronkitty/SSRT.
A Survey on Deep Learning-based Spatio-temporal Action Detection
Aug 03, 2023



Spatio-temporal action detection (STAD) aims to classify the actions present in a video and localize them in space and time. It has become a particularly active area of research in computer vision because of its explosively emerging real-world applications, such as autonomous driving, visual surveillance, entertainment, etc. Many efforts have been devoted in recent years to building a robust and effective framework for STAD. This paper provides a comprehensive review of the state-of-the-art deep learning-based methods for STAD. Firstly, a taxonomy is developed to organize these methods. Next, the linking algorithms, which aim to associate the frame- or clip-level detection results together to form action tubes, are reviewed. Then, the commonly used benchmark datasets and evaluation metrics are introduced, and the performance of state-of-the-art models is compared. At last, this paper is concluded, and a set of potential research directions of STAD are discussed.
Semantic Guided Level-Category Hybrid Prediction Network for Hierarchical Image Classification
Nov 22, 2022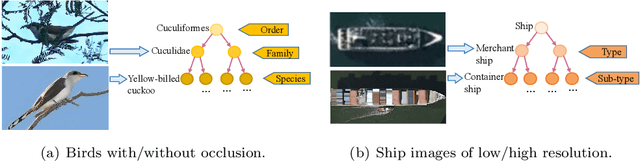
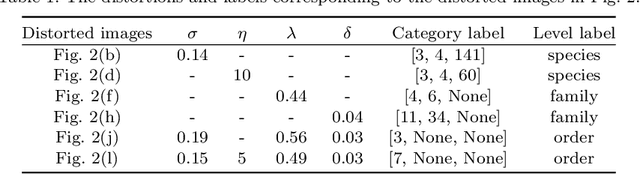

Hierarchical classification (HC) assigns each object with multiple labels organized into a hierarchical structure. The existing deep learning based HC methods usually predict an instance starting from the root node until a leaf node is reached. However, in the real world, images interfered by noise, occlusion, blur, or low resolution may not provide sufficient information for the classification at subordinate levels. To address this issue, we propose a novel semantic guided level-category hybrid prediction network (SGLCHPN) that can jointly perform the level and category prediction in an end-to-end manner. SGLCHPN comprises two modules: a visual transformer that extracts feature vectors from the input images, and a semantic guided cross-attention module that uses categories word embeddings as queries to guide learning category-specific representations. In order to evaluate the proposed method, we construct two new datasets in which images are at a broad range of quality and thus are labeled to different levels (depths) in the hierarchy according to their individual quality. Experimental results demonstrate the effectiveness of our proposed HC method.
Label Relation Graphs Enhanced Hierarchical Residual Network for Hierarchical Multi-Granularity Classification
Jan 11, 2022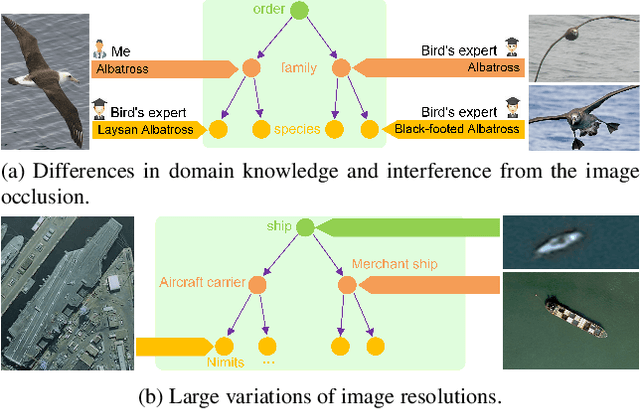

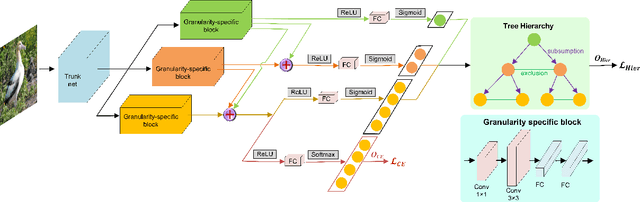
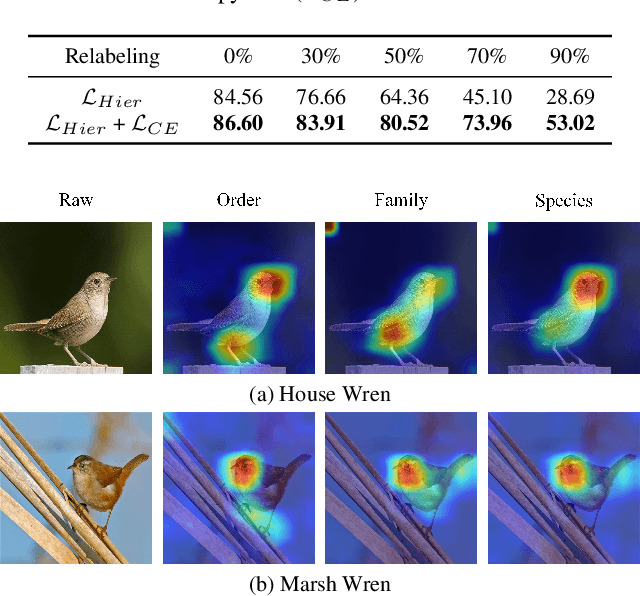
Hierarchical multi-granularity classification (HMC) assigns hierarchical multi-granularity labels to each object and focuses on encoding the label hierarchy, e.g., ["Albatross", "Laysan Albatross"] from coarse-to-fine levels. However, the definition of what is fine-grained is subjective, and the image quality may affect the identification. Thus, samples could be observed at any level of the hierarchy, e.g., ["Albatross"] or ["Albatross", "Laysan Albatross"], and examples discerned at coarse categories are often neglected in the conventional setting of HMC. In this paper, we study the HMC problem in which objects are labeled at any level of the hierarchy. The essential designs of the proposed method are derived from two motivations: (1) learning with objects labeled at various levels should transfer hierarchical knowledge between levels; (2) lower-level classes should inherit attributes related to upper-level superclasses. The proposed combinatorial loss maximizes the marginal probability of the observed ground truth label by aggregating information from related labels defined in the tree hierarchy. If the observed label is at the leaf level, the combinatorial loss further imposes the multi-class cross-entropy loss to increase the weight of fine-grained classification loss. Considering the hierarchical feature interaction, we propose a hierarchical residual network (HRN), in which granularity-specific features from parent levels acting as residual connections are added to features of children levels. Experiments on three commonly used datasets demonstrate the effectiveness of our approach compared to the state-of-the-art HMC approaches and fine-grained visual classification (FGVC) methods exploiting the label hierarchy.
Contrast-reconstruction Representation Learning for Self-supervised Skeleton-based Action Recognition
Nov 22, 2021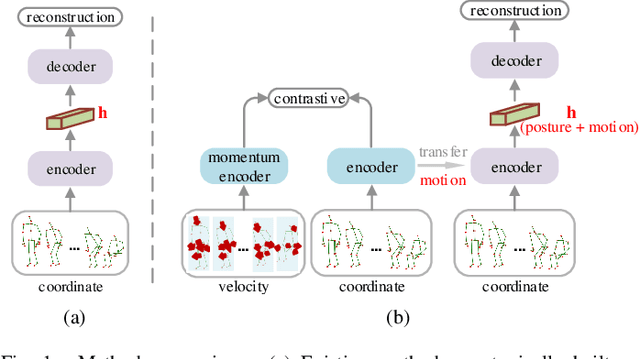
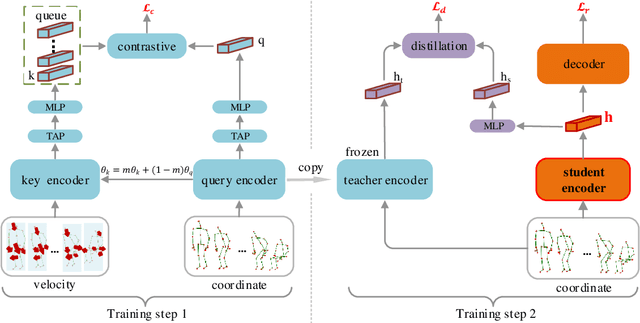
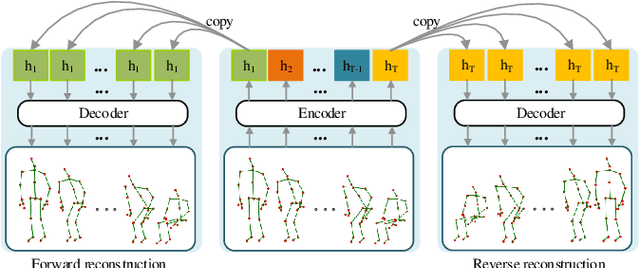
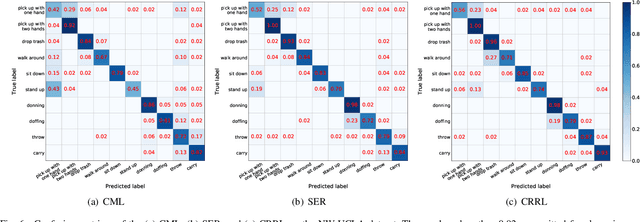
Skeleton-based action recognition is widely used in varied areas, e.g., surveillance and human-machine interaction. Existing models are mainly learned in a supervised manner, thus heavily depending on large-scale labeled data which could be infeasible when labels are prohibitively expensive. In this paper, we propose a novel Contrast-Reconstruction Representation Learning network (CRRL) that simultaneously captures postures and motion dynamics for unsupervised skeleton-based action recognition. It mainly consists of three parts: Sequence Reconstructor, Contrastive Motion Learner, and Information Fuser. The Sequence Reconstructor learns representation from skeleton coordinate sequence via reconstruction, thus the learned representation tends to focus on trivial postural coordinates and be hesitant in motion learning. To enhance the learning of motions, the Contrastive Motion Learner performs contrastive learning between the representations learned from coordinate sequence and additional velocity sequence, respectively. Finally, in the Information Fuser, we explore varied strategies to combine the Sequence Reconstructor and Contrastive Motion Learner, and propose to capture postures and motions simultaneously via a knowledge-distillation based fusion strategy that transfers the motion learning from the Contrastive Motion Learner to the Sequence Reconstructor. Experimental results on several benchmarks, i.e., NTU RGB+D 60, NTU RGB+D 120, CMU mocap, and NW-UCLA, demonstrate the promise of the proposed CRRL method by far outperforming state-of-the-art approaches.
RMNA: A Neighbor Aggregation-Based Knowledge Graph Representation Learning Model Using Rule Mining
Nov 04, 2021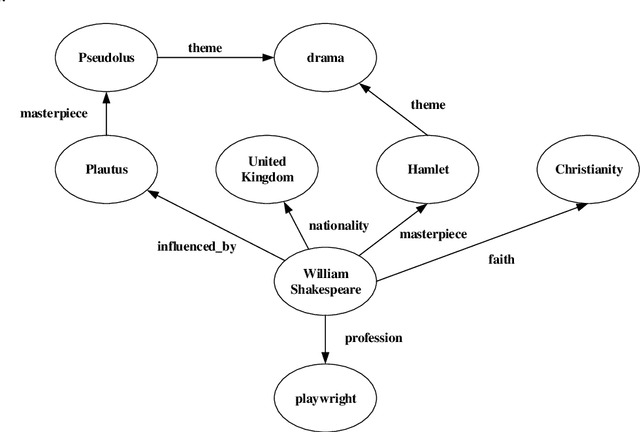
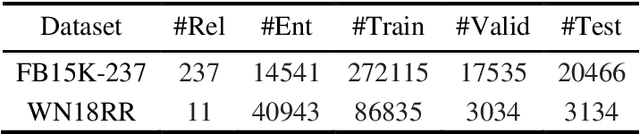
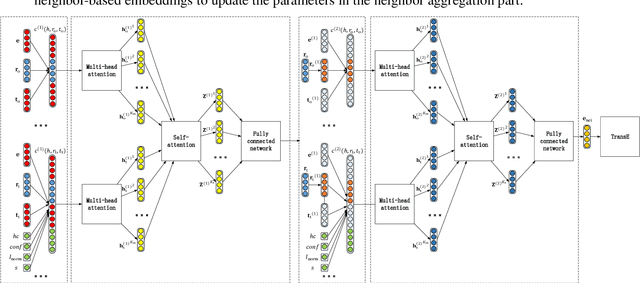
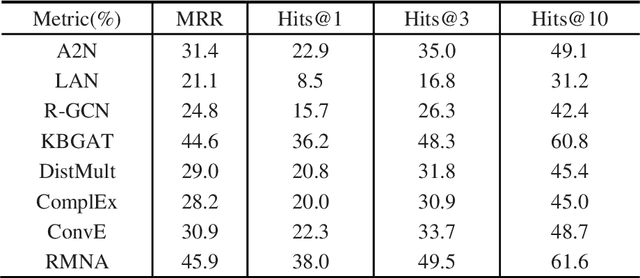
Although the state-of-the-art traditional representation learning (TRL) models show competitive performance on knowledge graph completion, there is no parameter sharing between the embeddings of entities, and the connections between entities are weak. Therefore, neighbor aggregation-based representation learning (NARL) models are proposed, which encode the information in the neighbors of an entity into its embeddings. However, existing NARL models either only utilize one-hop neighbors, ignoring the information in multi-hop neighbors, or utilize multi-hop neighbors by hierarchical neighbor aggregation, destroying the completeness of multi-hop neighbors. In this paper, we propose a NARL model named RMNA, which obtains and filters horn rules through a rule mining algorithm, and uses selected horn rules to transform valuable multi-hop neighbors into one-hop neighbors, therefore, the information in valuable multi-hop neighbors can be completely utilized by aggregating these one-hop neighbors. In experiments, we compare RMNA with the state-of-the-art TRL models and NARL models. The results show that RMNA has a competitive performance.