 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Unifying Understanding, Generation, and Editing via Vanilla Next-token Prediction
Mar 05, 2026In this work, we introduce Wallaroo, a simple autoregressive baseline that leverages next-token prediction to unify multi-modal understanding, image generation, and editing at the same time. Moreover, Wallaroo supports multi-resolution image input and output, as well as bilingual support for both Chinese and English. We decouple the visual encoding into separate pathways and apply a four-stage training strategy to reshape the model's capabilities. Experiments are conducted on various benchmarks where Wallaroo produces competitive performance or exceeds other unified models, suggesting the great potential of autoregressive models in unifying multi-modality understanding and generation. Our code is available at https://github.com/JiePKU/Wallaroo.
LongCat-Image Technical Report
Dec 08, 2025



We introduce LongCat-Image, a pioneering open-source and bilingual (Chinese-English) foundation model for image generation, designed to address core challenges in multilingual text rendering, photorealism, deployment efficiency, and developer accessibility prevalent in current leading models. 1) We achieve this through rigorous data curation strategies across the pre-training, mid-training, and SFT stages, complemented by the coordinated use of curated reward models during the RL phase. This strategy establishes the model as a new state-of-the-art (SOTA), delivering superior text-rendering capabilities and remarkable photorealism, and significantly enhancing aesthetic quality. 2) Notably, it sets a new industry standard for Chinese character rendering. By supporting even complex and rare characters, it outperforms both major open-source and commercial solutions in coverage, while also achieving superior accuracy. 3) The model achieves remarkable efficiency through its compact design. With a core diffusion model of only 6B parameters, it is significantly smaller than the nearly 20B or larger Mixture-of-Experts (MoE) architectures common in the field. This ensures minimal VRAM usage and rapid inference, significantly reducing deployment costs. Beyond generation, LongCat-Image also excels in image editing, achieving SOTA results on standard benchmarks with superior editing consistency compared to other open-source works. 4) To fully empower the community, we have established the most comprehensive open-source ecosystem to date. We are releasing not only multiple model versions for text-to-image and image editing, including checkpoints after mid-training and post-training stages, but also the entire toolchain of training procedure. We believe that the openness of LongCat-Image will provide robust support for developers and researchers, pushing the frontiers of visual content creation.
LinVT: Empower Your Image-level Large Language Model to Understand Videos
Dec 06, 2024Large Language Models (LLMs) have been widely used in various tasks, motivating us to develop an LLM-based assistant for videos. Instead of training from scratch, we propose a module to transform arbitrary well-trained image-based LLMs into video-LLMs (after being trained on video data). To better adapt image-LLMs for processing videos, we introduce two design principles: linear transformation to preserve the original visual-language alignment and representative information condensation from redundant video content. Guided by these principles, we propose a plug-and-play Linear Video Tokenizer(LinVT), which enables existing image-LLMs to understand videos. We benchmark LinVT with six recent visual LLMs: Aquila, Blip-3, InternVL2, Mipha, Molmo and Qwen2-VL, showcasing the high compatibility of LinVT. LinVT-based LLMs achieve state-of-the-art performance across various video benchmarks, illustrating the effectiveness of LinVT in multi-modal video understanding.
Video Temporal Relationship Mining for Data-Efficient Person Re-identification
Oct 01, 2021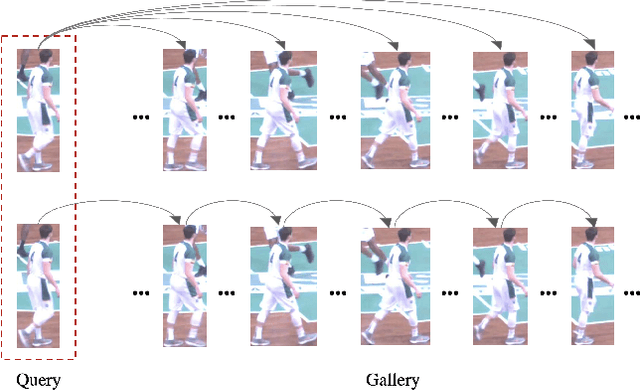
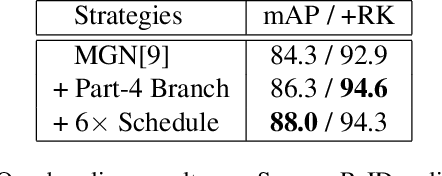
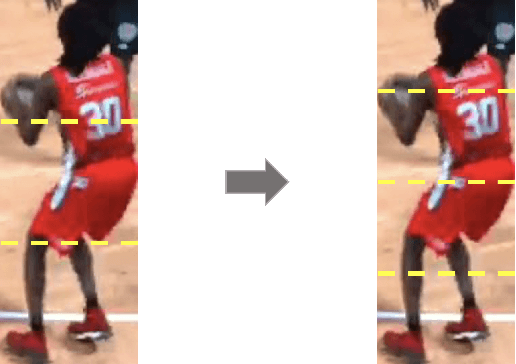
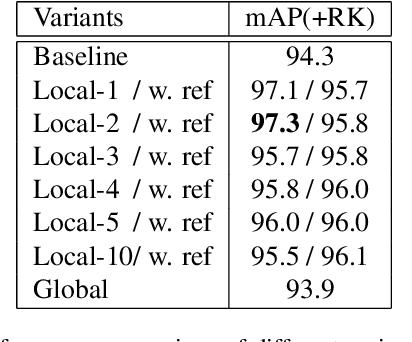
This paper is a technical report to our submission to the ICCV 2021 VIPriors Re-identification Challenge. In order to make full use of the visual inductive priors of the data, we treat the query and gallery images of the same identity as continuous frames in a video sequence. And we propose one novel post-processing strategy for video temporal relationship mining, which not only calculates the distance matrix between query and gallery images, but also the matrix between gallery images. The initial query image is used to retrieve the most similar image from the gallery, then the retrieved image is treated as a new query to retrieve its most similar image from the gallery. By iteratively searching for the closest image, we can achieve accurate image retrieval and finally obtain a robust retrieval sequence.