 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian-Bernoulli RBMs Without Tears
Oct 19, 2022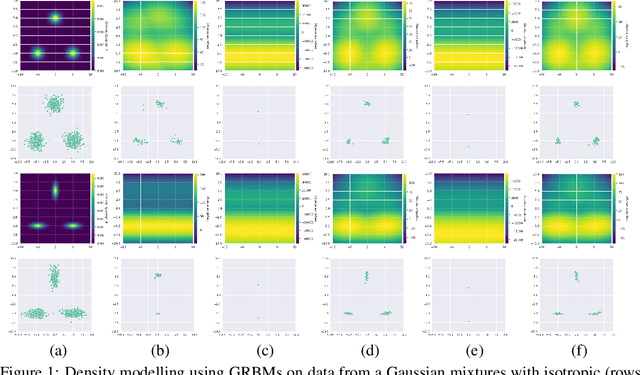

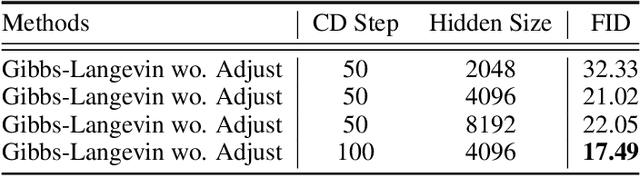
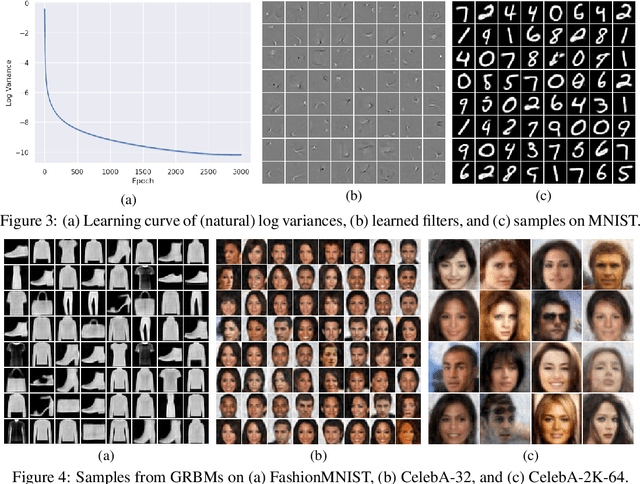
We revisit the challenging problem of training Gaussian-Bernoulli restricted Boltzmann machines (GRBMs), introducing two innovations. We propose a novel Gibbs-Langevin sampling algorithm that outperforms existing methods like Gibbs sampling. We propose a modified contrastive divergence (CD) algorithm so that one can generate images with GRBMs starting from noise. This enables direct comparison of GRBMs with deep generative models, improving evaluation protocols in the RBM literature. Moreover, we show that modified CD and gradient clipping are enough to robustly train GRBMs with large learning rates, thus removing the necessity of various tricks in the literature. Experiments on Gaussian Mixtures, MNIST, FashionMNIST, and CelebA show GRBMs can generate good samples, despite their single-hidden-layer architecture. Our code is released at: \url{https://github.com/lrjconan/GRBM}.
Improving Dense Contrastive Learning with Dense Negative Pairs
Oct 11, 2022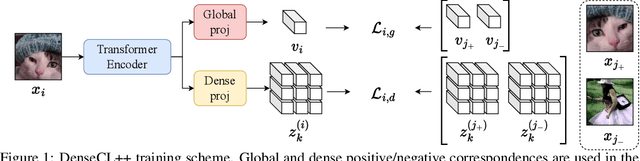
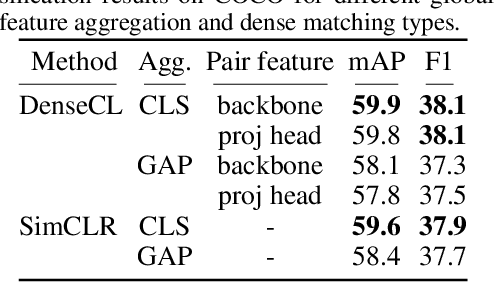
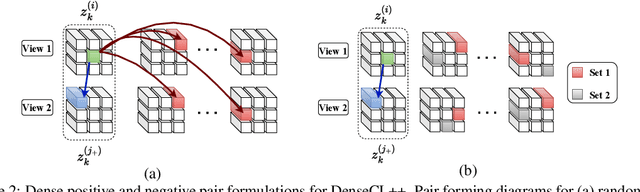
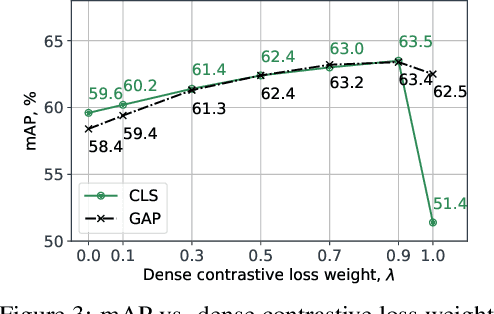
Many contrastive representation learning methods learn a single global representation of an entire image. However, dense contrastive representation learning methods such as DenseCL [19] can learn better representations for tasks requiring stronger spatial localization of features, such as multi-label classification, detection, and segmentation. In this work, we study how to improve the quality of the representations learned by DenseCL by modifying the training scheme and objective function, and propose DenseCL++. We also conduct several ablation studies to better understand the effects of: (i) various techniques to form dense negative pairs among augmentations of different images, (ii) cross-view dense negative and positive pairs, and (iii) an auxiliary reconstruction task. Our results show 3.5% and 4% mAP improvement over SimCLR [3] and DenseCL in COCO multi-label classification. In COCO and VOC segmentation tasks, we achieve 1.8% and 0.7% mIoU improvements over SimCLR, respectively.
Scaling Forward Gradient With Local Losses
Oct 07, 2022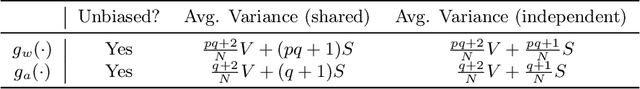

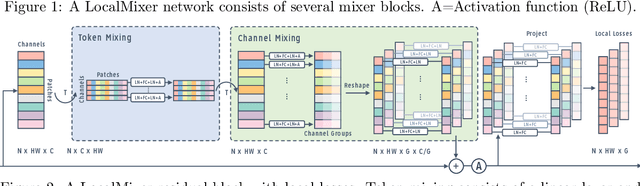
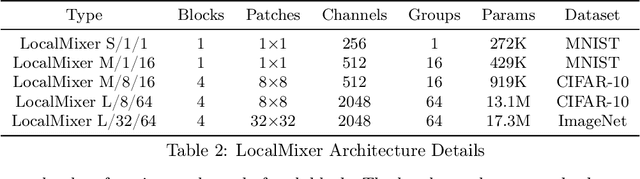
Forward gradient learning computes a noisy directional gradient and is a biologically plausible alternative to backprop for learning deep neural networks. However, the standard forward gradient algorithm, when applied naively, suffers from high variance when the number of parameters to be learned is large. In this paper, we propose a series of architectural and algorithmic modifications that together make forward gradient learning practical for standard deep learning benchmark tasks. We show that it is possible to substantially reduce the variance of the forward gradient estimator by applying perturbations to activations rather than weights. We further improve the scalability of forward gradient by introducing a large number of local greedy loss functions, each of which involves only a small number of learnable parameters, and a new MLPMixer-inspired architecture, LocalMixer, that is more suitable for local learning. Our approach matches backprop on MNIST and CIFAR-10 and significantly outperforms previously proposed backprop-free algorithms on ImageNet.
Patching open-vocabulary models by interpolating weights
Aug 10, 2022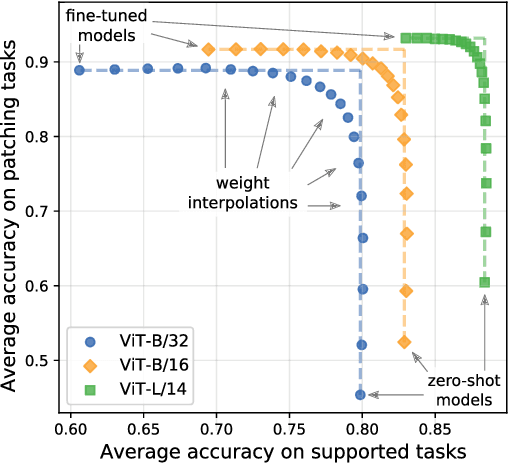

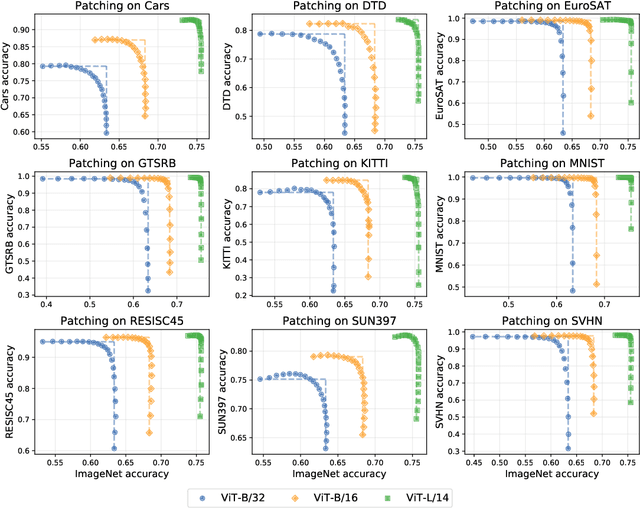

Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
A Study on Self-Supervised Object Detection Pretraining
Jul 09, 2022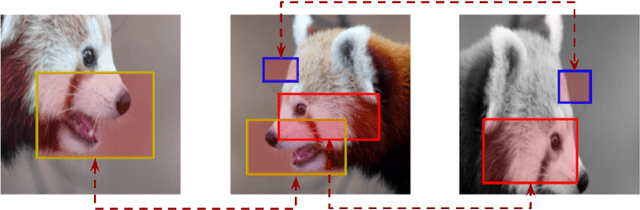
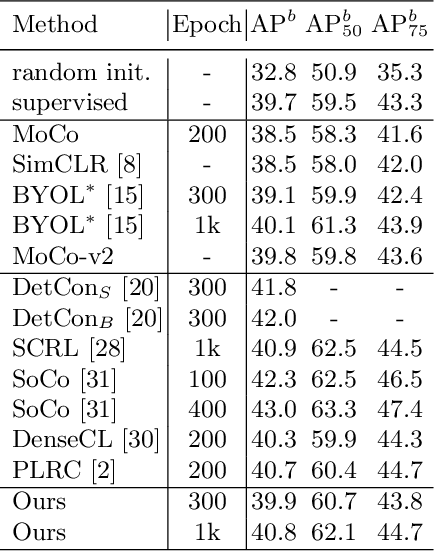
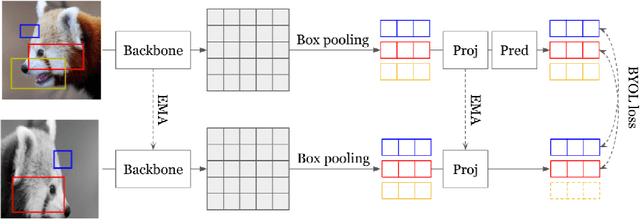
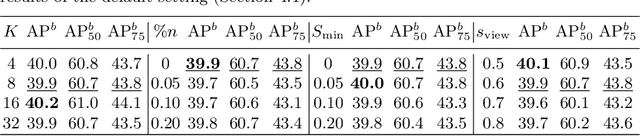
In this work, we study different approaches to self-supervised pretraining of object detection models. We first design a general framework to learn a spatially consistent dense representation from an image, by randomly sampling and projecting boxes to each augmented view and maximizing the similarity between corresponding box features. We study existing design choices in the literature, such as box generation, feature extraction strategies, and using multiple views inspired by its success on instance-level image representation learning techniques. Our results suggest that the method is robust to different choices of hyperparameters, and using multiple views is not as effective as shown for instance-level image representation learning. We also design two auxiliary tasks to predict boxes in one view from their features in the other view, by (1) predicting boxes from the sampled set by using a contrastive loss, and (2) predicting box coordinates using a transformer, which potentially benefits downstream object detection tasks. We found that these tasks do not lead to better object detection performance when finetuning the pretrained model on labeled data.
Decoder Denoising Pretraining for Semantic Segmentation
May 23, 2022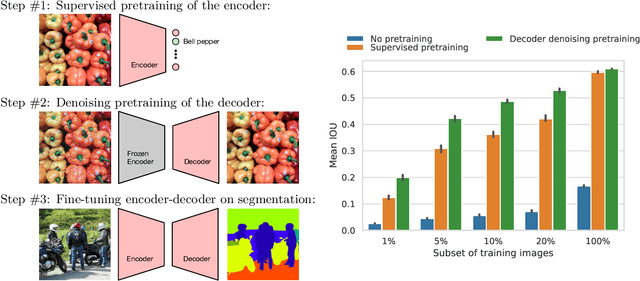
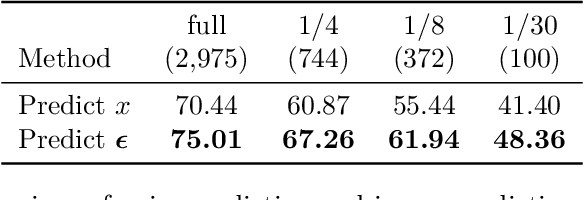
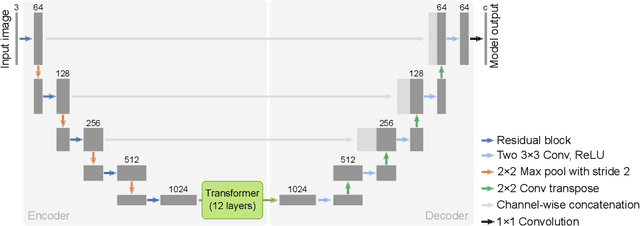
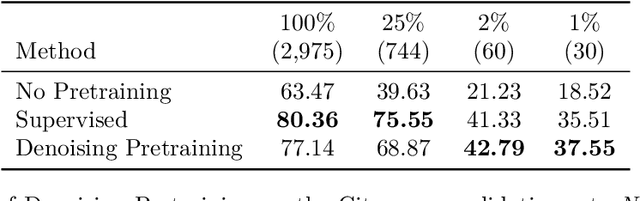
Semantic segmentation labels are expensive and time consuming to acquire. Hence, pretraining is commonly used to improve the label-efficiency of segmentation models. Typically, the encoder of a segmentation model is pretrained as a classifier and the decoder is randomly initialized. Here, we argue that random initialization of the decoder can be suboptimal, especially when few labeled examples are available. We propose a decoder pretraining approach based on denoising, which can be combined with supervised pretraining of the encoder. We find that decoder denoising pretraining on the ImageNet dataset strongly outperforms encoder-only supervised pretraining. Despite its simplicity, decoder denoising pretraining achieves state-of-the-art results on label-efficient semantic segmentation and offers considerable gains on the Cityscapes, Pascal Context, and ADE20K datasets.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022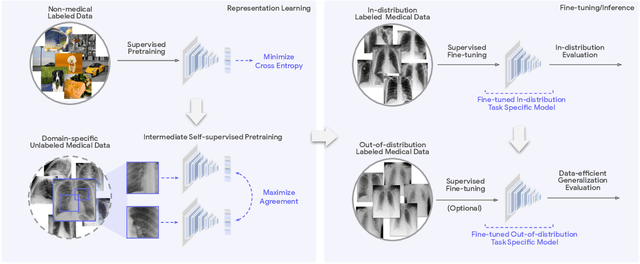
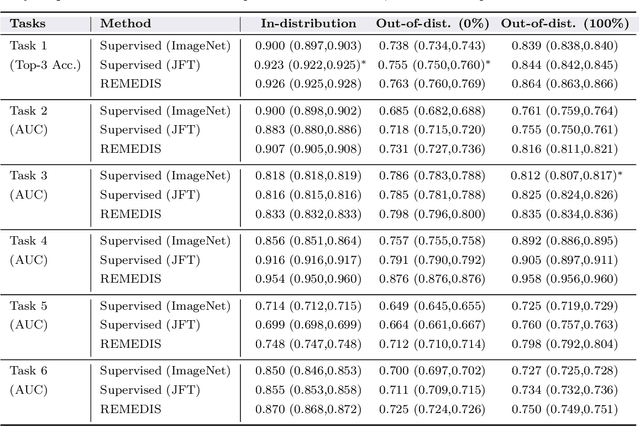
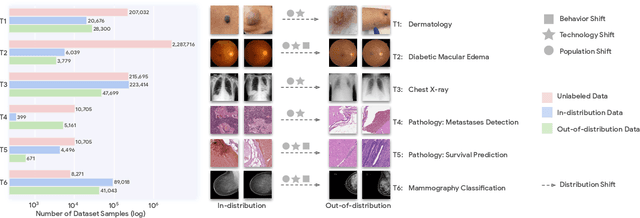

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Mar 10, 2022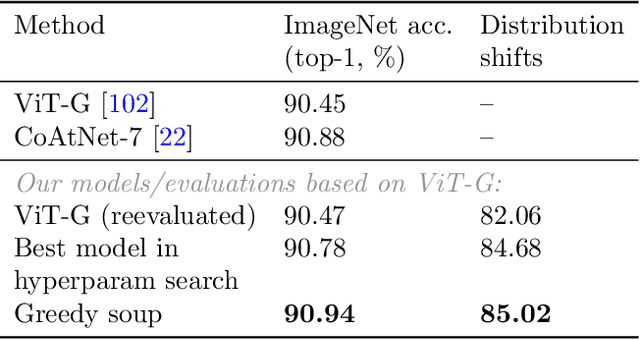
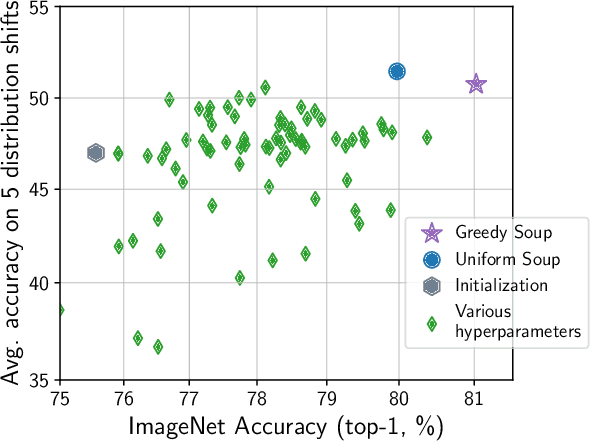

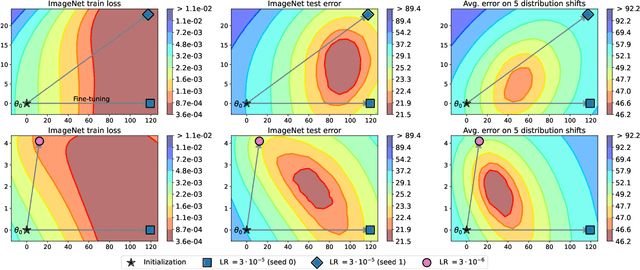
The conventional recipe for maximizing model accuracy is to (1) train multiple models with various hyperparameters and (2) pick the individual model which performs best on a held-out validation set, discarding the remainder. In this paper, we revisit the second step of this procedure in the context of fine-tuning large pre-trained models, where fine-tuned models often appear to lie in a single low error basin. We show that averaging the weights of multiple models fine-tuned with different hyperparameter configurations often improves accuracy and robustness. Unlike a conventional ensemble, we may average many models without incurring any additional inference or memory costs -- we call the results "model soups." When fine-tuning large pre-trained models such as CLIP, ALIGN, and a ViT-G pre-trained on JFT, our soup recipe provides significant improvements over the best model in a hyperparameter sweep on ImageNet. As a highlight, the resulting ViT-G model attains 90.94% top-1 accuracy on ImageNet, a new state of the art. Furthermore, we show that the model soup approach extends to multiple image classification and natural language processing tasks, improves out-of-distribution performance, and improves zero-shot performance on new downstream tasks. Finally, we analytically relate the performance similarity of weight-averaging and logit-ensembling to flatness of the loss and confidence of the predictions, and validate this relation empirically.
On the Origins of the Block Structure Phenomenon in Neural Network Representations
Feb 15, 2022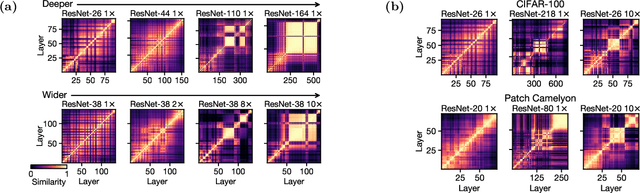

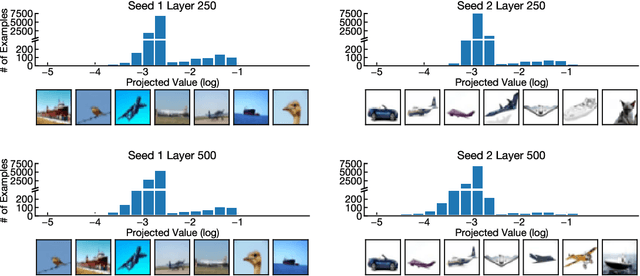

Recent work has uncovered a striking phenomenon in large-capacity neural networks: they contain blocks of contiguous hidden layers with highly similar representations. This block structure has two seemingly contradictory properties: on the one hand, its constituent layers exhibit highly similar dominant first principal components (PCs), but on the other hand, their representations, and their common first PC, are highly dissimilar across different random seeds. Our work seeks to reconcile these discrepant properties by investigating the origin of the block structure in relation to the data and training methods. By analyzing properties of the dominant PCs, we find that the block structure arises from dominant datapoints - a small group of examples that share similar image statistics (e.g. background color). However, the set of dominant datapoints, and the precise shared image statistic, can vary across random seeds. Thus, the block structure reflects meaningful dataset statistics, but is simultaneously unique to each model. Through studying hidden layer activations and creating synthetic datapoints, we demonstrate that these simple image statistics dominate the representational geometry of the layers inside the block structure. We explore how the phenomenon evolves through training, finding that the block structure takes shape early in training, but the underlying representations and the corresponding dominant datapoints continue to change substantially. Finally, we study the interplay between the block structure and different training mechanisms, introducing a targeted intervention to eliminate the block structure, as well as examining the effects of pretraining and Shake-Shake regularization.
Meta-Learning to Improve Pre-Training
Nov 02, 2021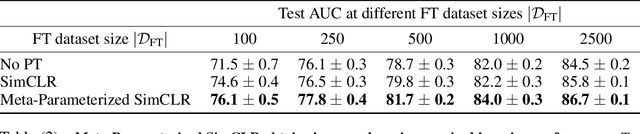

Pre-training (PT) followed by fine-tuning (FT) is an effective method for training neural networks, and has led to significant performance improvements in many domains. PT can incorporate various design choices such as task and data reweighting strategies, augmentation policies, and noise models, all of which can significantly impact the quality of representations learned. The hyperparameters introduced by these strategies therefore must be tuned appropriately. However, setting the values of these hyperparameters is challenging. Most existing methods either struggle to scale to high dimensions, are too slow and memory-intensive, or cannot be directly applied to the two-stage PT and FT learning process. In this work, we propose an efficient, gradient-based algorithm to meta-learn PT hyperparameters. We formalize the PT hyperparameter optimization problem and propose a novel method to obtain PT hyperparameter gradients by combining implicit differentiation and backpropagation through unrolled optimization. We demonstrate that our method improves predictive performance on two real-world domains. First, we optimize high-dimensional task weighting hyperparameters for multitask pre-training on protein-protein interaction graphs and improve AUROC by up to 3.9%. Second, we optimize a data augmentation neural network for self-supervised PT with SimCLR on electrocardiography data and improve AUROC by up to 1.9%.