 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Text-to-Speech from Continuous Text Streams
Oct 01, 2024



Existing zero-shot text-to-speech (TTS) systems are typically designed to process complete sentences and are constrained by the maximum duration for which they have been trained. However, in many streaming applications, texts arrive continuously in short chunks, necessitating instant responses from the system. We identify the essential capabilities required for chunk-level streaming and introduce LiveSpeech 2, a stream-aware model that supports infinitely long speech generation, text-audio stream synchronization, and seamless transitions between short speech chunks. To achieve these, we propose (1) adopting Mamba, a class of sequence modeling distinguished by linear-time decoding, which is augmented by cross-attention mechanisms for conditioning, (2) utilizing rotary positional embeddings in the computation of cross-attention, enabling the model to process an infinite text stream by sliding a window, and (3) decoding with semantic guidance, a technique that aligns speech with the transcript during inference with minimal overhead. Experimental results demonstrate that our models are competitive with state-of-the-art language model-based zero-shot TTS models, while also providing flexibility to support a wide range of streaming scenarios.
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Jun 05, 2024



Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
SiNGR: Brain Tumor Segmentation via Signed Normalized Geodesic Transform Regression
May 27, 2024



One of the primary challenges in brain tumor segmentation arises from the uncertainty of voxels close to tumor boundaries. However, the conventional process of generating ground truth segmentation masks fails to treat such uncertainties properly. Those ``hard labels'' with 0s and 1s conceptually influenced the majority of prior studies on brain image segmentation. As a result, tumor segmentation is often solved through voxel classification. In this work, we instead view this problem as a voxel-level regression, where the ground truth represents a certainty mapping from any pixel based on the distance to tumor border. We propose a novel ground truth label transformation, which is based on a signed geodesic transform, to capture the uncertainty in brain tumors' vicinity, while maintaining a margin between positive and negative samples. We combine this idea with a Focal-like regression L1-loss that enables effective regression learning in high-dimensional output space by appropriately weighting voxels according to their difficulty. We thoroughly conduct an experimental evaluation to validate the components of our proposed method, compare it to a diverse array of state-of-the-art segmentation models, and show that it is architecture-agnostic. The code of our method is made publicly available (\url{https://github.com/Oulu-IMEDS/SiNGR/}).
Image-level Regression for Uncertainty-aware Retinal Image Segmentation
May 27, 2024



Accurate retinal vessel segmentation is a crucial step in the quantitative assessment of retinal vasculature, which is needed for the early detection of retinal diseases and other conditions. Numerous studies have been conducted to tackle the problem of segmenting vessels automatically using a pixel-wise classification approach. The common practice of creating ground truth labels is to categorize pixels as foreground and background. This approach is, however, biased, and it ignores the uncertainty of a human annotator when it comes to annotating e.g. thin vessels. In this work, we propose a simple and effective method that casts the retinal image segmentation task as an image-level regression. For this purpose, we first introduce a novel Segmentation Annotation Uncertainty-Aware (SAUNA) transform, which adds pixel uncertainty to the ground truth using the pixel's closeness to the annotation boundary and vessel thickness. To train our model with soft labels, we generalize the earlier proposed Jaccard metric loss to arbitrary hypercubes, which is a second contribution of this work. The proposed SAUNA transform and the new theoretical results allow us to directly train a standard U-Net-like architecture at the image level, outperforming all recently published methods. We conduct thorough experiments and compare our method to a diverse set of baselines across 5 retinal image datasets. Our implementation is available at \url{https://github.com/Oulu-IMEDS/SAUNA}.
uaMix-MAE: Efficient Tuning of Pretrained Audio Transformers with Unsupervised Audio Mixtures
Mar 14, 2024Masked Autoencoders (MAEs) learn rich low-level representations from unlabeled data but require substantial labeled data to effectively adapt to downstream tasks. Conversely, Instance Discrimination (ID) emphasizes high-level semantics, offering a potential solution to alleviate annotation requirements in MAEs. Although combining these two approaches can address downstream tasks with limited labeled data, naively integrating ID into MAEs leads to extended training times and high computational costs. To address this challenge, we introduce uaMix-MAE, an efficient ID tuning strategy that leverages unsupervised audio mixtures. Utilizing contrastive tuning, uaMix-MAE aligns the representations of pretrained MAEs, thereby facilitating effective adaptation to task-specific semantics. To optimize the model with small amounts of unlabeled data, we propose an audio mixing technique that manipulates audio samples in both input and virtual label spaces. Experiments in low/few-shot settings demonstrate that \modelname achieves 4-6% accuracy improvements over various benchmarks when tuned with limited unlabeled data, such as AudioSet-20K. Code is available at https://github.com/PLAN-Lab/uamix-MAE
Optimality in Mean Estimation: Beyond Worst-Case, Beyond Sub-Gaussian, and Beyond $1+α$ Moments
Nov 21, 2023There is growing interest in improving our algorithmic understanding of fundamental statistical problems such as mean estimation, driven by the goal of understanding the limits of what we can extract from valuable data. The state of the art results for mean estimation in $\mathbb{R}$ are 1) the optimal sub-Gaussian mean estimator by [LV22], with the tight sub-Gaussian constant for all distributions with finite but unknown variance, and 2) the analysis of the median-of-means algorithm by [BCL13] and a lower bound by [DLLO16], characterizing the big-O optimal errors for distributions for which only a $1+\alpha$ moment exists for $\alpha \in (0,1)$. Both results, however, are optimal only in the worst case. We initiate the fine-grained study of the mean estimation problem: Can algorithms leverage useful features of the input distribution to beat the sub-Gaussian rate, without explicit knowledge of such features? We resolve this question with an unexpectedly nuanced answer: "Yes in limited regimes, but in general no". For any distribution $p$ with a finite mean, we construct a distribution $q$ whose mean is well-separated from $p$'s, yet $p$ and $q$ are not distinguishable with high probability, and $q$ further preserves $p$'s moments up to constants. The main consequence is that no reasonable estimator can asymptotically achieve better than the sub-Gaussian error rate for any distribution, matching the worst-case result of [LV22]. More generally, we introduce a new definitional framework to analyze the fine-grained optimality of algorithms, which we call "neighborhood optimality", interpolating between the unattainably strong "instance optimality" and the trivially weak "admissibility" definitions. Applying the new framework, we show that median-of-means is neighborhood optimal, up to constant factors. It is open to find a neighborhood-optimal estimator without constant factor slackness.
Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
Sep 19, 2023



Diffusion models power a vast majority of text-to-audio (TTA) generation methods. Unfortunately, these models suffer from slow inference speed due to iterative queries to the underlying denoising network, thus unsuitable for scenarios with inference time or computational constraints. This work modifies the recently proposed consistency distillation framework to train TTA models that require only a single neural network query. In addition to incorporating classifier-free guidance into the distillation process, we leverage the availability of generated audio during distillation training to fine-tune the consistency TTA model with novel loss functions in the audio space, such as the CLAP score. Our objective and subjective evaluation results on the AudioCaps dataset show that consistency models retain diffusion models' high generation quality and diversity while reducing the number of queries by a factor of 400.
A Multi-scale Graph Signature for Persistence Diagrams based on Return Probabilities of Random Walks
Sep 28, 2022



Persistence diagrams (PDs), often characterized as sets of death and birth of homology class, have been known for providing a topological representation of a graph structure, which is often useful in machine learning tasks. Prior works rely on a single graph signature to construct PDs. In this paper, we explore the use of a family of multi-scale graph signatures to enhance the robustness of topological features. We propose a deep learning architecture to handle this set input. Experiments on benchmark graph classification datasets demonstrate that our proposed architecture outperforms other persistent homology-based methods and achieves competitive performance compared to state-of-the-art methods using graph neural networks. In addition, our approach can be easily applied to large size of input graphs as it does not suffer from limited scalability which can be an issue for graph kernel methods.
A Study on Self-Supervised Object Detection Pretraining
Jul 09, 2022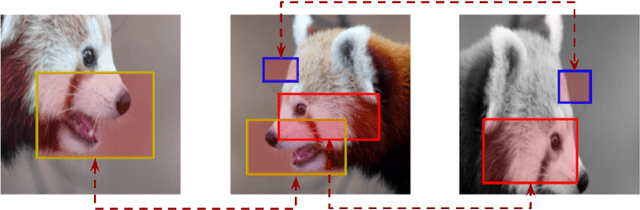
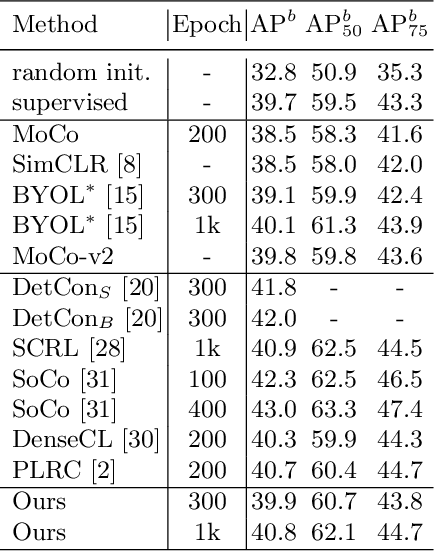
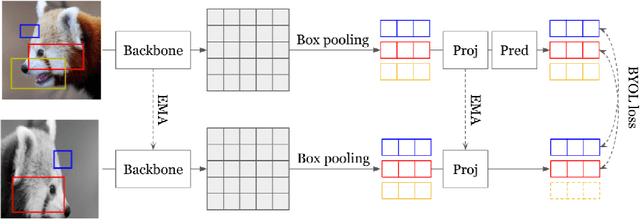
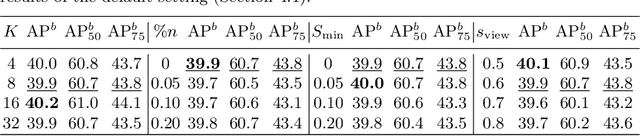
In this work, we study different approaches to self-supervised pretraining of object detection models. We first design a general framework to learn a spatially consistent dense representation from an image, by randomly sampling and projecting boxes to each augmented view and maximizing the similarity between corresponding box features. We study existing design choices in the literature, such as box generation, feature extraction strategies, and using multiple views inspired by its success on instance-level image representation learning techniques. Our results suggest that the method is robust to different choices of hyperparameters, and using multiple views is not as effective as shown for instance-level image representation learning. We also design two auxiliary tasks to predict boxes in one view from their features in the other view, by (1) predicting boxes from the sampled set by using a contrastive loss, and (2) predicting box coordinates using a transformer, which potentially benefits downstream object detection tasks. We found that these tasks do not lead to better object detection performance when finetuning the pretrained model on labeled data.
Training Robust Zero-Shot Voice Conversion Models with Self-supervised Features
Dec 08, 2021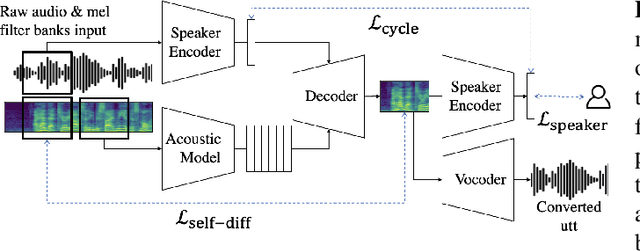
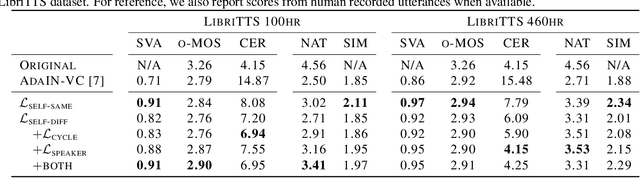
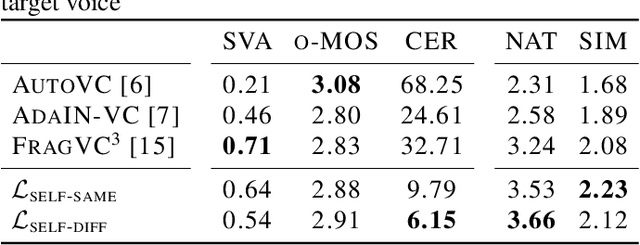
Unsupervised Zero-Shot Voice Conversion (VC) aims to modify the speaker characteristic of an utterance to match an unseen target speaker without relying on parallel training data. Recently, self-supervised learning of speech representation has been shown to produce useful linguistic units without using transcripts, which can be directly passed to a VC model. In this paper, we showed that high-quality audio samples can be achieved by using a length resampling decoder, which enables the VC model to work in conjunction with different linguistic feature extractors and vocoders without requiring them to operate on the same sequence length. We showed that our method can outperform many baselines on the VCTK dataset. Without modifying the architecture, we further demonstrated that a) using pairs of different audio segments from the same speaker, b) adding a cycle consistency loss, and c) adding a speaker classification loss can help to learn a better speaker embedding. Our model trained on LibriTTS using these techniques achieves the best performance, producing audio samples transferred well to the target speaker's voice, while preserving the linguistic content that is comparable with actual human utterances in terms of Character Error Rate.