 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
AniFaceDrawing: Anime Portrait Exploration during Your Sketching
Jun 13, 2023In this paper, we focus on how artificial intelligence (AI) can be used to assist users in the creation of anime portraits, that is, converting rough sketches into anime portraits during their sketching process. The input is a sequence of incomplete freehand sketches that are gradually refined stroke by stroke, while the output is a sequence of high-quality anime portraits that correspond to the input sketches as guidance. Although recent GANs can generate high quality images, it is a challenging problem to maintain the high quality of generated images from sketches with a low degree of completion due to ill-posed problems in conditional image generation. Even with the latest sketch-to-image (S2I) technology, it is still difficult to create high-quality images from incomplete rough sketches for anime portraits since anime style tend to be more abstract than in realistic style. To address this issue, we adopt a latent space exploration of StyleGAN with a two-stage training strategy. We consider the input strokes of a freehand sketch to correspond to edge information-related attributes in the latent structural code of StyleGAN, and term the matching between strokes and these attributes stroke-level disentanglement. In the first stage, we trained an image encoder with the pre-trained StyleGAN model as a teacher encoder. In the second stage, we simulated the drawing process of the generated images without any additional data (labels) and trained the sketch encoder for incomplete progressive sketches to generate high-quality portrait images with feature alignment to the disentangled representations in the teacher encoder. We verified the proposed progressive S2I system with both qualitative and quantitative evaluations and achieved high-quality anime portraits from incomplete progressive sketches. Our user study proved its effectiveness in art creation assistance for the anime style.
Sketch2Cloth: Sketch-based 3D Garment Generation with Unsigned Distance Fields
Mar 01, 20233D model reconstruction from a single image has achieved great progress with the recent deep generative models. However, the conventional reconstruction approaches with template mesh deformation and implicit fields have difficulty in reconstructing non-watertight 3D mesh models, such as garments. In contrast to image-based modeling, the sketch-based approach can help users generate 3D models to meet the design intentions from hand-drawn sketches. In this study, we propose Sketch2Cloth, a sketch-based 3D garment generation system using the unsigned distance fields from the user's sketch input. Sketch2Cloth first estimates the unsigned distance function of the target 3D model from the sketch input, and extracts the mesh from the estimated field with Marching Cubes. We also provide the model editing function to modify the generated mesh. We verified the proposed Sketch2Cloth with quantitative evaluations on garment generation and editing with a state-of-the-art approach.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 26, 2023



Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
Stroke Correspondence by Labeling Closed Areas
Aug 10, 2021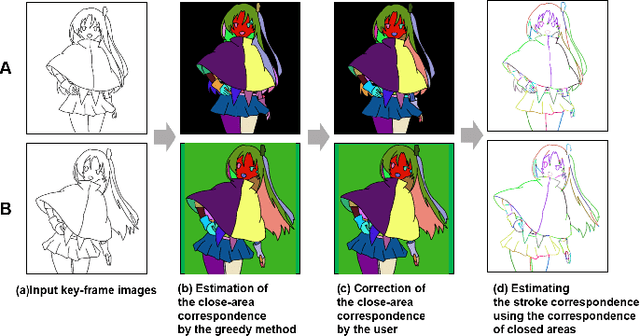

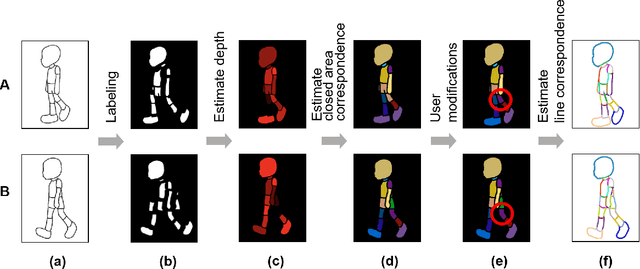
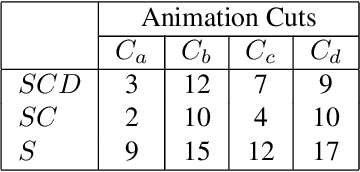
Constructing stroke correspondences between keyframes is one of the most important processes in the production pipeline of hand-drawn inbetweening frames. This process requires time-consuming manual work imposing a tremendous burden on the animators. We propose a method to estimate stroke correspondences between raster character images (keyframes) without vectorization processes. First, the proposed system separates the closed areas in each keyframe and estimates the correspondences between closed areas by using the characteristics of shape, depth, and closed area connection. Second, the proposed system estimates stroke correspondences from the estimated closed area correspondences. We demonstrate the effectiveness of our method by performing a user study and comparing the proposed system with conventional approaches.
Learning Perceptual Manifold of Fonts
Jun 17, 2021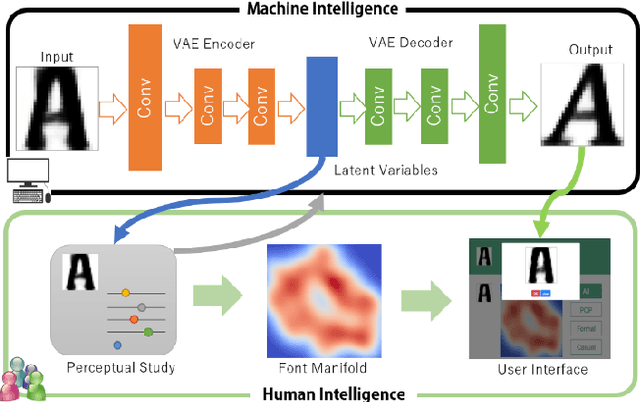
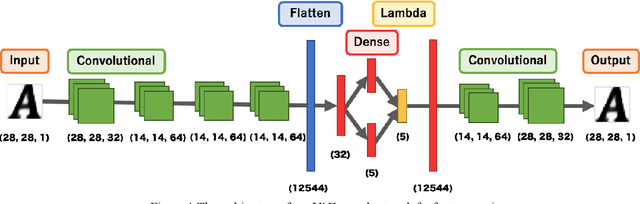

Along the rapid development of deep learning techniques in generative models, it is becoming an urgent issue to combine machine intelligence with human intelligence to solve the practical applications. Motivated by this methodology, this work aims to adjust the machine generated character fonts with the effort of human workers in the perception study. Although numerous fonts are available online for public usage, it is difficult and challenging to generate and explore a font to meet the preferences for common users. To solve the specific issue, we propose the perceptual manifold of fonts to visualize the perceptual adjustment in the latent space of a generative model of fonts. In our framework, we adopt the variational autoencoder network for the font generation. Then, we conduct a perceptual study on the generated fonts from the multi-dimensional latent space of the generative model. After we obtained the distribution data of specific preferences, we utilize manifold learning approach to visualize the font distribution. In contrast to the conventional user interface in our user study, the proposed font-exploring user interface is efficient and helpful in the designated user preference.
dualFace:Two-Stage Drawing Guidance for Freehand Portrait Sketching
Apr 26, 2021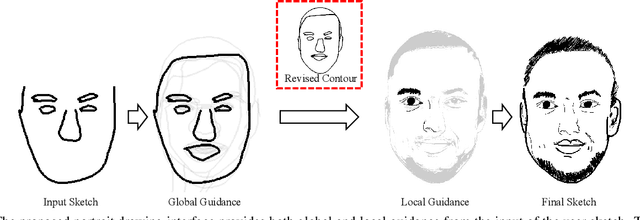
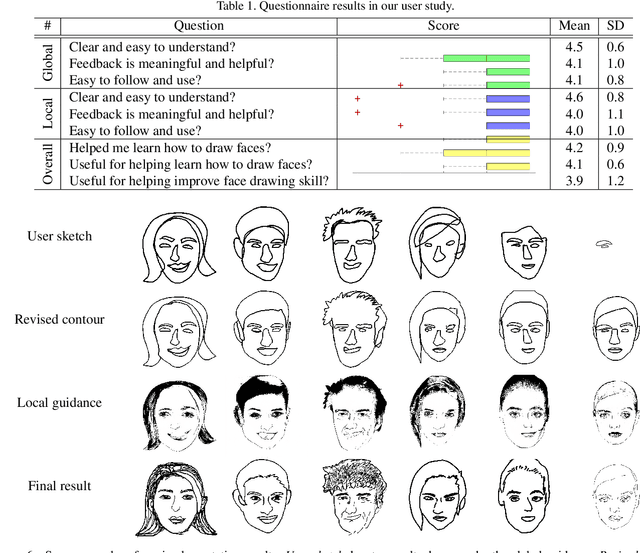
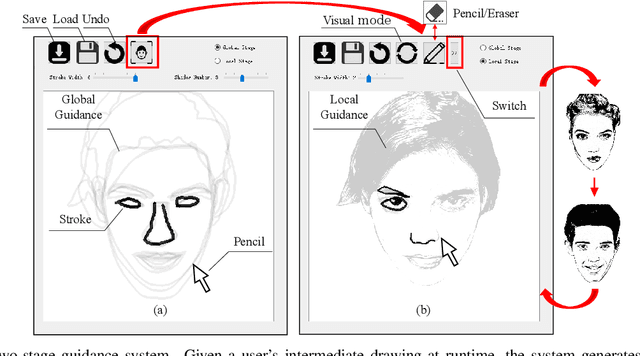
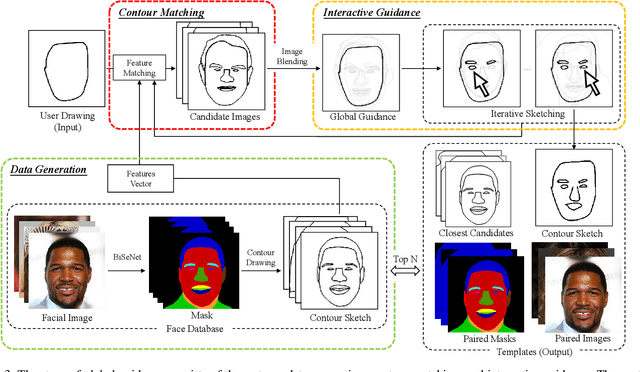
In this paper, we propose dualFace, a portrait drawing interface to assist users with different levels of drawing skills to complete recognizable and authentic face sketches. dualFace consists of two-stage drawing assistance to provide global and local visual guidance: global guidance, which helps users draw contour lines of portraits (i.e., geometric structure), and local guidance, which helps users draws details of facial parts (which conform to user-drawn contour lines), inspired by traditional artist workflows in portrait drawing. In the stage of global guidance, the user draws several contour lines, and dualFace then searches several relevant images from an internal database and displays the suggested face contour lines over the background of the canvas. In the stage of local guidance, we synthesize detailed portrait images with a deep generative model from user-drawn contour lines, but use the synthesized results as detailed drawing guidance. We conducted a user study to verify the effectiveness of dualFace, and we confirmed that dualFace significantly helps achieve a detailed portrait sketch. see http://www.jaist.ac.jp/~xie/dualface.html
Sketch-based Normal Map Generation with Geometric Sampling
Apr 23, 2021Normal map is an important and efficient way to represent complex 3D models. A designer may benefit from the auto-generation of high quality and accurate normal maps from freehand sketches in 3D content creation. This paper proposes a deep generative model for generating normal maps from users sketch with geometric sampling. Our generative model is based on Conditional Generative Adversarial Network with the curvature-sensitive points sampling of conditional masks. This sampling process can help eliminate the ambiguity of generation results as network input. In addition, we adopted a U-Net structure discriminator to help the generator be better trained. It is verified that the proposed framework can generate more accurate normal maps.