 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Full Rollouts Necessary for On-Policy Distillation?
Jun 01, 2026On-policy distillation (OPD) provides dense teacher feedback along student-generated rollouts rather than fixed teacher traces and has emerged as a promising post-training paradigm. However, standard OPD typically generates full rollouts during training, which is computationally expensive and may expose the student to unreliable teacher feedback at late rollout positions, especially during early training. We identify the rollout horizon as a key bottleneck in OPD that substantially impacts training efficiency. Unlike Reinforcement Learning with Verifiable Rewards (RLVR), OPD does not require a final answer reward to provide learning signals. Therefore, full rollouts may not always be necessary for OPD. Motivated by this insight, we propose two simple horizon-control strategies: Progressive OPD (POPD), which gradually expands the rollout horizon during training, and Truncated OPD (TOPD), which permanently performs distillation on reliable truncated rollouts. Experiments on mathematical reasoning show that POPD improves the training efficiency of OPD by up to 3$\times$, while TOPD matches OPD performance using only 10\% of the rollout horizon, leading to substantial wall-clock and memory reductions. These results demonstrate that controlling the rollout horizon offers a simple and practical path to more efficient OPD.
$π$-Play: Multi-Agent Self-Play via Privileged Self-Distillation without External Data
Apr 15, 2026Deep search agents have emerged as a promising paradigm for addressing complex information-seeking tasks, but their training remains challenging due to sparse rewards, weak credit assignment, and limited labeled data. Self-play offers a scalable route to reduce data dependence, but conventional self-play optimizes students only through sparse outcome rewards, leading to low learning efficiency. In this work, we observe that self-play naturally produces a question construction path (QCP) during task generation, an intermediate artifact that captures the reverse solution process. This reveals a new source of privileged information for self-distillation: self-play can itself provide high-quality privileged context for the teacher model in a low-cost and scalable manner, without relying on human feedback or curated privileged information. Leveraging this insight, we propose Privileged Information Self-Play ($π$-Play), a multi-agent self-evolution framework. In $π$-Play, an examiner generates tasks together with their QCPs, and a teacher model leverages QCP as privileged context to densely supervise a student via self-distillation. This design transforms conventional sparse-reward self-play into a dense-feedback self-evolution loop. Extensive experiments show that data-free $π$-Play surpasses fully supervised search agents and improves evolutionary efficiency by 2-3$\times$ over conventional self-play.
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Mar 26, 2026On-policy distillation (OPD) is appealing for large language model (LLM) post-training because it evaluates teacher feedback on student-generated rollouts rather than fixed teacher traces. In long-horizon settings, however, the common sampled-token variant is fragile: it reduces distribution matching to a one-token signal and becomes increasingly unreliable as rollouts drift away from prefixes the teacher commonly visits. We revisit OPD from the estimator and implementation sides. Theoretically, token-level OPD is biased relative to sequence-level reverse-KL, but it has a much tighter worst-case variance bound; our toy study shows the same tradeoff empirically, with stronger future-reward coupling producing higher gradient variance and less stable learning. Empirically, we identify three failure modes of sampled-token OPD: an imbalanced one-token signal, unreliable teacher guidance on student-generated prefixes, and distortions caused by tokenizer or special-token mismatch. We address these issues with teacher top-K local support matching, implemented as truncated reverse-KL with top-p rollout sampling and special-token masking. Across single-task math reasoning and multi-task agentic-plus-math training, this objective yields more stable optimization and better downstream performance than sampled-token OPD.
CriticSearch: Fine-Grained Credit Assignment for Search Agents via a Retrospective Critic
Nov 15, 2025Tool-Integrated Reasoning (TIR) with search engines enables large language models to iteratively retrieve up-to-date external knowledge, enhancing adaptability and generalization in complex question-answering tasks. However, existing search agent pipelines typically depend on reinforcement learning based optimization, which often suffers from sparse outcome rewards, leading to inefficient exploration and unstable training. We introduce CriticSearch, a fine-grained credit-assignment framework that supplies dense, turn-level feedback via a retrospective critic mechanism. During training, a frozen, asymmetric critique LLM retrospectively evaluates each turn using privileged information from the full trajectory and gold answers, converting these assessments into stable, dense rewards that guide policy improvement. Experimental results across diverse multi-hop reasoning benchmarks demonstrate that CriticSearch consistently outperforms existing baselines, achieving faster convergence, improved training stability, and higher performance.
ARAC: Adaptive Regularized Multi-Agent Soft Actor-Critic in Graph-Structured Adversarial Games
Nov 11, 2025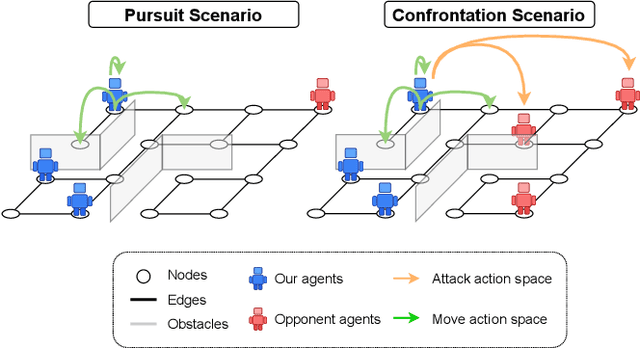
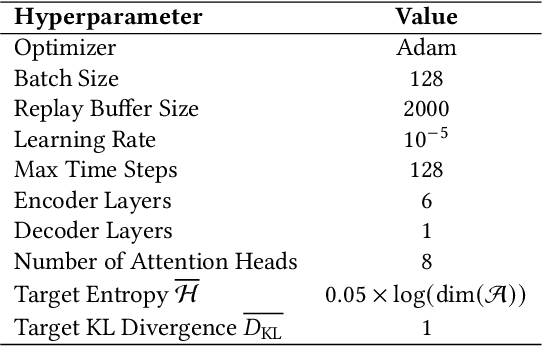
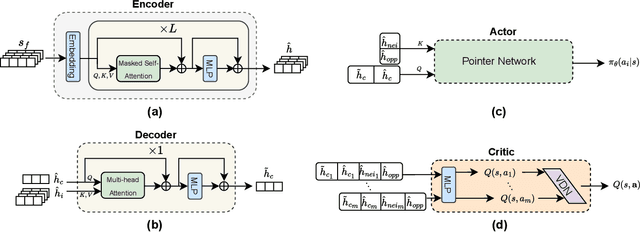
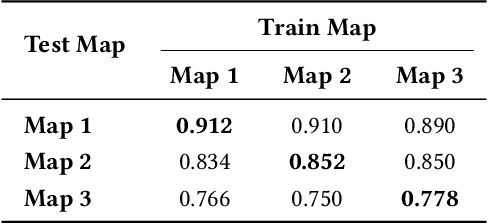
In graph-structured multi-agent reinforcement learning (MARL) adversarial tasks such as pursuit and confrontation, agents must coordinate under highly dynamic interactions, where sparse rewards hinder efficient policy learning. We propose Adaptive Regularized Multi-Agent Soft Actor-Critic (ARAC), which integrates an attention-based graph neural network (GNN) for modeling agent dependencies with an adaptive divergence regularization mechanism. The GNN enables expressive representation of spatial relations and state features in graph environments. Divergence regularization can serve as policy guidance to alleviate the sparse reward problem, but it may lead to suboptimal convergence when the reference policy itself is imperfect. The adaptive divergence regularization mechanism enables the framework to exploit reference policies for efficient exploration in the early stages, while gradually reducing reliance on them as training progresses to avoid inheriting their limitations. Experiments in pursuit and confrontation scenarios demonstrate that ARAC achieves faster convergence, higher final success rates, and stronger scalability across varying numbers of agents compared with MARL baselines, highlighting its effectiveness in complex graph-structured environments.
Empowering Multi-Robot Cooperation via Sequential World Models
Sep 16, 2025Model-based reinforcement learning (MBRL) has shown significant potential in robotics due to its high sample efficiency and planning capability. However, extending MBRL to multi-robot cooperation remains challenging due to the complexity of joint dynamics. To address this, we propose the Sequential World Model (SeqWM), a novel framework that integrates the sequential paradigm into model-based multi-agent reinforcement learning. SeqWM employs independent, sequentially structured agent-wise world models to decompose complex joint dynamics. Latent rollouts and decision-making are performed through sequential communication, where each agent generates its future trajectory and plans its actions based on the predictions of its predecessors. This design enables explicit intention sharing, enhancing cooperative performance, and reduces communication overhead to linear complexity. Results in challenging simulated environments (Bi-DexHands and Multi-Quad) show that SeqWM outperforms existing state-of-the-art model-free and model-based baselines in both overall performance and sample efficiency, while exhibiting advanced cooperative behaviors such as predictive adaptation and role division. Furthermore, SeqWM has been success fully deployed on physical quadruped robots, demonstrating its effectiveness in real-world multi-robot systems. Demos and code are available at: https://github.com/zhaozijie2022/seqwm-marl
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning
Jun 24, 2025Large language models (LLMs) have achieved remarkable progress in reasoning tasks, yet the optimal integration of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) remains a fundamental challenge. Through comprehensive analysis of token distributions, learning dynamics, and integration mechanisms from entropy-based perspectives, we reveal key differences between these paradigms: SFT induces coarse-grained global changes to LLM policy distributions, while RL performs fine-grained selective optimizations, with entropy serving as a critical indicator of training effectiveness. Building on these observations, we propose Supervised Reinforcement Fine-Tuning (SRFT), a single-stage method that unifies both fine-tuning paradigms through entropy-aware weighting mechanisms. Our approach simultaneously applies SFT and RL to directly optimize the LLM using demonstrations and self-exploration rollouts rather than through two-stage sequential methods. Extensive experiments show that SRFT achieves 59.1% average accuracy, outperforming zero-RL methods by 9.0% on five mathematical reasoning benchmarks and 10.9% on three out-of-distribution benchmarks.
DipLLM: Fine-Tuning LLM for Strategic Decision-making in Diplomacy
Jun 11, 2025



Diplomacy is a complex multiplayer game that requires both cooperation and competition, posing significant challenges for AI systems. Traditional methods rely on equilibrium search to generate extensive game data for training, which demands substantial computational resources. Large Language Models (LLMs) offer a promising alternative, leveraging pre-trained knowledge to achieve strong performance with relatively small-scale fine-tuning. However, applying LLMs to Diplomacy remains challenging due to the exponential growth of possible action combinations and the intricate strategic interactions among players. To address this challenge, we propose DipLLM, a fine-tuned LLM-based agent that learns equilibrium policies for Diplomacy. DipLLM employs an autoregressive factorization framework to simplify the complex task of multi-unit action assignment into a sequence of unit-level decisions. By defining an equilibrium policy within this framework as the learning objective, we fine-tune the model using only 1.5% of the data required by the state-of-the-art Cicero model, surpassing its performance. Our results demonstrate the potential of fine-tuned LLMs for tackling complex strategic decision-making in multiplayer games.
Meta-DT: Offline Meta-RL as Conditional Sequence Modeling with World Model Disentanglement
Oct 15, 2024A longstanding goal of artificial general intelligence is highly capable generalists that can learn from diverse experiences and generalize to unseen tasks. The language and vision communities have seen remarkable progress toward this trend by scaling up transformer-based models trained on massive datasets, while reinforcement learning (RL) agents still suffer from poor generalization capacity under such paradigms. To tackle this challenge, we propose Meta Decision Transformer (Meta-DT), which leverages the sequential modeling ability of the transformer architecture and robust task representation learning via world model disentanglement to achieve efficient generalization in offline meta-RL. We pretrain a context-aware world model to learn a compact task representation, and inject it as a contextual condition to the causal transformer to guide task-oriented sequence generation. Then, we subtly utilize history trajectories generated by the meta-policy as a self-guided prompt to exploit the architectural inductive bias. We select the trajectory segment that yields the largest prediction error on the pretrained world model to construct the prompt, aiming to encode task-specific information complementary to the world model maximally. Notably, the proposed framework eliminates the requirement of any expert demonstration or domain knowledge at test time. Experimental results on MuJoCo and Meta-World benchmarks across various dataset types show that Meta-DT exhibits superior few and zero-shot generalization capacity compared to strong baselines while being more practical with fewer prerequisites. Our code is available at https://github.com/NJU-RL/Meta-DT.
Discretizing Continuous Action Space with Unimodal Probability Distributions for On-Policy Reinforcement Learning
Aug 01, 2024For on-policy reinforcement learning, discretizing action space for continuous control can easily express multiple modes and is straightforward to optimize. However, without considering the inherent ordering between the discrete atomic actions, the explosion in the number of discrete actions can possess undesired properties and induce a higher variance for the policy gradient estimator. In this paper, we introduce a straightforward architecture that addresses this issue by constraining the discrete policy to be unimodal using Poisson probability distributions. This unimodal architecture can better leverage the continuity in the underlying continuous action space using explicit unimodal probability distributions. We conduct extensive experiments to show that the discrete policy with the unimodal probability distribution provides significantly faster convergence and higher performance for on-policy reinforcement learning algorithms in challenging control tasks, especially in highly complex tasks such as Humanoid. We provide theoretical analysis on the variance of the policy gradient estimator, which suggests that our attentively designed unimodal discrete policy can retain a lower variance and yield a stable learning process.