 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
Mar 18, 2023



The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also leads to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity, and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity while retaining the benefits of pre-trained textual representations for downstream tasks.
Towards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
May 25, 2022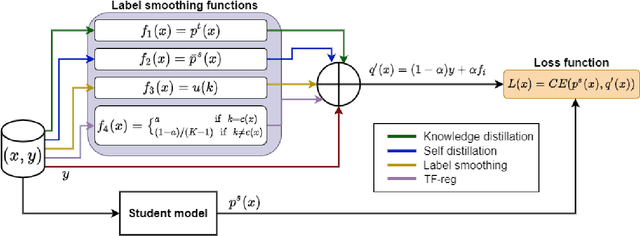
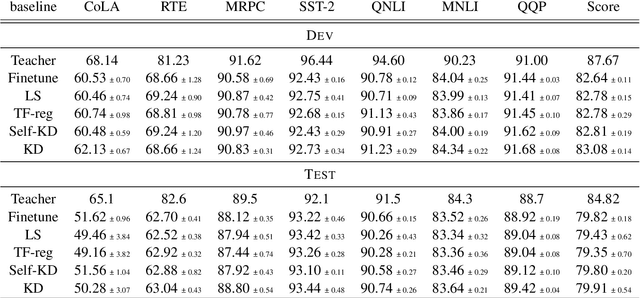
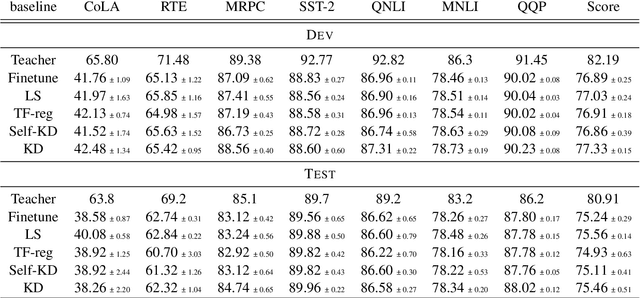
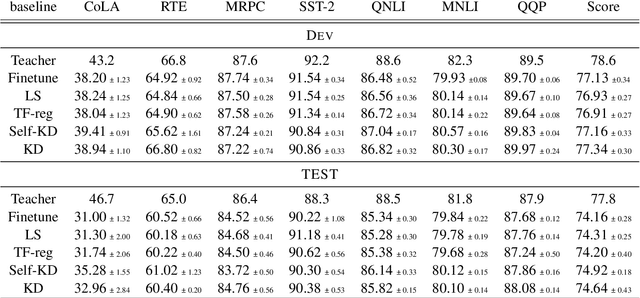
Knowledge Distillation (KD) is a prominent neural model compression technique which heavily relies on teacher network predictions to guide the training of a student model. Considering the ever-growing size of pre-trained language models (PLMs), KD is often adopted in many NLP tasks involving PLMs. However, it is evident that in KD, deploying the teacher network during training adds to the memory and computational requirements of training. In the computer vision literature, the necessity of the teacher network is put under scrutiny by showing that KD is a label regularization technique that can be replaced with lighter teacher-free variants such as the label-smoothing technique. However, to the best of our knowledge, this issue is not investigated in NLP. Therefore, this work concerns studying different label regularization techniques and whether we actually need the teacher labels to fine-tune smaller PLM student networks on downstream tasks. In this regard, we did a comprehensive set of experiments on different PLMs such as BERT, RoBERTa, and GPT with more than 600 distinct trials and ran each configuration five times. This investigation led to a surprising observation that KD and other label regularization techniques do not play any meaningful role over regular fine-tuning when the student model is pre-trained. We further explore this phenomenon in different settings of NLP and computer vision tasks and demonstrate that pre-training itself acts as a kind of regularization, and additional label regularization is unnecessary.
A Short Study on Compressing Decoder-Based Language Models
Oct 16, 2021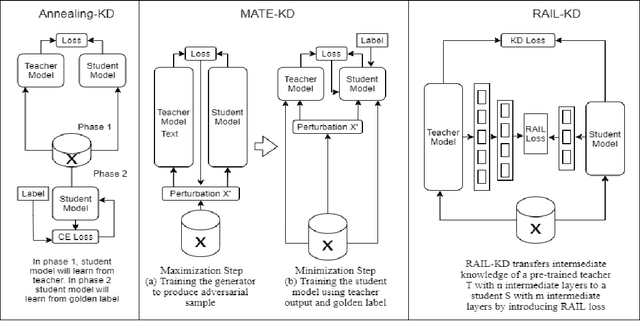
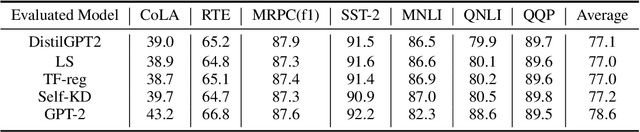

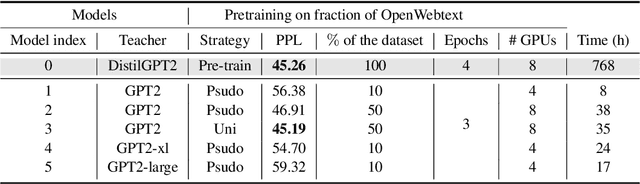
Pre-trained Language Models (PLMs) have been successful for a wide range of natural language processing (NLP) tasks. The state-of-the-art of PLMs, however, are extremely large to be used on edge devices. As a result, the topic of model compression has attracted increasing attention in the NLP community. Most of the existing works focus on compressing encoder-based models (tiny-BERT, distilBERT, distilRoBERTa, etc), however, to the best of our knowledge, the compression of decoder-based models (such as GPT-2) has not been investigated much. Our paper aims to fill this gap. Specifically, we explore two directions: 1) we employ current state-of-the-art knowledge distillation techniques to improve fine-tuning of DistilGPT-2. 2) we pre-train a compressed GPT-2 model using layer truncation and compare it against the distillation-based method (DistilGPT2). The training time of our compressed model is significantly less than DistilGPT-2, but it can achieve better performance when fine-tuned on downstream tasks. We also demonstrate the impact of data cleaning on model performance.
How to Select One Among All? An Extensive Empirical Study Towards the Robustness of Knowledge Distillation in Natural Language Understanding
Sep 20, 2021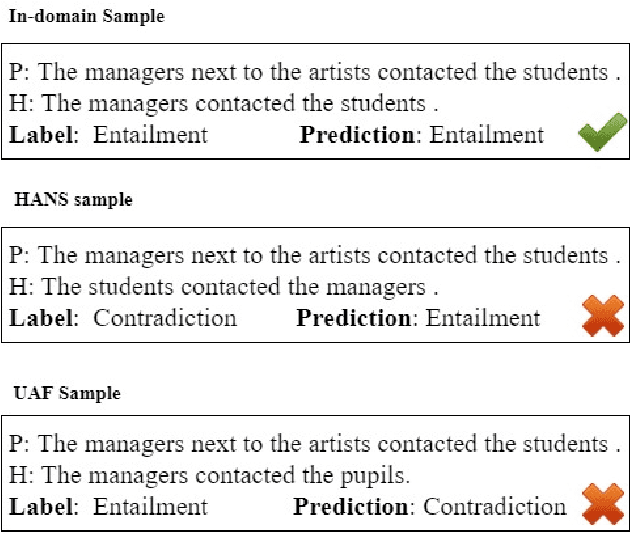
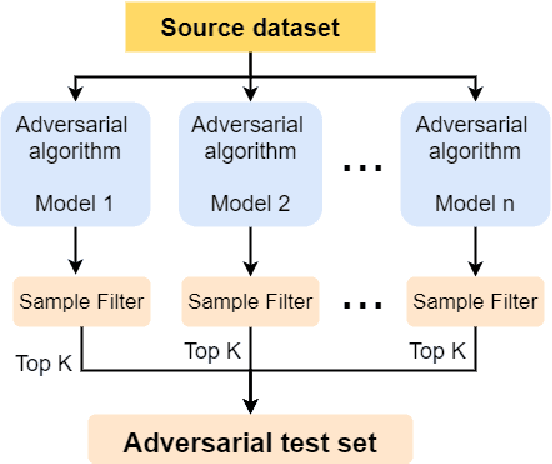
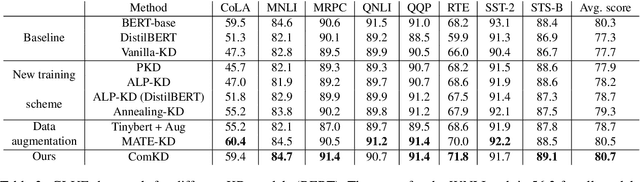
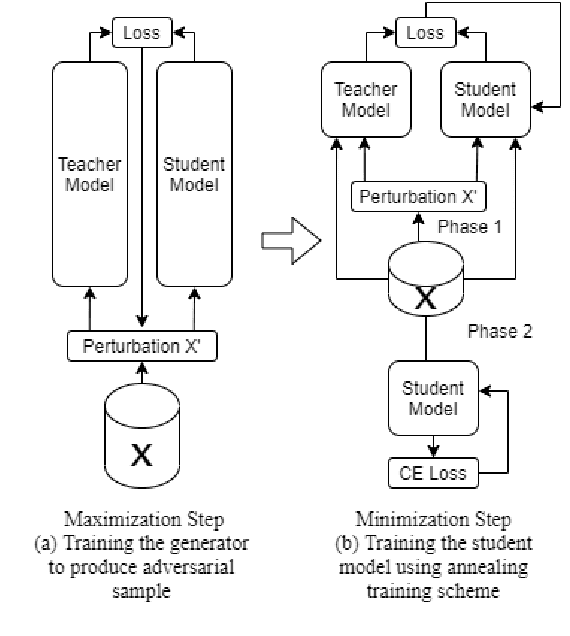
Knowledge Distillation (KD) is a model compression algorithm that helps transfer the knowledge of a large neural network into a smaller one. Even though KD has shown promise on a wide range of Natural Language Processing (NLP) applications, little is understood about how one KD algorithm compares to another and whether these approaches can be complimentary to each other. In this work, we evaluate various KD algorithms on in-domain, out-of-domain and adversarial testing. We propose a framework to assess the adversarial robustness of multiple KD algorithms. Moreover, we introduce a new KD algorithm, Combined-KD, which takes advantage of two promising approaches (better training scheme and more efficient data augmentation). Our extensive experimental results show that Combined-KD achieves state-of-the-art results on the GLUE benchmark, out-of-domain generalization, and adversarial robustness compared to competitive methods.
Unsupervised Pre-training with Structured Knowledge for Improving Natural Language Inference
Sep 08, 2021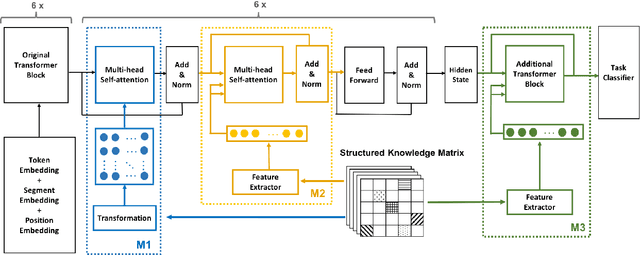
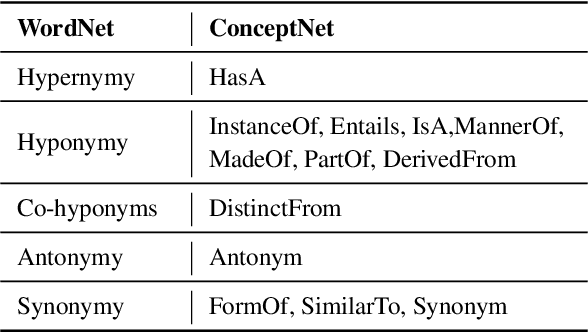
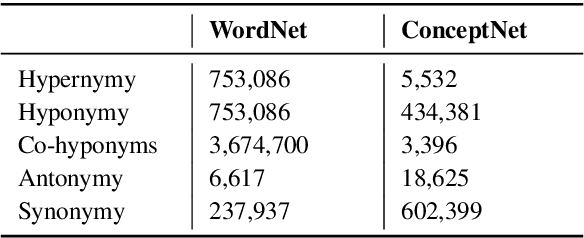
While recent research on natural language inference has considerably benefited from large annotated datasets, the amount of inference-related knowledge (including commonsense) provided in the annotated data is still rather limited. There have been two lines of approaches that can be used to further address the limitation: (1) unsupervised pretraining can leverage knowledge in much larger unstructured text data; (2) structured (often human-curated) knowledge has started to be considered in neural-network-based models for NLI. An immediate question is whether these two approaches complement each other, or how to develop models that can bring together their advantages. In this paper, we propose models that leverage structured knowledge in different components of pre-trained models. Our results show that the proposed models perform better than previous BERT-based state-of-the-art models. Although our models are proposed for NLI, they can be easily extended to other sentence or sentence-pair classification problems.
Learning to Retrieve Entity-Aware Knowledge and Generate Responses with Copy Mechanism for Task-Oriented Dialogue Systems
Dec 22, 2020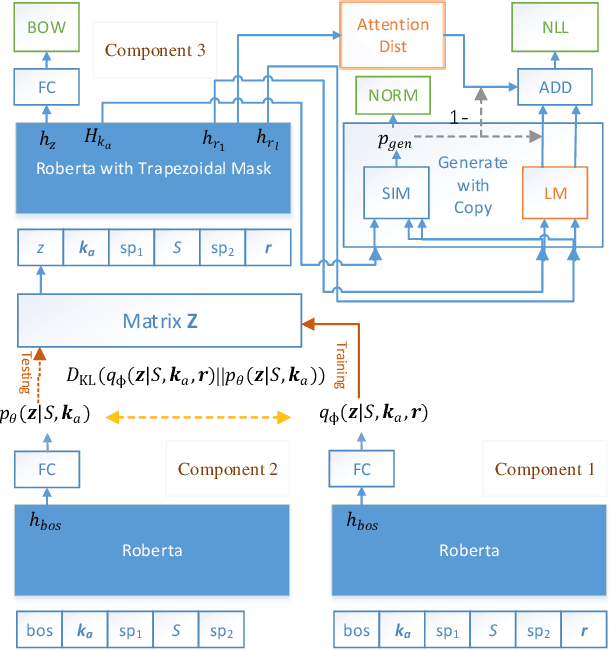

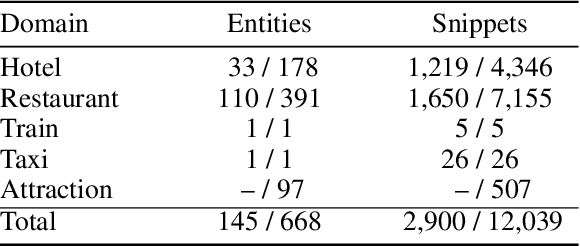

Task-oriented conversational modeling with unstructured knowledge access, as track 1 of the 9th Dialogue System Technology Challenges (DSTC 9), requests to build a system to generate response given dialogue history and knowledge access. This challenge can be separated into three subtasks, (1) knowledge-seeking turn detection, (2) knowledge selection, and (3) knowledge-grounded response generation. We use pre-trained language models, ELECTRA and RoBERTa, as our base encoder for different subtasks. For subtask 1 and 2, the coarse-grained information like domain and entity are used to enhance knowledge usage. For subtask 3, we use a latent variable to encode dialog history and selected knowledge better and generate responses combined with copy mechanism. Meanwhile, some useful post-processing strategies are performed on the model's final output to make further knowledge usage in the generation task. As shown in released evaluation results, our proposed system ranks second under objective metrics and ranks fourth under human metrics.
DialBERT: A Hierarchical Pre-Trained Model for Conversation Disentanglement
Apr 08, 2020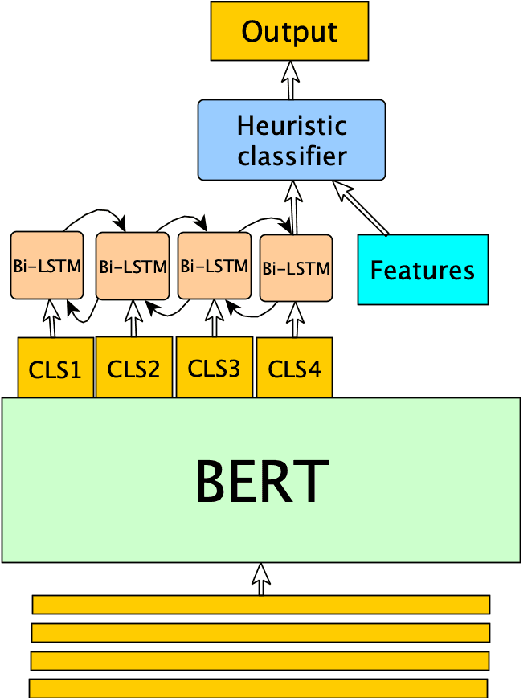
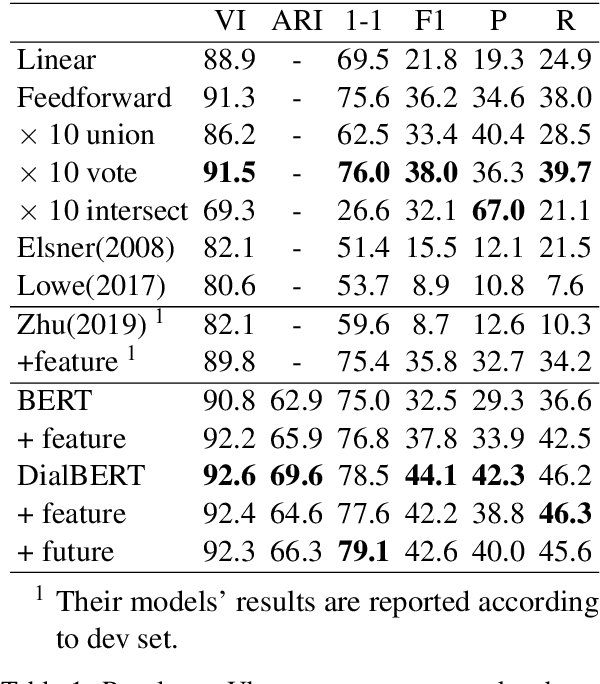
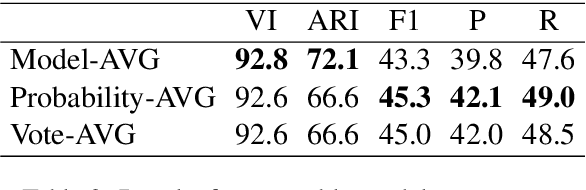
Disentanglement is a problem in which multiple conversations occur in the same channel simultaneously, and the listener should decide which utterance is part of the conversation he will respond to. We propose a new model, named Dialogue BERT (DialBERT), which integrates local and global semantics in a single stream of messages to disentangle the conversations that mixed together. We employ BERT to capture the matching information in each utterance pair at the utterance-level, and use a BiLSTM to aggregate and incorporate the context-level information. With only a 3% increase in parameters, a 12% improvement has been attained in comparison to BERT, based on the F1-Score. The model achieves a state-of-the-art result on the a new dataset proposed by IBM and surpasses previous work by a substantial margin.
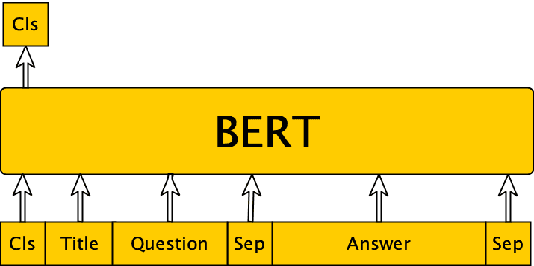
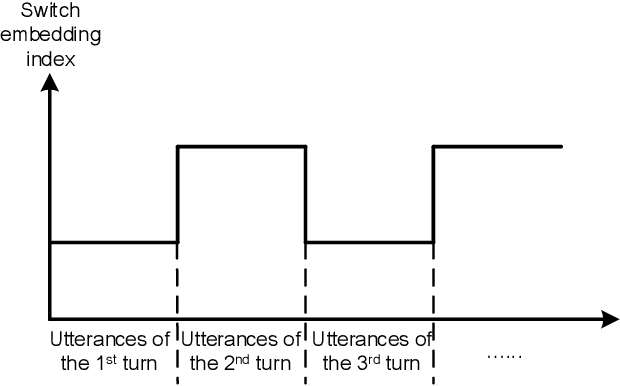
Speaker-Aware BERT for Multi-Turn Response Selection in Retrieval-Based Chatbots
Apr 07, 2020
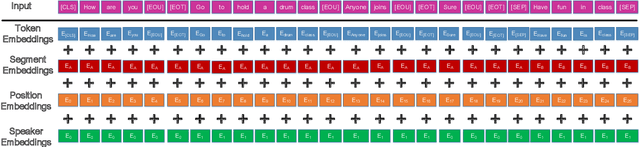

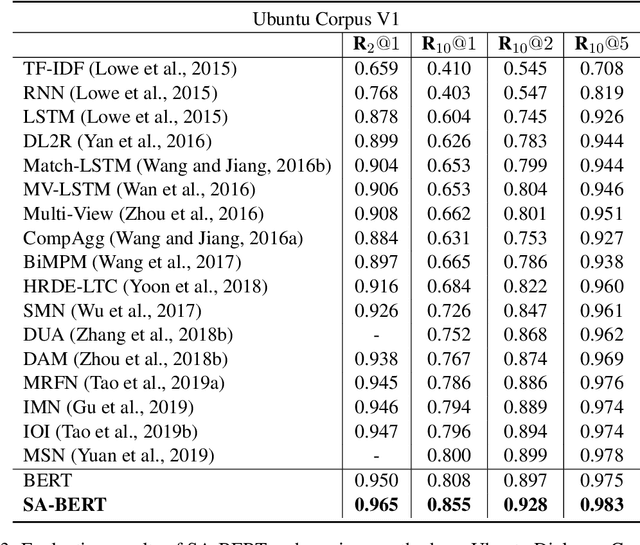
In this paper, we study the problem of employing pre-trained language models for multi-turn response selection in retrieval-based chatbots. A new model, named Speaker-Aware BERT (SA-BERT), is proposed in order to make the model aware of the speaker change information, which is an important and intrinsic property of multi-turn dialogues. Furthermore, a speaker-aware disentanglement strategy is proposed to tackle the entangled dialogues. This strategy selects a small number of most important utterances as the filtered context according to the speakers' information in them. Finally, domain adaptation is performed in order to incorporate the in-domain knowledge into pre-trained language models. Experiments on five public datasets show that our proposed model outperforms the present models on all metrics by large margins and achieves new state-of-the-art performances for multi-turn response selection.
Pre-Trained and Attention-Based Neural Networks for Building Noetic Task-Oriented Dialogue Systems
Apr 04, 2020
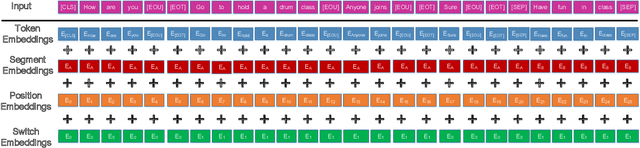
The NOESIS II challenge, as the Track 2 of the 8th Dialogue System Technology Challenges (DSTC 8), is the extension of DSTC 7. This track incorporates new elements that are vital for the creation of a deployed task-oriented dialogue system. This paper describes our systems that are evaluated on all subtasks under this challenge. We study the problem of employing pre-trained attention-based network for multi-turn dialogue systems. Meanwhile, several adaptation methods are proposed to adapt the pre-trained language models for multi-turn dialogue systems, in order to keep the intrinsic property of dialogue systems. In the released evaluation results of Track 2 of DSTC 8, our proposed models ranked fourth in subtask 1, third in subtask 2, and first in subtask 3 and subtask 4 respectively.
Several Experiments on Investigating Pretraining and Knowledge-Enhanced Models for Natural Language Inference
Apr 27, 2019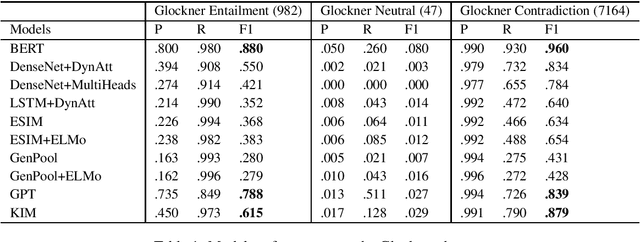
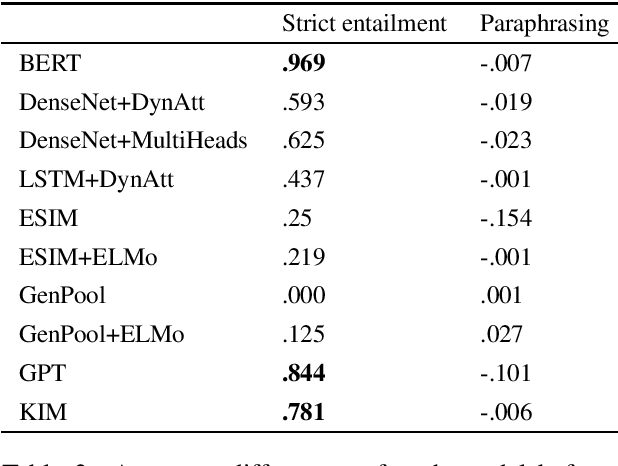


Natural language inference (NLI) is among the most challenging tasks in natural language understanding. Recent work on unsupervised pretraining that leverages unsupervised signals such as language-model and sentence prediction objectives has shown to be very effective on a wide range of NLP problems. It would still be desirable to further understand how it helps NLI; e.g., if it learns artifacts in data annotation or instead learn true inference knowledge. In addition, external knowledge that does not exist in the limited amount of NLI training data may be added to NLI models in two typical ways, e.g., from human-created resources or an unsupervised pretraining paradigm. We runs several experiments here to investigate whether they help NLI in the same way, and if not,how?