 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMVD: Geometry-Enhanced Multi-View Generation Model Based on Geometric Information Extraction
Nov 19, 2025
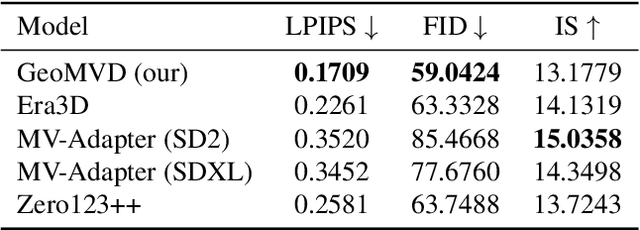
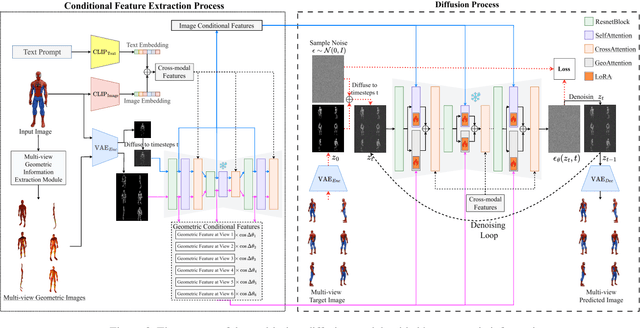
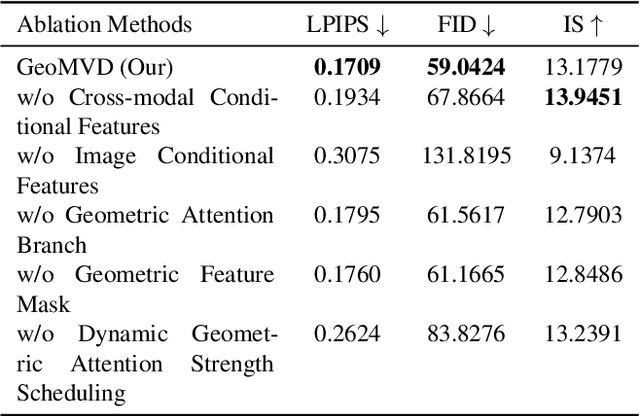
Multi-view image generation holds significant application value in computer vision, particularly in domains like 3D reconstruction, virtual reality, and augmented reality. Most existing methods, which rely on extending single images, face notable computational challenges in maintaining cross-view consistency and generating high-resolution outputs. To address these issues, we propose the Geometry-guided Multi-View Diffusion Model, which incorporates mechanisms for extracting multi-view geometric information and adjusting the intensity of geometric features to generate images that are both consistent across views and rich in detail. Specifically, we design a multi-view geometry information extraction module that leverages depth maps, normal maps, and foreground segmentation masks to construct a shared geometric structure, ensuring shape and structural consistency across different views. To enhance consistency and detail restoration during generation, we develop a decoupled geometry-enhanced attention mechanism that strengthens feature focus on key geometric details, thereby improving overall image quality and detail preservation. Furthermore, we apply an adaptive learning strategy that fine-tunes the model to better capture spatial relationships and visual coherence between the generated views, ensuring realistic results. Our model also incorporates an iterative refinement process that progressively improves the output quality through multiple stages of image generation. Finally, a dynamic geometry information intensity adjustment mechanism is proposed to adaptively regulate the influence of geometric data, optimizing overall quality while ensuring the naturalness of generated images. More details can be found on the project page: https://sobeymil.github.io/GeoMVD.com.
Compressed Video Super-Resolution based on Hierarchical Encoding
Jun 17, 2025



This paper presents a general-purpose video super-resolution (VSR) method, dubbed VSR-HE, specifically designed to enhance the perceptual quality of compressed content. Targeting scenarios characterized by heavy compression, the method upscales low-resolution videos by a ratio of four, from 180p to 720p or from 270p to 1080p. VSR-HE adopts hierarchical encoding transformer blocks and has been sophisticatedly optimized to eliminate a wide range of compression artifacts commonly introduced by H.265/HEVC encoding across various quantization parameter (QP) levels. To ensure robustness and generalization, the model is trained and evaluated under diverse compression settings, allowing it to effectively restore fine-grained details and preserve visual fidelity. The proposed VSR-HE has been officially submitted to the ICME 2025 Grand Challenge on VSR for Video Conferencing (Team BVI-VSR), under both the Track 1 (General-Purpose Real-World Video Content) and Track 2 (Talking Head Videos).
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
HPGN: Hybrid Priors-Guided Network for Compressed Low-Light Image Enhancement
Apr 03, 2025In practical applications, conventional methods generate large volumes of low-light images that require compression for efficient storage and transmission. However, most existing methods either disregard the removal of potential compression artifacts during the enhancement process or fail to establish a unified framework for joint task enhancement of images with varying compression qualities. To solve this problem, we propose the hybrid priors-guided network (HPGN), which enhances compressed low-light images by integrating both compression and illumination priors. Our approach fully utilizes the JPEG quality factor (QF) and DCT quantization matrix (QM) to guide the design of efficient joint task plug-and-play modules. Additionally, we employ a random QF generation strategy to guide model training, enabling a single model to enhance images across different compression levels. Experimental results confirm the superiority of our proposed method.
Blind Video Super-Resolution based on Implicit Kernels
Mar 10, 2025Blind video super-resolution (BVSR) is a low-level vision task which aims to generate high-resolution videos from low-resolution counterparts in unknown degradation scenarios. Existing approaches typically predict blur kernels that are spatially invariant in each video frame or even the entire video. These methods do not consider potential spatio-temporal varying degradations in videos, resulting in suboptimal BVSR performance. In this context, we propose a novel BVSR model based on Implicit Kernels, BVSR-IK, which constructs a multi-scale kernel dictionary parameterized by implicit neural representations. It also employs a newly designed recurrent Transformer to predict the coefficient weights for accurate filtering in both frame correction and feature alignment. Experimental results have demonstrated the effectiveness of the proposed BVSR-IK, when compared with four state-of-the-art BVSR models on three commonly used datasets, with BVSR-IK outperforming the second best approach, FMA-Net, by up to 0.59 dB in PSNR. Source code will be available at https://github.com.
FCVSR: A Frequency-aware Method for Compressed Video Super-Resolution
Feb 10, 2025



Compressed video super-resolution (SR) aims to generate high-resolution (HR) videos from the corresponding low-resolution (LR) compressed videos. Recently, some compressed video SR methods attempt to exploit the spatio-temporal information in the frequency domain, showing great promise in super-resolution performance. However, these methods do not differentiate various frequency subbands spatially or capture the temporal frequency dynamics, potentially leading to suboptimal results. In this paper, we propose a deep frequency-based compressed video SR model (FCVSR) consisting of a motion-guided adaptive alignment (MGAA) network and a multi-frequency feature refinement (MFFR) module. Additionally, a frequency-aware contrastive loss is proposed for training FCVSR, in order to reconstruct finer spatial details. The proposed model has been evaluated on three public compressed video super-resolution datasets, with results demonstrating its effectiveness when compared to existing works in terms of super-resolution performance (up to a 0.14dB gain in PSNR over the second-best model) and complexity.
Color Enhancement for V-PCC Compressed Point Cloud via 2D Attribute Map Optimization
Dec 19, 2024



Video-based point cloud compression (V-PCC) converts the dynamic point cloud data into video sequences using traditional video codecs for efficient encoding. However, this lossy compression scheme introduces artifacts that degrade the color attributes of the data. This paper introduces a framework designed to enhance the color quality in the V-PCC compressed point clouds. We propose the lightweight de-compression Unet (LDC-Unet), a 2D neural network, to optimize the projection maps generated during V-PCC encoding. The optimized 2D maps will then be back-projected to the 3D space to enhance the corresponding point cloud attributes. Additionally, we introduce a transfer learning strategy and develop a customized natural image dataset for the initial training. The model was then fine-tuned using the projection maps of the compressed point clouds. The whole strategy effectively addresses the scarcity of point cloud training data. Our experiments, conducted on the public 8i voxelized full bodies long sequences (8iVSLF) dataset, demonstrate the effectiveness of our proposed method in improving the color quality.
Plug-and-Play Tri-Branch Invertible Block for Image Rescaling
Dec 18, 2024High-resolution (HR) images are commonly downscaled to low-resolution (LR) to reduce bandwidth, followed by upscaling to restore their original details. Recent advancements in image rescaling algorithms have employed invertible neural networks (INNs) to create a unified framework for downscaling and upscaling, ensuring a one-to-one mapping between LR and HR images. Traditional methods, utilizing dual-branch based vanilla invertible blocks, process high-frequency and low-frequency information separately, often relying on specific distributions to model high-frequency components. However, processing the low-frequency component directly in the RGB domain introduces channel redundancy, limiting the efficiency of image reconstruction. To address these challenges, we propose a plug-and-play tri-branch invertible block (T-InvBlocks) that decomposes the low-frequency branch into luminance (Y) and chrominance (CbCr) components, reducing redundancy and enhancing feature processing. Additionally, we adopt an all-zero mapping strategy for high-frequency components during upscaling, focusing essential rescaling information within the LR image. Our T-InvBlocks can be seamlessly integrated into existing rescaling models, improving performance in both general rescaling tasks and scenarios involving lossy compression. Extensive experiments confirm that our method advances the state of the art in HR image reconstruction.
Associate Everything Detected: Facilitating Tracking-by-Detection to the Unknown
Sep 14, 2024



Multi-object tracking (MOT) emerges as a pivotal and highly promising branch in the field of computer vision. Classical closed-vocabulary MOT (CV-MOT) methods aim to track objects of predefined categories. Recently, some open-vocabulary MOT (OV-MOT) methods have successfully addressed the problem of tracking unknown categories. However, we found that the CV-MOT and OV-MOT methods each struggle to excel in the tasks of the other. In this paper, we present a unified framework, Associate Everything Detected (AED), that simultaneously tackles CV-MOT and OV-MOT by integrating with any off-the-shelf detector and supports unknown categories. Different from existing tracking-by-detection MOT methods, AED gets rid of prior knowledge (e.g. motion cues) and relies solely on highly robust feature learning to handle complex trajectories in OV-MOT tasks while keeping excellent performance in CV-MOT tasks. Specifically, we model the association task as a similarity decoding problem and propose a sim-decoder with an association-centric learning mechanism. The sim-decoder calculates similarities in three aspects: spatial, temporal, and cross-clip. Subsequently, association-centric learning leverages these threefold similarities to ensure that the extracted features are appropriate for continuous tracking and robust enough to generalize to unknown categories. Compared with existing powerful OV-MOT and CV-MOT methods, AED achieves superior performance on TAO, SportsMOT, and DanceTrack without any prior knowledge. Our code is available at https://github.com/balabooooo/AED.