 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Apr 28, 2026Autonomous scientific research is significantly advanced thanks to the development of AI agents. One key step in this process is finding the right scientific literature, whether to explore existing knowledge for a research problem, or to acquire evidence for verifying assumptions and supporting claims. To assess AI agents' capability in driving this process, we present AutoResearchBench, a dedicated benchmark for autonomous scientific literature discovery. AutoResearchBench consists of two complementary task types: (1) Deep Research, which requires tracking down a specific target paper through a progressive, multi-step probing process, and (2) Wide Research, which requires comprehensively collecting a set of papers satisfying given conditions. Compared to previous benchmarks on agentic web browsing, AutoResearchBench is distinguished along three dimensions: it is research-oriented, calling for in-depth comprehension of scientific concepts; literature-focused, demanding fine-grained utilization of detailed information; and open-ended, involving an unknown number of qualified papers and thus requiring deliberate reasoning and search throughout. These properties make AutoResearchBench uniquely suited for evaluating autonomous research capabilities, and extraordinarily challenging. Even the most powerful LLMs, despite having largely conquered general agentic web-browsing benchmarks such as BrowseComp, achieve only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research, while many other strong baselines fall below 5%. We publicly release the dataset and evaluation pipeline to facilitate future research in this direction. We publicly release the dataset, evaluation pipeline, and code at https://github.com/CherYou/AutoResearchBench.
PaperScope: A Multi-Modal Multi-Document Benchmark for Agentic Deep Research Across Massive Scientific Papers
Apr 13, 2026Leveraging Multi-modal Large Language Models (MLLMs) to accelerate frontier scientific research is promising, yet how to rigorously evaluate such systems remains unclear. Existing benchmarks mainly focus on single-document understanding, whereas real scientific workflows require integrating evidence from multiple papers, including their text, tables, and figures. As a result, multi-modal, multi-document scientific reasoning remains underexplored and lacks systematic evaluation. To address this gap, we introduce PaperScope, a multi-modal multi-document benchmark designed for agentic deep research. PaperScope presents three advantages: (1) Structured scientific grounding. It is built on a knowledge graph of over 2,000 AI papers spanning three years, providing a structured foundation for research-oriented queries. (2) Semantically dense evidence construction. It integrates semantically related key information nodes and employs optimized random-walk article selector to sample thematically coherent paper sets, thereby ensuring adequate semantic density and task complexity. (3) Multi-task evaluation of scientific reasoning. It contains over 2,000 QA pairs across reasoning, retrieval, summarization, and problem solving, enabling evaluation of multi-step scientific reasoning. Experimental results show that even advanced systems such as OpenAI Deep Research and Tongyi Deep Research achieve limited scores on PaperScope, highlighting the difficulty of long-context retrieval and deep multi-source reasoning. PaperScope thus provides a rigorous benchmark alongside a scalable pipeline for constructing large-scale multi-modal, multi-source deep research datasets.
HPGN: Hybrid Priors-Guided Network for Compressed Low-Light Image Enhancement
Apr 03, 2025In practical applications, conventional methods generate large volumes of low-light images that require compression for efficient storage and transmission. However, most existing methods either disregard the removal of potential compression artifacts during the enhancement process or fail to establish a unified framework for joint task enhancement of images with varying compression qualities. To solve this problem, we propose the hybrid priors-guided network (HPGN), which enhances compressed low-light images by integrating both compression and illumination priors. Our approach fully utilizes the JPEG quality factor (QF) and DCT quantization matrix (QM) to guide the design of efficient joint task plug-and-play modules. Additionally, we employ a random QF generation strategy to guide model training, enabling a single model to enhance images across different compression levels. Experimental results confirm the superiority of our proposed method.
Texture-guided Coding for Deep Features
May 30, 2024



With the rapid development of machine vision technology in recent years, many researchers have begun to focus on feature compression that is better suited for machine vision tasks. The target of feature compression is deep features, which arise from convolution in the middle layer of a pre-trained convolutional neural network. However, due to the large volume of data and high level of abstraction of deep features, their application is primarily limited to machine-centric scenarios, which poses significant constraints in situations requiring human-computer interaction. This paper investigates features and textures and proposes a texture-guided feature compression strategy based on their characteristics. Specifically, the strategy comprises feature layers and texture layers. The feature layers serve the machine, including a feature selection module and a feature reconstruction network. With the assistance of texture images, they selectively compress and transmit channels relevant to visual tasks, reducing feature data while providing high-quality features for the machine. The texture layers primarily serve humans and consist of an image reconstruction network. This image reconstruction network leverages features and texture images to reconstruct preview images for humans. Our method fully exploits the characteristics of texture and features. It eliminates feature redundancy, reconstructs high-quality preview images for humans, and supports decision-making. The experimental results demonstrate excellent performance when employing our proposed method to compress the deep features.
iACOS: Advancing Implicit Sentiment Extraction with Informative and Adaptive Negative Examples
Nov 07, 2023



Aspect-based sentiment analysis (ABSA) have been extensively studied, but little light has been shed on the quadruple extraction consisting of four fundamental elements: aspects, categories, opinions and sentiments, especially with implicit aspects and opinions. In this paper, we propose a new method iACOS for extracting Implicit Aspects with Categories and Opinions with Sentiments. First, iACOS appends two implicit tokens at the end of a text to capture the context-aware representation of all tokens including implicit aspects and opinions. Second, iACOS develops a sequence labeling model over the context-aware token representation to co-extract explicit and implicit aspects and opinions. Third, iACOS devises a multi-label classifier with a specialized multi-head attention for discovering aspect-opinion pairs and predicting their categories and sentiments simultaneously. Fourth, iACOS leverages informative and adaptive negative examples to jointly train the multi-label classifier and the other two classifiers on categories and sentiments by multi-task learning. Finally, the experimental results show that iACOS significantly outperforms other quadruple extraction baselines according to the F1 score on two public benchmark datasets.
The Limits of ChatGPT in Extracting Aspect-Category-Opinion-Sentiment Quadruples: A Comparative Analysis
Oct 10, 2023



Recently, ChatGPT has attracted great attention from both industry and academia due to its surprising abilities in natural language understanding and generation. We are particularly curious about whether it can achieve promising performance on one of the most complex tasks in aspect-based sentiment analysis, i.e., extracting aspect-category-opinion-sentiment quadruples from texts. To this end, in this paper we develop a specialized prompt template that enables ChatGPT to effectively tackle this complex quadruple extraction task. Further, we propose a selection method on few-shot examples to fully exploit the in-context learning ability of ChatGPT and uplift its effectiveness on this complex task. Finally, we provide a comparative evaluation on ChatGPT against existing state-of-the-art quadruple extraction models based on four public datasets and highlight some important findings regarding the capability boundaries of ChatGPT in the quadruple extraction.
See the Near Future: A Short-Term Predictive Methodology to Traffic Load in ITS
Jan 08, 2017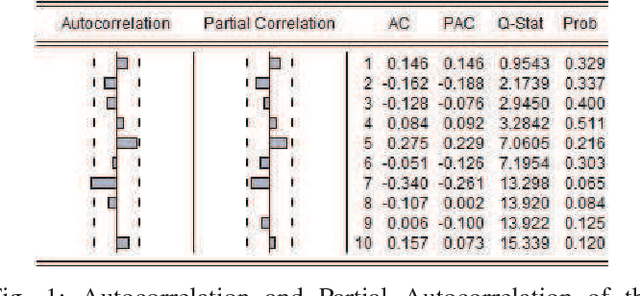
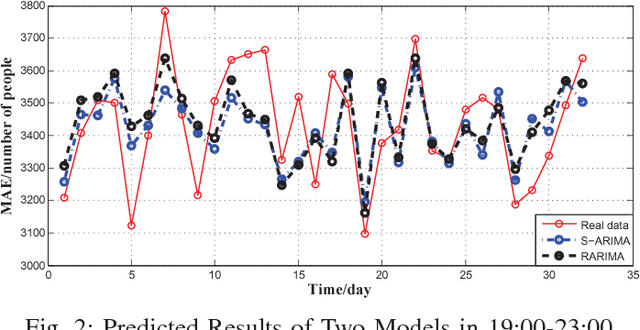
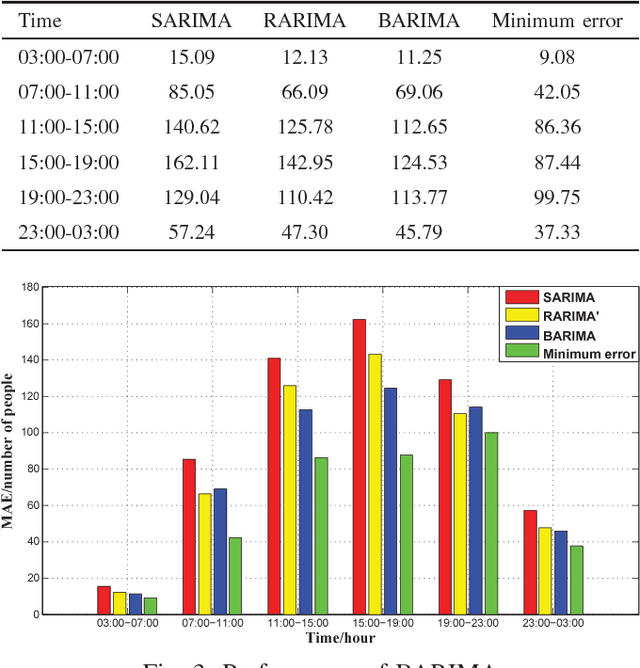
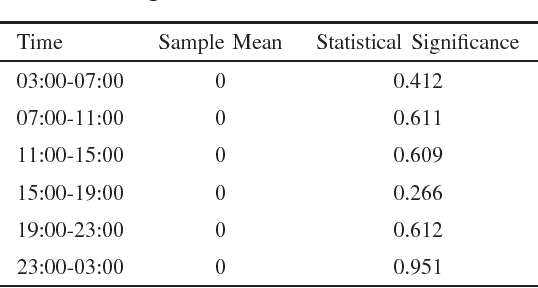
The Intelligent Transportation System (ITS) targets to a coordinated traffic system by applying the advanced wireless communication technologies for road traffic scheduling. Towards an accurate road traffic control, the short-term traffic forecasting to predict the road traffic at the particular site in a short period is often useful and important. In existing works, Seasonal Autoregressive Integrated Moving Average (SARIMA) model is a popular approach. The scheme however encounters two challenges: 1) the analysis on related data is insufficient whereas some important features of data may be neglected; and 2) with data presenting different features, it is unlikely to have one predictive model that can fit all situations. To tackle above issues, in this work, we develop a hybrid model to improve accuracy of SARIMA. In specific, we first explore the autocorrelation and distribution features existed in traffic flow to revise structure of the time series model. Based on the Gaussian distribution of traffic flow, a hybrid model with a Bayesian learning algorithm is developed which can effectively expand the application scenarios of SARIMA. We show the efficiency and accuracy of our proposal using both analysis and experimental studies. Using the real-world trace data, we show that the proposed predicting approach can achieve satisfactory performance in practice.