 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillNet-NLG: General-Purpose Natural Language Generation with a Sparsely Activated Approach
Apr 26, 2022We present SkillNet-NLG, a sparsely activated approach that handles many natural language generation tasks with one model. Different from traditional dense models that always activate all the parameters, SkillNet-NLG selectively activates relevant parts of the parameters to accomplish a task, where the relevance is controlled by a set of predefined skills. The strength of such model design is that it provides an opportunity to precisely adapt relevant skills to learn new tasks effectively. We evaluate on Chinese natural language generation tasks. Results show that, with only one model file, SkillNet-NLG outperforms previous best performance methods on four of five tasks. SkillNet-NLG performs better than two multi-task learning baselines (a dense model and a Mixture-of-Expert model) and achieves comparable performance to task-specific models. Lastly, SkillNet-NLG surpasses baseline systems when being adapted to new tasks.
Pretraining Chinese BERT for Detecting Word Insertion and Deletion Errors
Apr 26, 2022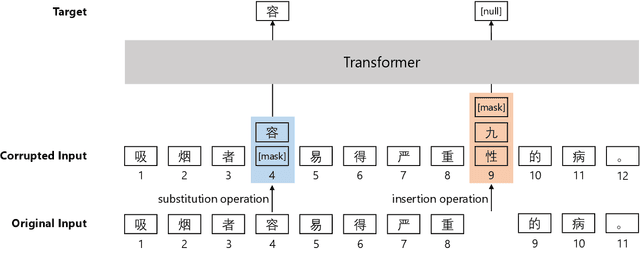
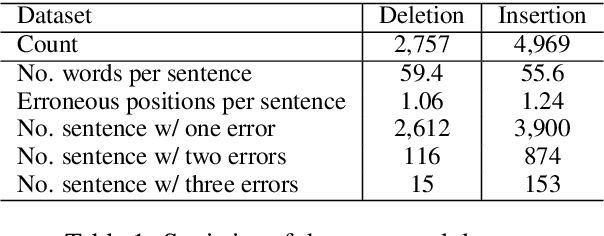
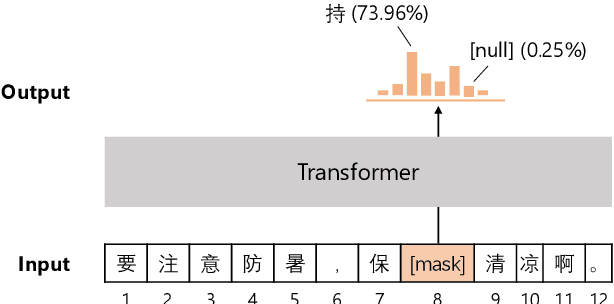
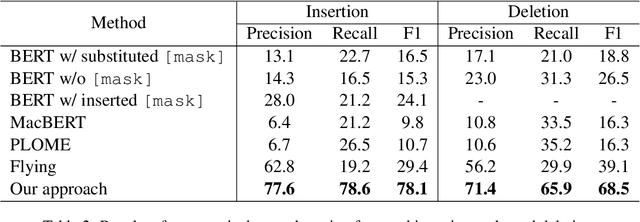
Chinese BERT models achieve remarkable progress in dealing with grammatical errors of word substitution. However, they fail to handle word insertion and deletion because BERT assumes the existence of a word at each position. To address this, we present a simple and effective Chinese pretrained model. The basic idea is to enable the model to determine whether a word exists at a particular position. We achieve this by introducing a special token \texttt{[null]}, the prediction of which stands for the non-existence of a word. In the training stage, we design pretraining tasks such that the model learns to predict \texttt{[null]} and real words jointly given the surrounding context. In the inference stage, the model readily detects whether a word should be inserted or deleted with the standard masked language modeling function. We further create an evaluation dataset to foster research on word insertion and deletion. It includes human-annotated corrections for 7,726 erroneous sentences. Results show that existing Chinese BERT performs poorly on detecting insertion and deletion errors. Our approach significantly improves the F1 scores from 24.1\% to 78.1\% for word insertion and from 26.5\% to 68.5\% for word deletion, respectively.
A Model-Agnostic Data Manipulation Method for Persona-based Dialogue Generation
Apr 21, 2022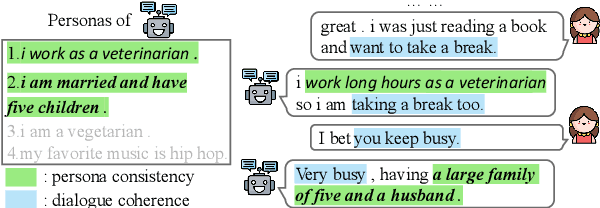
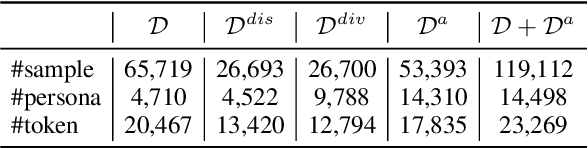
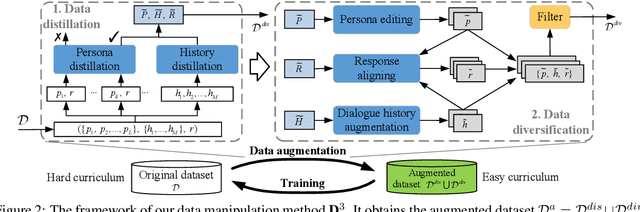
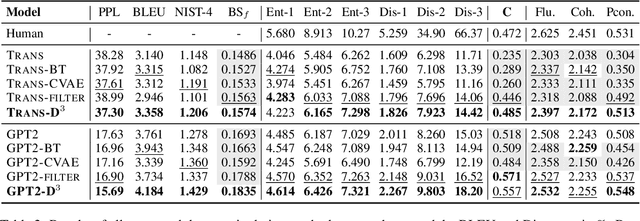
Towards building intelligent dialogue agents, there has been a growing interest in introducing explicit personas in generation models. However, with limited persona-based dialogue data at hand, it may be difficult to train a dialogue generation model well. We point out that the data challenges of this generation task lie in two aspects: first, it is expensive to scale up current persona-based dialogue datasets; second, each data sample in this task is more complex to learn with than conventional dialogue data. To alleviate the above data issues, we propose a data manipulation method, which is model-agnostic to be packed with any persona-based dialogue generation model to improve its performance. The original training samples will first be distilled and thus expected to be fitted more easily. Next, we show various effective ways that can diversify such easier distilled data. A given base model will then be trained via the constructed data curricula, i.e. first on augmented distilled samples and then on original ones. Experiments illustrate the superiority of our method with two strong base dialogue models (Transformer encoder-decoder and GPT2).
Investigating Data Variance in Evaluations of Automatic Machine Translation Metrics
Mar 29, 2022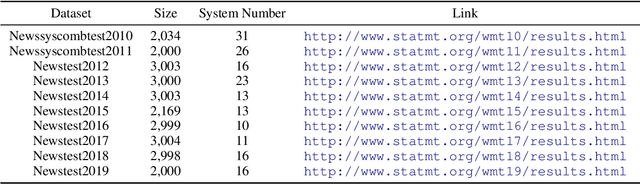
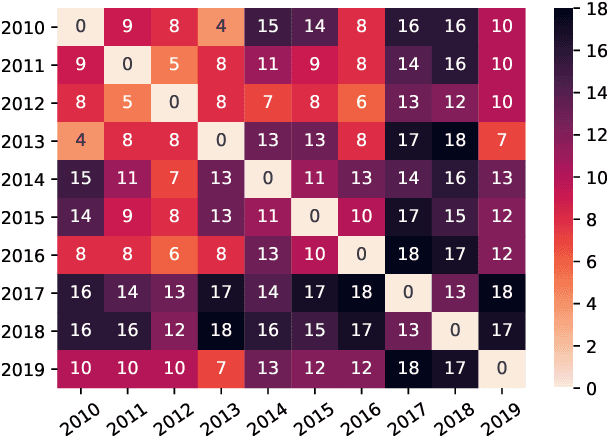
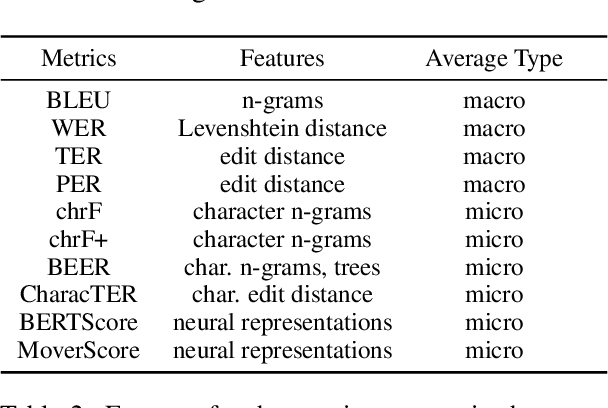
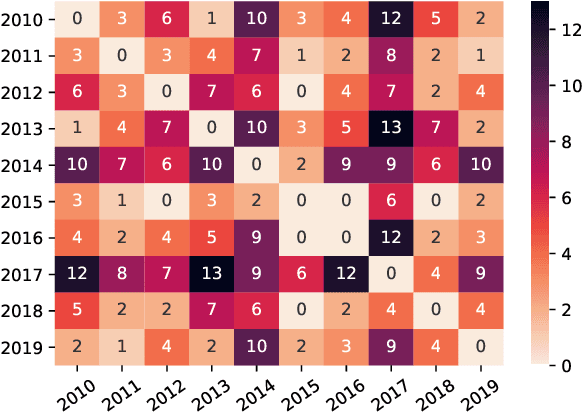
Current practices in metric evaluation focus on one single dataset, e.g., Newstest dataset in each year's WMT Metrics Shared Task. However, in this paper, we qualitatively and quantitatively show that the performances of metrics are sensitive to data. The ranking of metrics varies when the evaluation is conducted on different datasets. Then this paper further investigates two potential hypotheses, i.e., insignificant data points and the deviation of Independent and Identically Distributed (i.i.d) assumption, which may take responsibility for the issue of data variance. In conclusion, our findings suggest that when evaluating automatic translation metrics, researchers should take data variance into account and be cautious to claim the result on a single dataset, because it may leads to inconsistent results with most of other datasets.
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
Mar 23, 2022
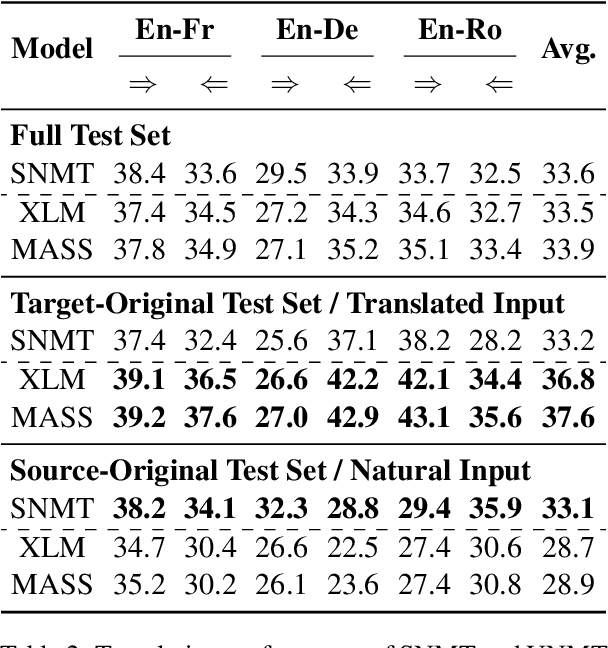
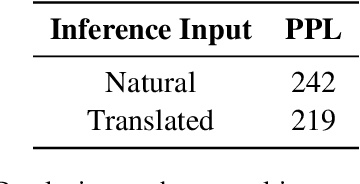
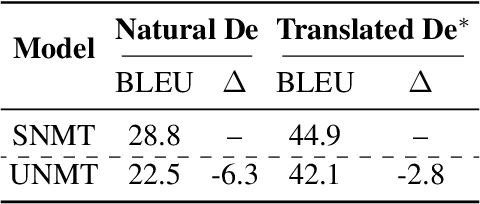
Back-translation is a critical component of Unsupervised Neural Machine Translation (UNMT), which generates pseudo parallel data from target monolingual data. A UNMT model is trained on the pseudo parallel data with translated source, and translates natural source sentences in inference. The source discrepancy between training and inference hinders the translation performance of UNMT models. By carefully designing experiments, we identify two representative characteristics of the data gap in source: (1) style gap (i.e., translated vs. natural text style) that leads to poor generalization capability; (2) content gap that induces the model to produce hallucination content biased towards the target language. To narrow the data gap, we propose an online self-training approach, which simultaneously uses the pseudo parallel data {natural source, translated target} to mimic the inference scenario. Experimental results on several widely-used language pairs show that our approach outperforms two strong baselines (XLM and MASS) by remedying the style and content gaps.
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
Mar 16, 2022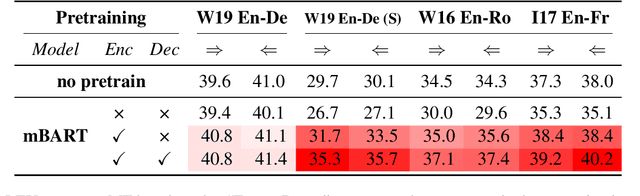

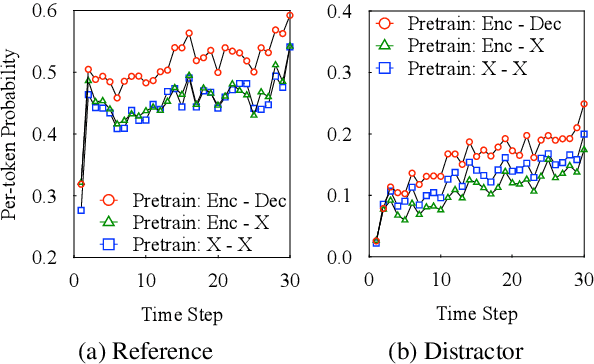
In this paper, we present a substantial step in better understanding the SOTA sequence-to-sequence (Seq2Seq) pretraining for neural machine translation~(NMT). We focus on studying the impact of the jointly pretrained decoder, which is the main difference between Seq2Seq pretraining and previous encoder-based pretraining approaches for NMT. By carefully designing experiments on three language pairs, we find that Seq2Seq pretraining is a double-edged sword: On one hand, it helps NMT models to produce more diverse translations and reduce adequacy-related translation errors. On the other hand, the discrepancies between Seq2Seq pretraining and NMT finetuning limit the translation quality (i.e., domain discrepancy) and induce the over-estimation issue (i.e., objective discrepancy). Based on these observations, we further propose simple and effective strategies, named in-domain pretraining and input adaptation to remedy the domain and objective discrepancies, respectively. Experimental results on several language pairs show that our approach can consistently improve both translation performance and model robustness upon Seq2Seq pretraining.
MarkBERT: Marking Word Boundaries Improves Chinese BERT
Mar 12, 2022
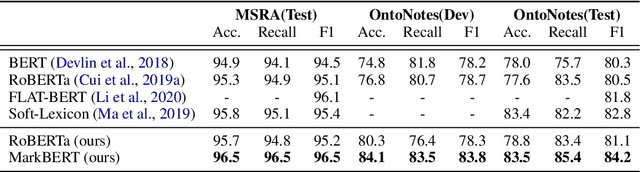
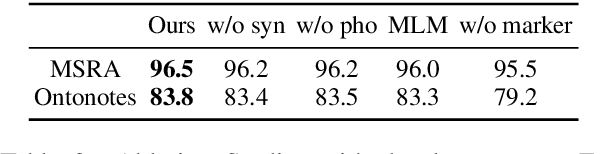
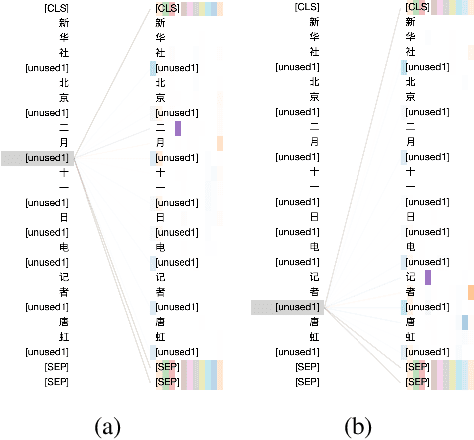
We present a Chinese BERT model dubbed MarkBERT that uses word information. Existing word-based BERT models regard words as basic units, however, due to the vocabulary limit of BERT, they only cover high-frequency words and fall back to character level when encountering out-of-vocabulary (OOV) words. Different from existing works, MarkBERT keeps the vocabulary being Chinese characters and inserts boundary markers between contiguous words. Such design enables the model to handle any words in the same way, no matter they are OOV words or not. Besides, our model has two additional benefits: first, it is convenient to add word-level learning objectives over markers, which is complementary to traditional character and sentence-level pre-training tasks; second, it can easily incorporate richer semantics such as POS tags of words by replacing generic markers with POS tag-specific markers. MarkBERT pushes the state-of-the-art of Chinese named entity recognition from 95.4\% to 96.5\% on the MSRA dataset and from 82.8\% to 84.2\% on the OntoNotes dataset, respectively. Compared to previous word-based BERT models, MarkBERT achieves better accuracy on text classification, keyword recognition, and semantic similarity tasks.
Efficient Sub-structured Knowledge Distillation
Mar 09, 2022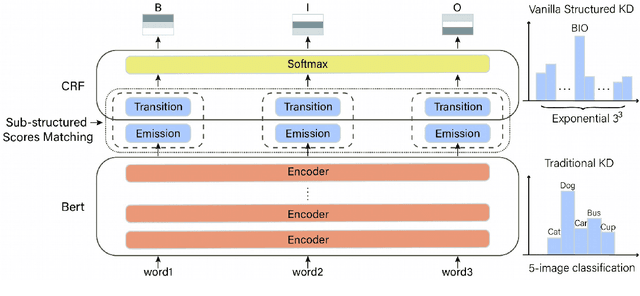
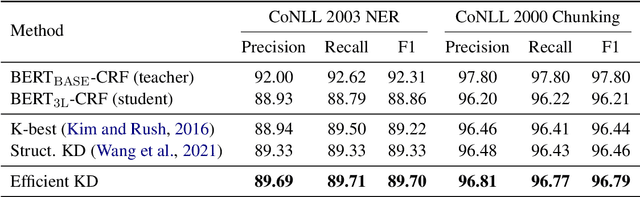

Structured prediction models aim at solving a type of problem where the output is a complex structure, rather than a single variable. Performing knowledge distillation for such models is not trivial due to their exponentially large output space. In this work, we propose an approach that is much simpler in its formulation and far more efficient for training than existing approaches. Specifically, we transfer the knowledge from a teacher model to its student model by locally matching their predictions on all sub-structures, instead of the whole output space. In this manner, we avoid adopting some time-consuming techniques like dynamic programming (DP) for decoding output structures, which permits parallel computation and makes the training process even faster in practice. Besides, it encourages the student model to better mimic the internal behavior of the teacher model. Experiments on two structured prediction tasks demonstrate that our approach outperforms previous methods and halves the time cost for one training epoch.
One Model, Multiple Tasks: Pathways for Natural Language Understanding
Mar 07, 2022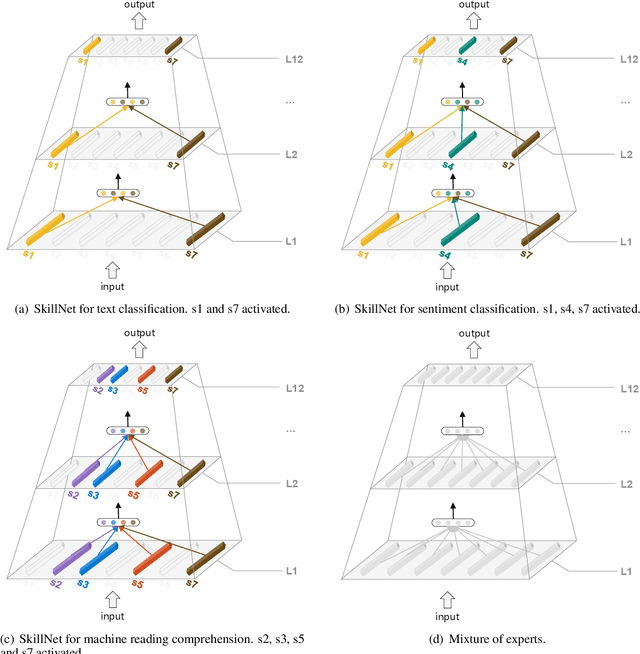

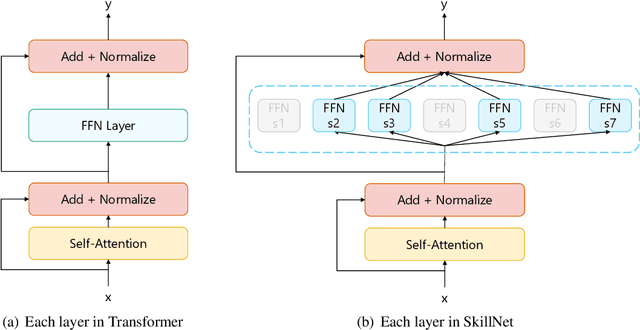
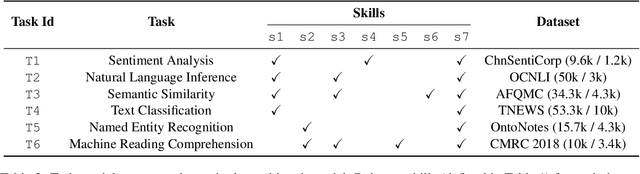
This paper presents a Pathways approach to handle many tasks at once. Our approach is general-purpose and sparse. Unlike prevailing single-purpose models that overspecialize at individual tasks and learn from scratch when being extended to new tasks, our approach is general-purpose with the ability of stitching together existing skills to learn new tasks more effectively. Different from traditional dense models that always activate all the model parameters, our approach is sparsely activated: only relevant parts of the model (like pathways through the network) are activated. We take natural language understanding as a case study and define a set of skills like \textit{the skill of understanding the sentiment of text} and \textit{the skill of understanding natural language questions}. These skills can be reused and combined to support many different tasks and situations. We develop our system using Transformer as the backbone. For each skill, we implement skill-specific feed-forward networks, which are activated only if the skill is relevant to the task. An appealing feature of our model is that it not only supports sparsely activated fine-tuning, but also allows us to pretrain skills in the same sparse way with masked language modeling and next sentence prediction. We call this model \textbf{SkillNet}. We have three major findings. First, with only one model checkpoint, SkillNet performs better than task-specific fine-tuning and two multi-task learning baselines (i.e., dense model and Mixture-of-Experts model) on six tasks. Second, sparsely activated pre-training further improves the overall performance. Third, SkillNet significantly outperforms baseline systems when being extended to new tasks.
Exploring and Adapting Chinese GPT to Pinyin Input Method
Mar 02, 2022
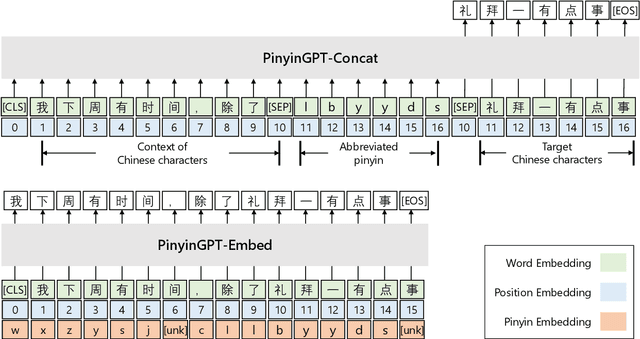

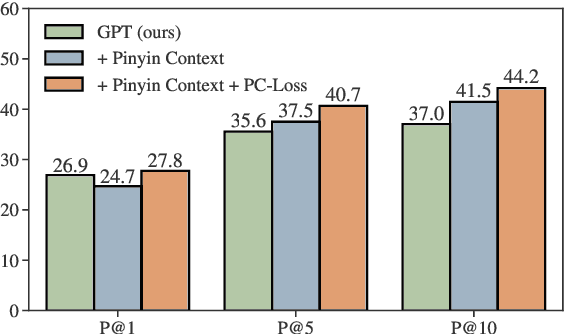
While GPT has become the de-facto method for text generation tasks, its application to pinyin input method remains unexplored. In this work, we make the first exploration to leverage Chinese GPT for pinyin input method. We find that a frozen GPT achieves state-of-the-art performance on perfect pinyin. However, the performance drops dramatically when the input includes abbreviated pinyin. A reason is that an abbreviated pinyin can be mapped to many perfect pinyin, which links to even larger number of Chinese characters. We mitigate this issue with two strategies, including enriching the context with pinyin and optimizing the training process to help distinguish homophones. To further facilitate the evaluation of pinyin input method, we create a dataset consisting of 270K instances from 15 domains. Results show that our approach improves performance on abbreviated pinyin across all domains. Model analysis demonstrates that both strategies contribute to the performance boost.