 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Data Variance in Evaluations of Automatic Machine Translation Metrics
Paper and Code
Mar 29, 2022
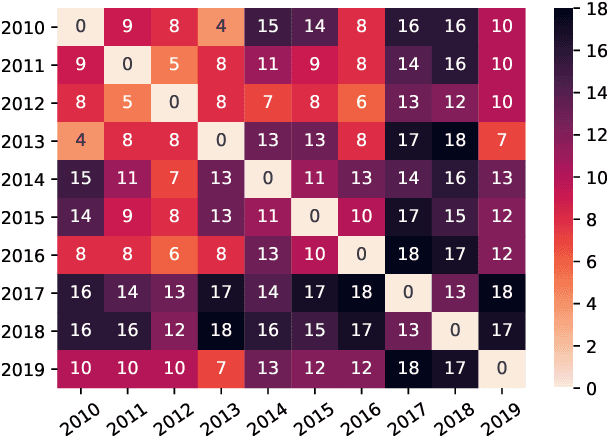
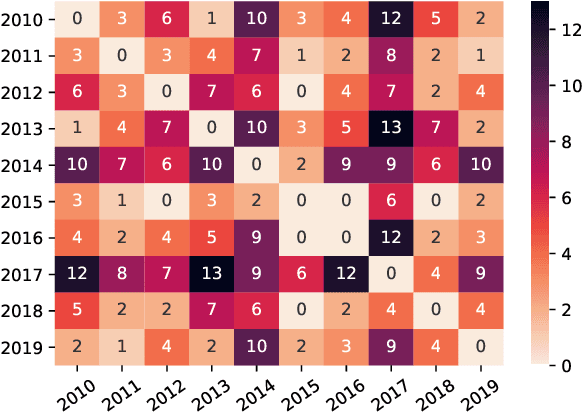
Current practices in metric evaluation focus on one single dataset, e.g., Newstest dataset in each year's WMT Metrics Shared Task. However, in this paper, we qualitatively and quantitatively show that the performances of metrics are sensitive to data. The ranking of metrics varies when the evaluation is conducted on different datasets. Then this paper further investigates two potential hypotheses, i.e., insignificant data points and the deviation of Independent and Identically Distributed (i.i.d) assumption, which may take responsibility for the issue of data variance. In conclusion, our findings suggest that when evaluating automatic translation metrics, researchers should take data variance into account and be cautious to claim the result on a single dataset, because it may leads to inconsistent results with most of other datasets.