 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Human Pose Estimation in Videos of Crowded Scenes
Oct 21, 2020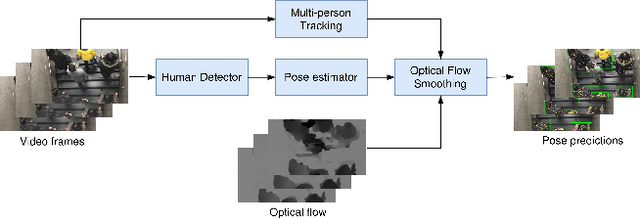

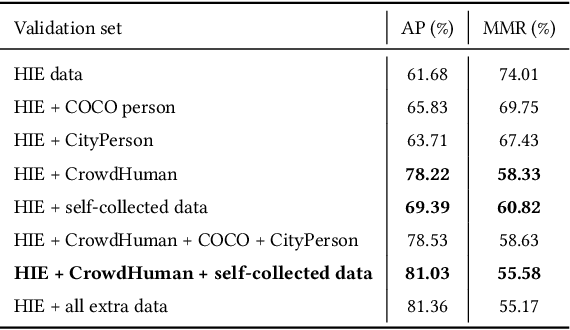
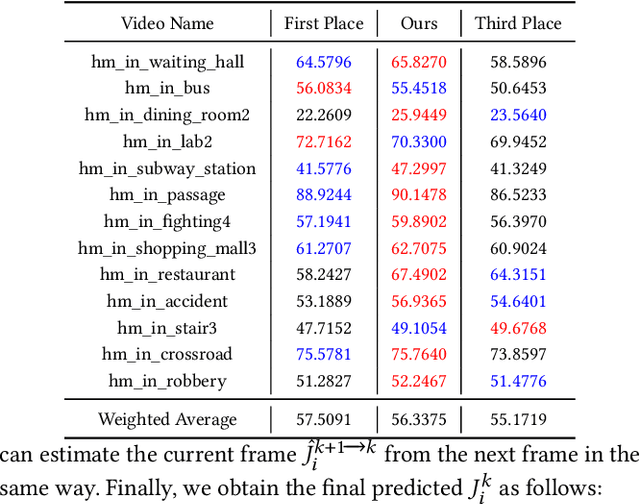
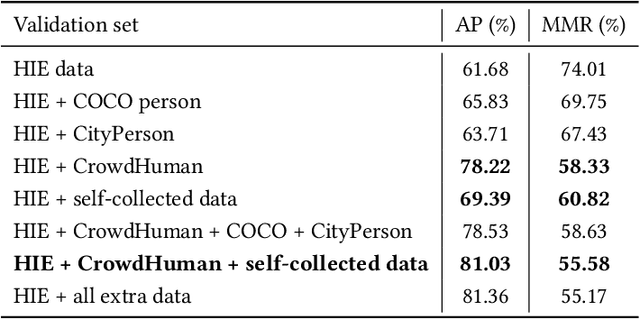
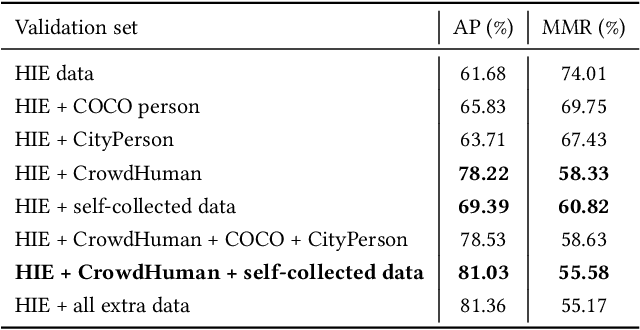
Video-based human pose estimation in crowded scenes is a challenging problem due to occlusion, motion blur, scale variation and viewpoint change, etc. Prior approaches always fail to deal with this problem because of (1) lacking of usage of temporal information; (2) lacking of training data in crowded scenes. In this paper, we focus on improving human pose estimation in videos of crowded scenes from the perspectives of exploiting temporal context and collecting new data. In particular, we first follow the top-down strategy to detect persons and perform single-person pose estimation for each frame. Then, we refine the frame-based pose estimation with temporal contexts deriving from the optical-flow. Specifically, for one frame, we forward the historical poses from the previous frames and backward the future poses from the subsequent frames to current frame, leading to stable and accurate human pose estimation in videos. In addition, we mine new data of similar scenes to HIE dataset from the Internet for improving the diversity of training set. In this way, our model achieves best performance on 7 out of 13 videos and 56.33 average w\_AP on test dataset of HIE challenge.
A Simple Baseline for Pose Tracking in Videos of Crowded Scenes
Oct 21, 2020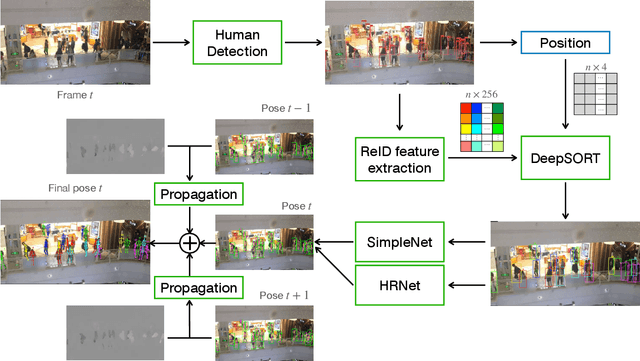
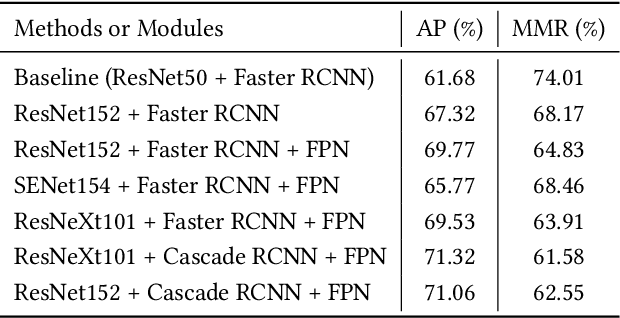

This paper presents our solution to ACM MM challenge: Large-scale Human-centric Video Analysis in Complex Events\cite{lin2020human}; specifically, here we focus on Track3: Crowd Pose Tracking in Complex Events. Remarkable progress has been made in multi-pose training in recent years. However, how to track the human pose in crowded and complex environments has not been well addressed. We formulate the problem as several subproblems to be solved. First, we use a multi-object tracking method to assign human ID to each bounding box generated by the detection model. After that, a pose is generated to each bounding box with ID. At last, optical flow is used to take advantage of the temporal information in the videos and generate the final pose tracking result.
Toward Accurate Person-level Action Recognition in Videos of Crowded Scenes
Oct 16, 2020
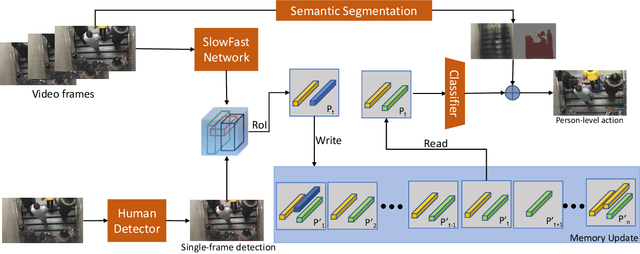

Detecting and recognizing human action in videos with crowded scenes is a challenging problem due to the complex environment and diversity events. Prior works always fail to deal with this problem in two aspects: (1) lacking utilizing information of the scenes; (2) lacking training data in the crowd and complex scenes. In this paper, we focus on improving spatio-temporal action recognition by fully-utilizing the information of scenes and collecting new data. A top-down strategy is used to overcome the limitations. Specifically, we adopt a strong human detector to detect the spatial location of each frame. We then apply action recognition models to learn the spatio-temporal information from video frames on both the HIE dataset and new data with diverse scenes from the internet, which can improve the generalization ability of our model. Besides, the scenes information is extracted by the semantic segmentation model to assistant the process. As a result, our method achieved an average 26.05 wf\_mAP (ranking 1st place in the ACM MM grand challenge 2020: Human in Events).
* 1'st Place in ACM Multimedia Grand Challenge: Human in Events, Track4: Person-level Action Recognition in Complex Events
Dual-constrained Deep Semi-Supervised Coupled Factorization Network with Enriched Prior
Sep 08, 2020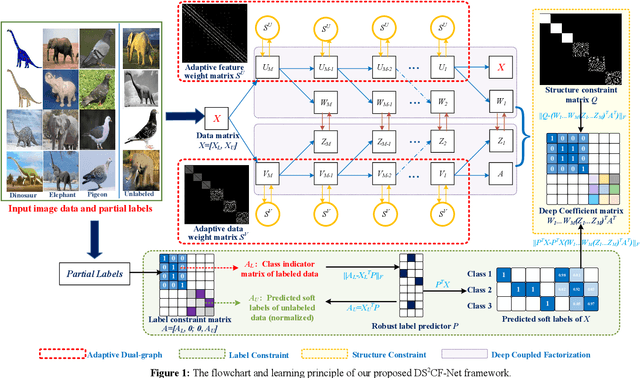
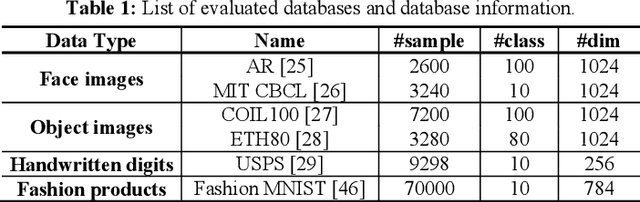
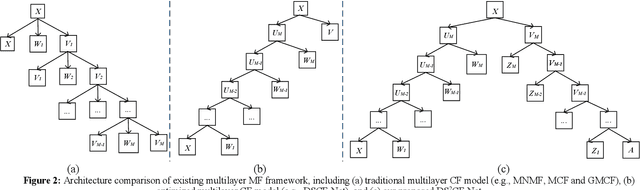
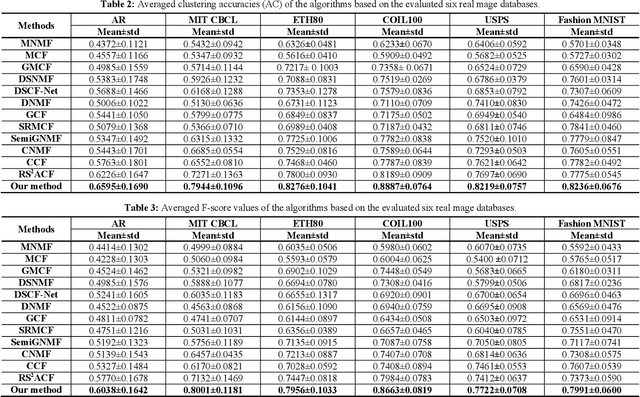
Nonnegative matrix factorization is usually powerful for learning the "shallow" parts-based representation, but it clearly fails to discover deep hierarchical information within both the basis and representation spaces. In this paper, we technically propose a new enriched prior based Dual-constrained Deep Semi-Supervised Coupled Factorization Network, called DS2CF-Net, for learning the hierarchical coupled representations. To ex-tract hidden deep features, DS2CF-Net is modeled as a deep-structure and geometrical structure-constrained neural network. Specifically, DS2CF-Net designs a deep coupled factorization architecture using multi-layers of linear transformations, which coupled updates the bases and new representations in each layer. To improve the discriminating ability of learned deep representations and deep coefficients, our network clearly considers enriching the supervised prior by the joint deep coefficients-regularized label prediction, and incorporates enriched prior information as additional label and structure constraints. The label constraint can enable the samples of the same label to have the same coordinate in the new feature space, while the structure constraint forces the coefficient matrices in each layer to be block-diagonal so that the enhanced prior using the self-expressive label propagation are more accurate. Our network also integrates the adaptive dual-graph learning to retain the local manifold structures of both the data manifold and feature manifold by minimizing the reconstruction errors in each layer. Extensive experiments on several real databases demonstrate that our DS2CF-Net can obtain state-of-the-art performance for representation learning and clustering.
Learning Target Domain Specific Classifier for Partial Domain Adaptation
Aug 25, 2020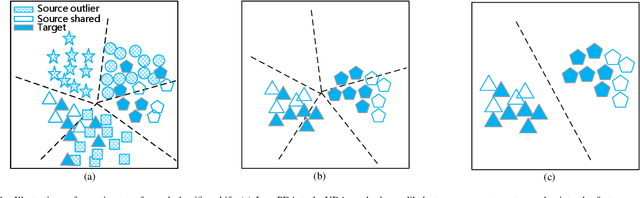
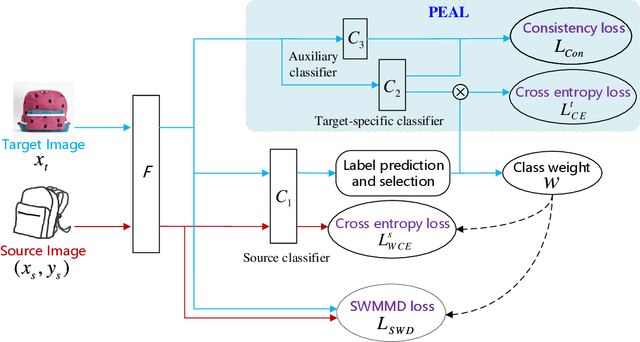
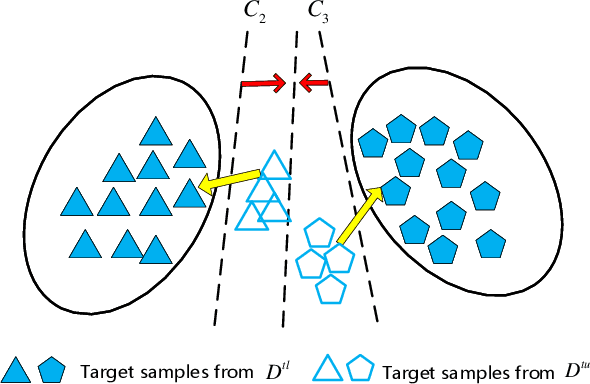

Unsupervised domain adaptation~(UDA) aims at reducing the distribution discrepancy when transferring knowledge from a labeled source domain to an unlabeled target domain. Previous UDA methods assume that the source and target domains share an identical label space, which is unrealistic in practice since the label information of the target domain is agnostic. This paper focuses on a more realistic UDA scenario, i.e. partial domain adaptation (PDA), where the target label space is subsumed to the source label space. In the PDA scenario, the source outliers that are absent in the target domain may be wrongly matched to the target domain (technically named negative transfer), leading to performance degradation of UDA methods. This paper proposes a novel Target Domain Specific Classifier Learning-based Domain Adaptation (TSCDA) method. TSCDA presents a soft-weighed maximum mean discrepancy criterion to partially align feature distributions and alleviate negative transfer. Also, it learns a target-specific classifier for the target domain with pseudo-labels and multiple auxiliary classifiers, to further address classifier shift. A module named Peers Assisted Learning is used to minimize the prediction difference between multiple target-specific classifiers, which makes the classifiers more discriminant for the target domain. Extensive experiments conducted on three PDA benchmark datasets show that TSCDA outperforms other state-of-the-art methods with a large margin, e.g. $4\%$ and $5.6\%$ averagely on Office-31 and Office-Home, respectively.
Dual Adversarial Auto-Encoders for Clustering
Aug 23, 2020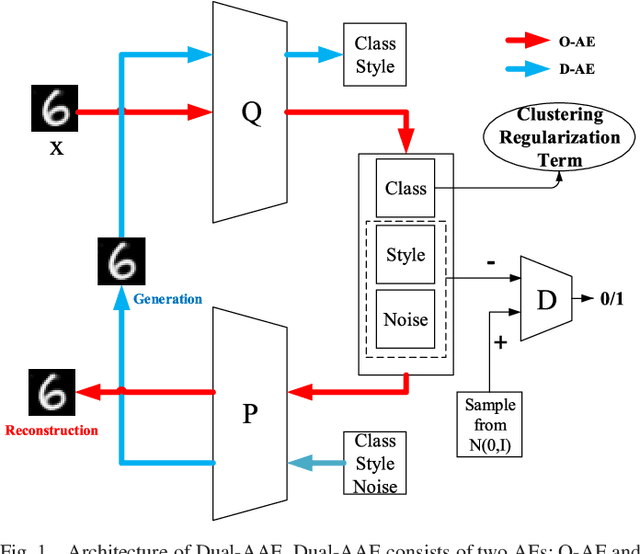
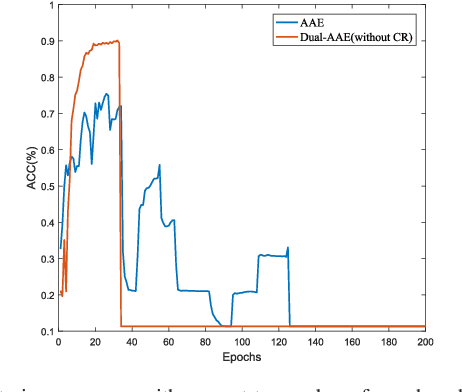
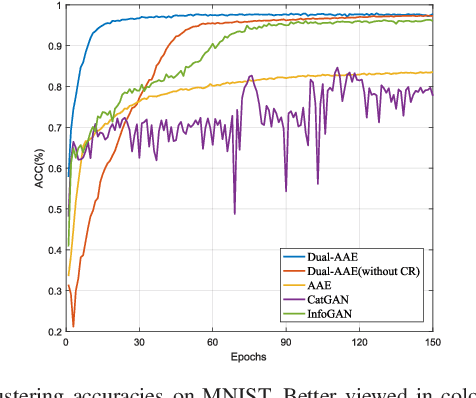

As a powerful approach for exploratory data analysis, unsupervised clustering is a fundamental task in computer vision and pattern recognition. Many clustering algorithms have been developed, but most of them perform unsatisfactorily on the data with complex structures. Recently, Adversarial Auto-Encoder (AAE) shows effectiveness on tackling such data by combining Auto-Encoder (AE) and adversarial training, but it cannot effectively extract classification information from the unlabeled data. In this work, we propose Dual Adversarial Auto-encoder (Dual-AAE) which simultaneously maximizes the likelihood function and mutual information between observed examples and a subset of latent variables. By performing variational inference on the objective function of Dual-AAE, we derive a new reconstruction loss which can be optimized by training a pair of Auto-encoders. Moreover, to avoid mode collapse, we introduce the clustering regularization term for the category variable. Experiments on four benchmarks show that Dual-AAE achieves superior performance over state-of-the-art clustering methods. Besides, by adding a reject option, the clustering accuracy of Dual-AAE can reach that of supervised CNN algorithms. Dual-AAE can also be used for disentangling style and content of images without using supervised information.
ConvBERT: Improving BERT with Span-based Dynamic Convolution
Aug 06, 2020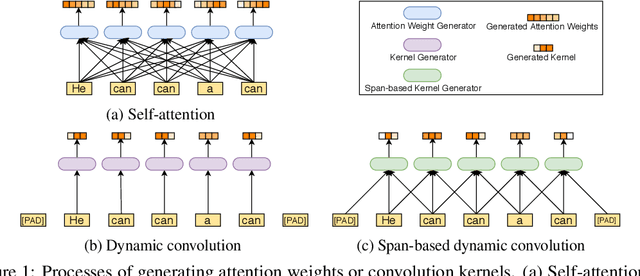
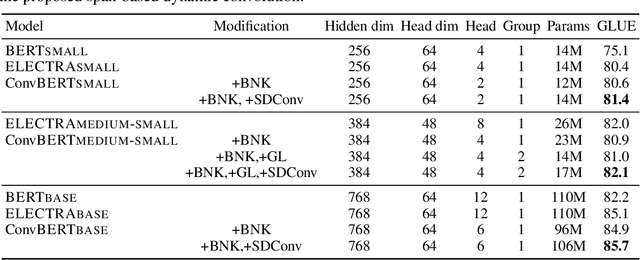
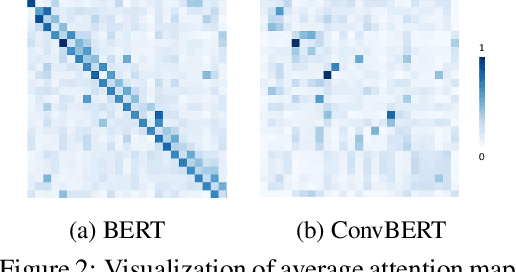
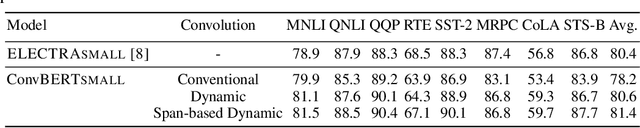
Pre-trained language models like BERT and its variants have recently achieved impressive performance in various natural language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers large memory footprint and computation cost. Although all its attention heads query on the whole input sequence for generating the attention map from a global perspective, we observe some heads only need to learn local dependencies, which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while using less than 1/4 training cost. Code and pre-trained models will be released.
A Survey on Concept Factorization: From Shallow to Deep Representation Learning
Jul 31, 2020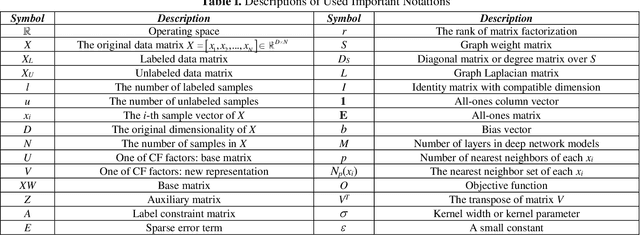
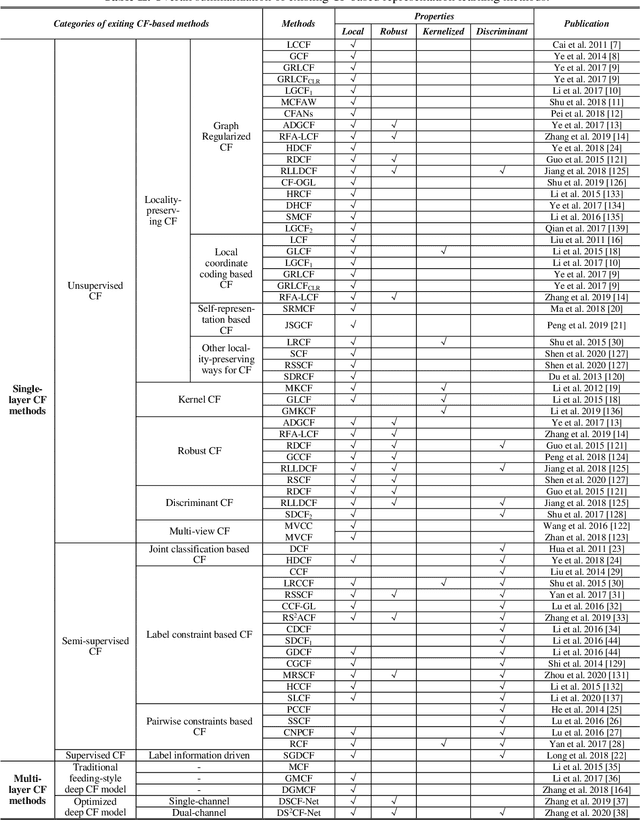
The quality of learned features by representation learning determines the performance of learning algorithms and the related application tasks (such as high-dimensional data clustering). As a relatively new paradigm for representation learning, Concept Factorization (CF) has attracted a great deal of interests in the areas of machine learning and data mining for over a decade. Lots of effective CF based methods have been proposed based on different perspectives and properties, but note that it still remains not easy to grasp the essential connections and figure out the underlying explanatory factors from exiting studies. In this paper, we therefore survey the recent advances on CF methodologies and the potential benchmarks by categorizing and summarizing the current methods. Specifically, we first re-view the root CF method, and then explore the advancement of CF-based representation learning ranging from shallow to deep/multilayer cases. We also introduce the potential application areas of CF-based methods. Finally, we point out some future directions for studying the CF-based representation learning. Overall, this survey provides an insightful overview of both theoretical basis and current developments in the field of CF, which can also help the interested researchers to understand the current trends of CF and find the most appropriate CF techniques to deal with particular applications.
Rethinking Bottleneck Structure for Efficient Mobile Network Design
Jul 07, 2020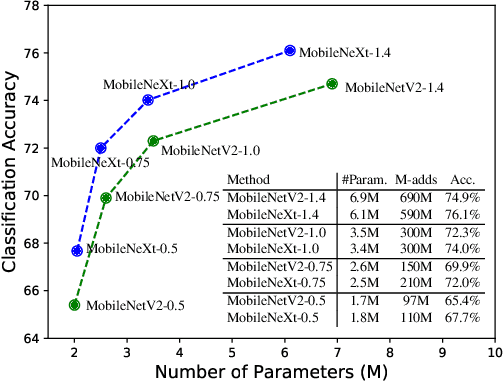

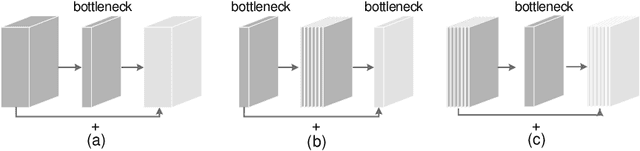
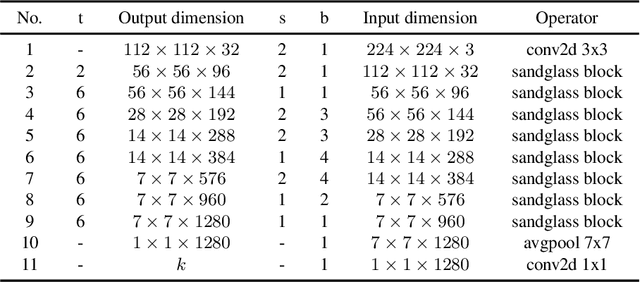
The inverted residual block is dominating architecture design for mobile networks recently. It changes the classic residual bottleneck by introducing two design rules: learning inverted residuals and using linear bottlenecks. In this paper, we rethink the necessity of such design changes and find it may bring risks of information loss and gradient confusion. We thus propose to flip the structure and present a novel bottleneck design, called the sandglass block, that performs identity mapping and spatial transformation at higher dimensions and thus alleviates information loss and gradient confusion effectively. Extensive experiments demonstrate that, different from the common belief, such bottleneck structure is more beneficial than the inverted ones for mobile networks. In ImageNet classification, by simply replacing the inverted residual block with our sandglass block without increasing parameters and computation, the classification accuracy can be improved by more than 1.7% over MobileNetV2. On Pascal VOC 2007 test set, we observe that there is also 0.9% mAP improvement in object detection. We further verify the effectiveness of the sandglass block by adding it into the search space of neural architecture search method DARTS. With 25% parameter reduction, the classification accuracy is improved by 0.13% over previous DARTS models. Code can be found at: https://github.com/zhoudaquan/rethinking_bottleneck_design.
Recapture as You Want
Jun 02, 2020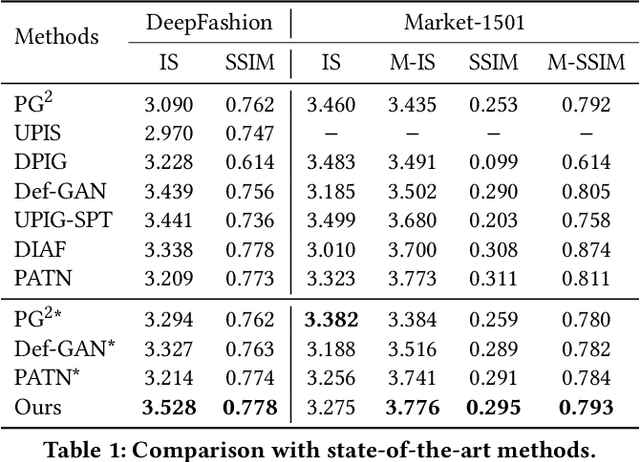
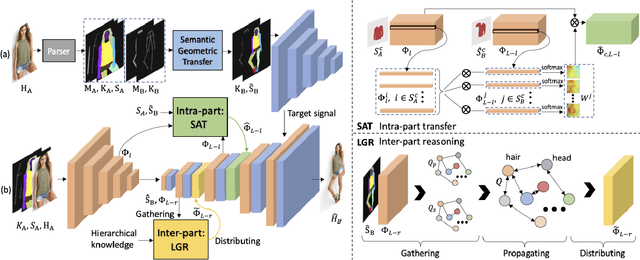

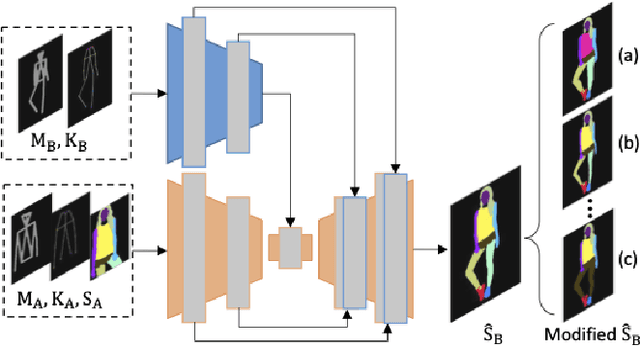
With the increasing prevalence and more powerful camera systems of mobile devices, people can conveniently take photos in their daily life, which naturally brings the demand for more intelligent photo post-processing techniques, especially on those portrait photos. In this paper, we present a portrait recapture method enabling users to easily edit their portrait to desired posture/view, body figure and clothing style, which are very challenging to achieve since it requires to simultaneously perform non-rigid deformation of human body, invisible body-parts reasoning and semantic-aware editing. We decompose the editing procedure into semantic-aware geometric and appearance transformation. In geometric transformation, a semantic layout map is generated that meets user demands to represent part-level spatial constraints and further guides the semantic-aware appearance transformation. In appearance transformation, we design two novel modules, Semantic-aware Attentive Transfer (SAT) and Layout Graph Reasoning (LGR), to conduct intra-part transfer and inter-part reasoning, respectively. SAT module produces each human part by paying attention to the semantically consistent regions in the source portrait. It effectively addresses the non-rigid deformation issue and well preserves the intrinsic structure/appearance with rich texture details. LGR module utilizes body skeleton knowledge to construct a layout graph that connects all relevant part features, where graph reasoning mechanism is used to propagate information among part nodes to mine their relations. In this way, LGR module infers invisible body parts and guarantees global coherence among all the parts. Extensive experiments on DeepFashion, Market-1501 and in-the-wild photos demonstrate the effectiveness and superiority of our approach. Video demo is at: \url{https://youtu.be/vTyq9HL6jgw}.