 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Background Music Generation with Controllable Music Transformer
Nov 16, 2021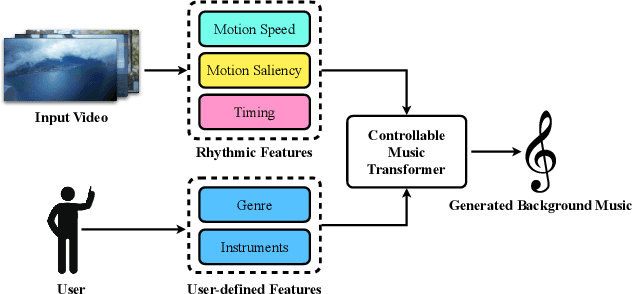
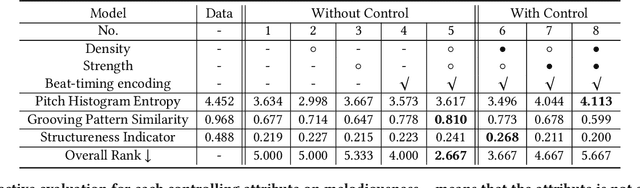
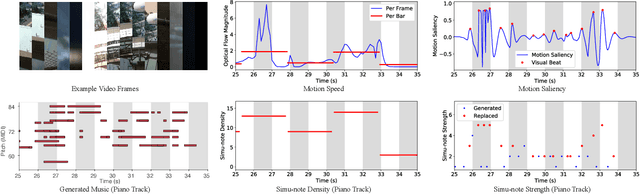
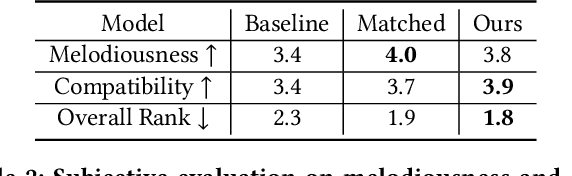
In this work, we address the task of video background music generation. Some previous works achieve effective music generation but are unable to generate melodious music tailored to a particular video, and none of them considers the video-music rhythmic consistency. To generate the background music that matches the given video, we first establish the rhythmic relations between video and background music. In particular, we connect timing, motion speed, and motion saliency from video with beat, simu-note density, and simu-note strength from music, respectively. We then propose CMT, a Controllable Music Transformer that enables local control of the aforementioned rhythmic features and global control of the music genre and instruments. Objective and subjective evaluations show that the generated background music has achieved satisfactory compatibility with the input videos, and at the same time, impressive music quality. Code and models are available at https://github.com/wzk1015/video-bgm-generation.
Deep Long-Tailed Learning: A Survey
Oct 09, 2021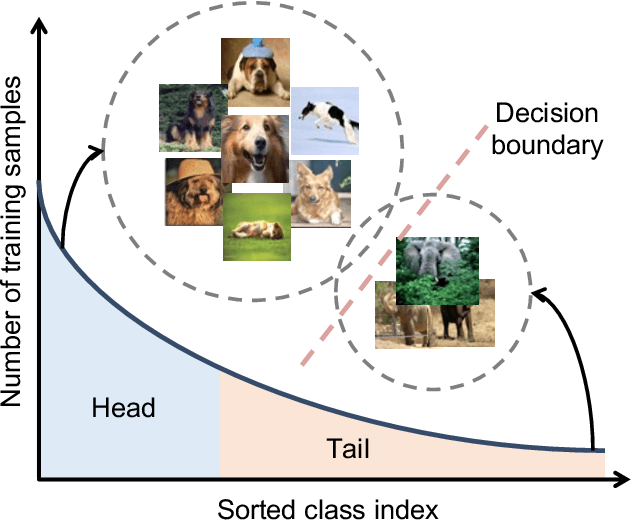
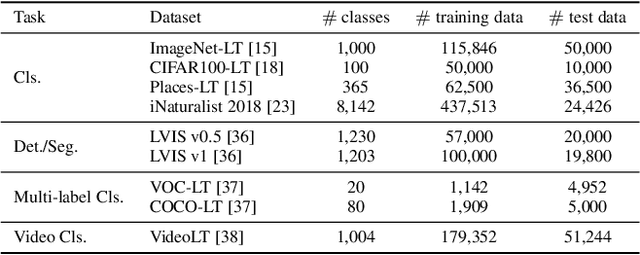
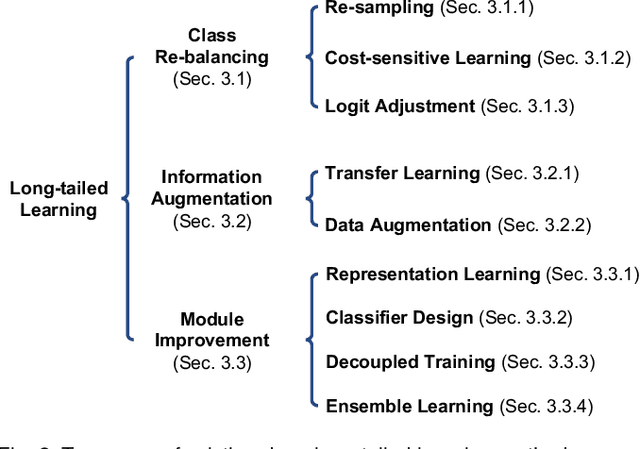
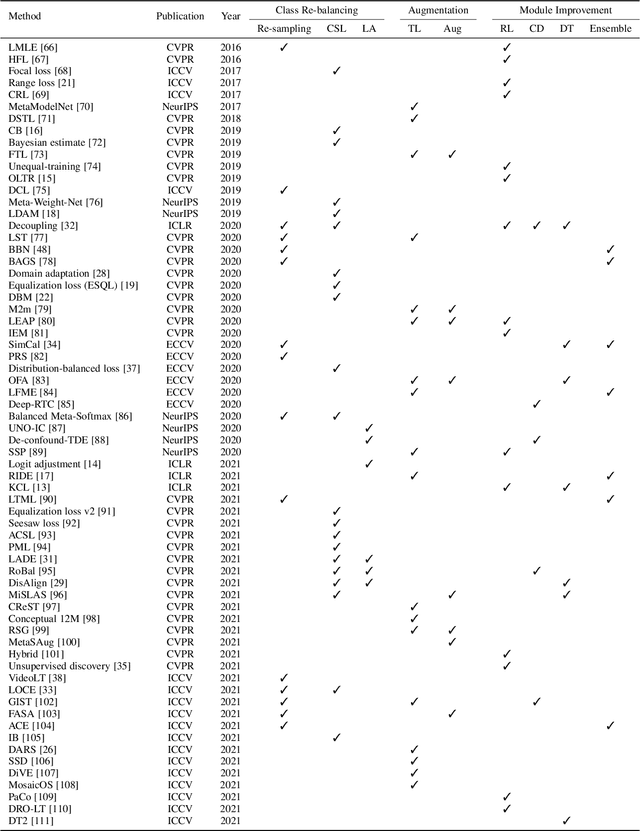
Deep long-tailed learning, one of the most challenging problems in visual recognition, aims to train well-performing deep models from a large number of images that follow a long-tailed class distribution. In the last decade, deep learning has emerged as a powerful recognition model for learning high-quality image representations and has led to remarkable breakthroughs in generic visual recognition. However, long-tailed class imbalance, a common problem in practical visual recognition tasks, often limits the practicality of deep network based recognition models in real-world applications, since they can be easily biased towards dominant classes and perform poorly on tail classes. To address this problem, a large number of studies have been conducted in recent years, making promising progress in the field of deep long-tailed learning. Considering the rapid evolution of this field, this paper aims to provide a comprehensive survey on recent advances in deep long-tailed learning. To be specific, we group existing deep long-tailed learning studies into three main categories (i.e., class re-balancing, information augmentation and module improvement), and review these methods following this taxonomy in detail. Afterward, we empirically analyze several state-of-the-art methods by evaluating to what extent they address the issue of class imbalance via a newly proposed evaluation metric, i.e., relative accuracy. We conclude the survey by highlighting important applications of deep long-tailed learning and identifying several promising directions for future research.
PnP-DETR: Towards Efficient Visual Analysis with Transformers
Sep 16, 2021
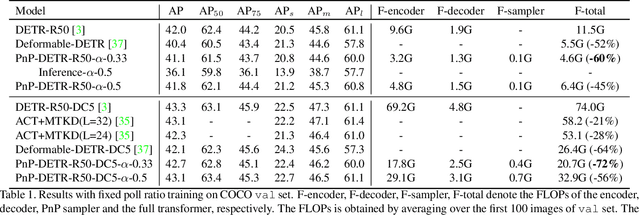
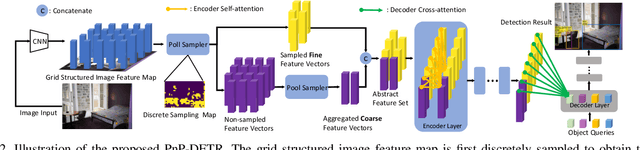

Recently, DETR pioneered the solution of vision tasks with transformers, it directly translates the image feature map into the object detection result. Though effective, translating the full feature map can be costly due to redundant computation on some area like the background. In this work, we encapsulate the idea of reducing spatial redundancy into a novel poll and pool (PnP) sampling module, with which we build an end-to-end PnP-DETR architecture that adaptively allocates its computation spatially to be more efficient. Concretely, the PnP module abstracts the image feature map into fine foreground object feature vectors and a small number of coarse background contextual feature vectors. The transformer models information interaction within the fine-coarse feature space and translates the features into the detection result. Moreover, the PnP-augmented model can instantly achieve various desired trade-offs between performance and computation with a single model by varying the sampled feature length, without requiring to train multiple models as existing methods. Thus it offers greater flexibility for deployment in diverse scenarios with varying computation constraint. We further validate the generalizability of the PnP module on panoptic segmentation and the recent transformer-based image recognition model ViT and show consistent efficiency gain. We believe our method makes a step for efficient visual analysis with transformers, wherein spatial redundancy is commonly observed. Code will be available at \url{https://github.com/twangnh/pnp-detr}.
VOLO: Vision Outlooker for Visual Recognition
Jun 28, 2021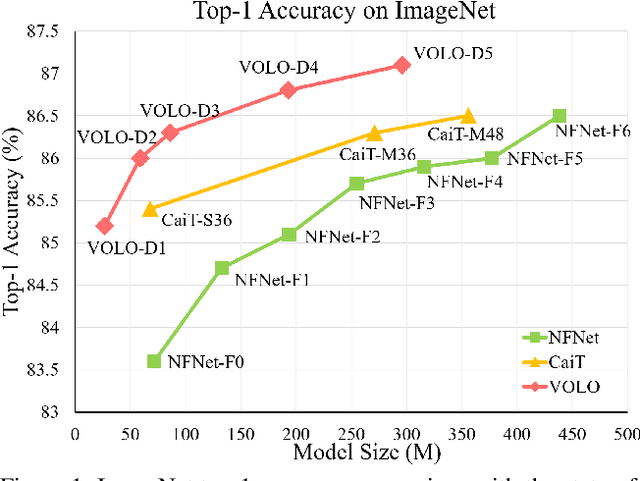
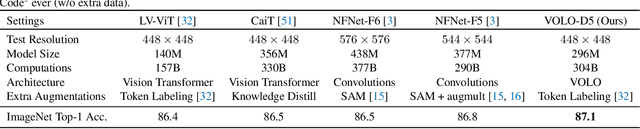
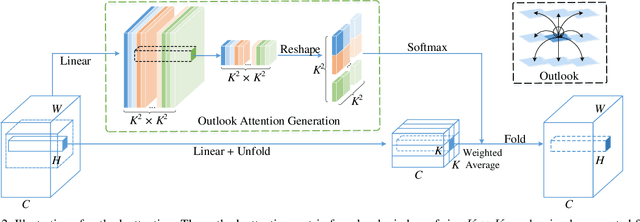

Visual recognition has been dominated by convolutional neural networks (CNNs) for years. Though recently the prevailing vision transformers (ViTs) have shown great potential of self-attention based models in ImageNet classification, their performance is still inferior to that of the latest SOTA CNNs if no extra data are provided. In this work, we try to close the performance gap and demonstrate that attention-based models are indeed able to outperform CNNs. We find a major factor limiting the performance of ViTs for ImageNet classification is their low efficacy in encoding fine-level features into the token representations. To resolve this, we introduce a novel outlook attention and present a simple and general architecture, termed Vision Outlooker (VOLO). Unlike self-attention that focuses on global dependency modeling at a coarse level, the outlook attention efficiently encodes finer-level features and contexts into tokens, which is shown to be critically beneficial to recognition performance but largely ignored by the self-attention. Experiments show that our VOLO achieves 87.1% top-1 accuracy on ImageNet-1K classification, which is the first model exceeding 87% accuracy on this competitive benchmark, without using any extra training data In addition, the pre-trained VOLO transfers well to downstream tasks, such as semantic segmentation. We achieve 84.3% mIoU score on the cityscapes validation set and 54.3% on the ADE20K validation set. Code is available at \url{https://github.com/sail-sg/volo}.
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition
Jun 23, 2021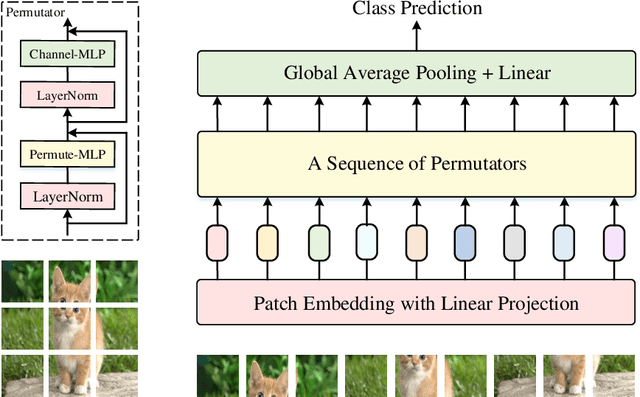
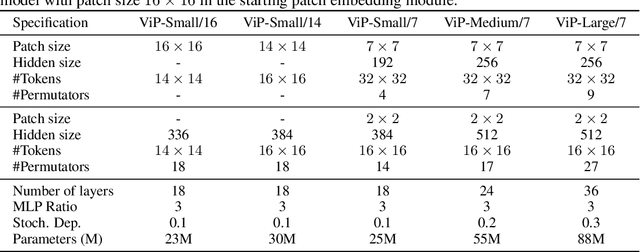
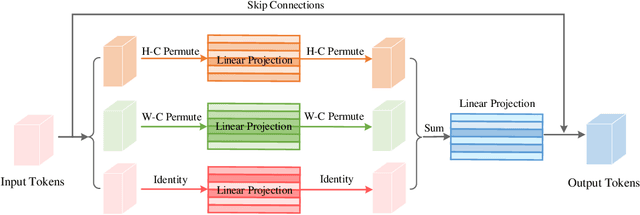
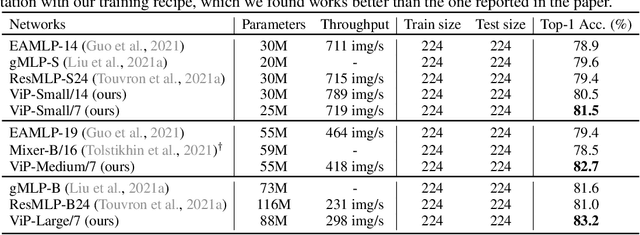
In this paper, we present Vision Permutator, a conceptually simple and data efficient MLP-like architecture for visual recognition. By realizing the importance of the positional information carried by 2D feature representations, unlike recent MLP-like models that encode the spatial information along the flattened spatial dimensions, Vision Permutator separately encodes the feature representations along the height and width dimensions with linear projections. This allows Vision Permutator to capture long-range dependencies along one spatial direction and meanwhile preserve precise positional information along the other direction. The resulting position-sensitive outputs are then aggregated in a mutually complementing manner to form expressive representations of the objects of interest. We show that our Vision Permutators are formidable competitors to convolutional neural networks (CNNs) and vision transformers. Without the dependence on spatial convolutions or attention mechanisms, Vision Permutator achieves 81.5% top-1 accuracy on ImageNet without extra large-scale training data (e.g., ImageNet-22k) using only 25M learnable parameters, which is much better than most CNNs and vision transformers under the same model size constraint. When scaling up to 88M, it attains 83.2% top-1 accuracy. We hope this work could encourage research on rethinking the way of encoding spatial information and facilitate the development of MLP-like models. Code is available at https://github.com/Andrew-Qibin/VisionPermutator.
PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal
May 26, 2021
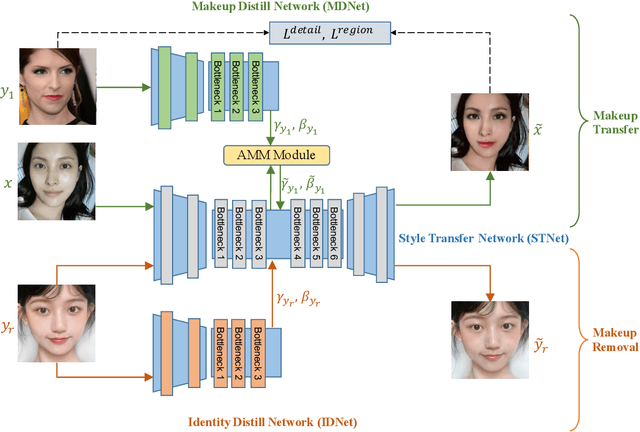
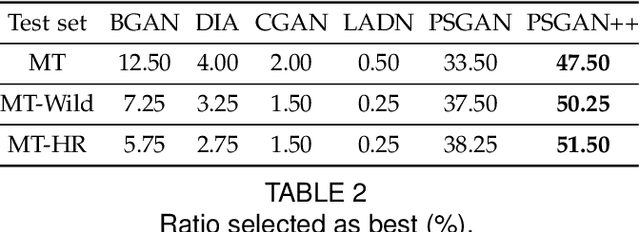
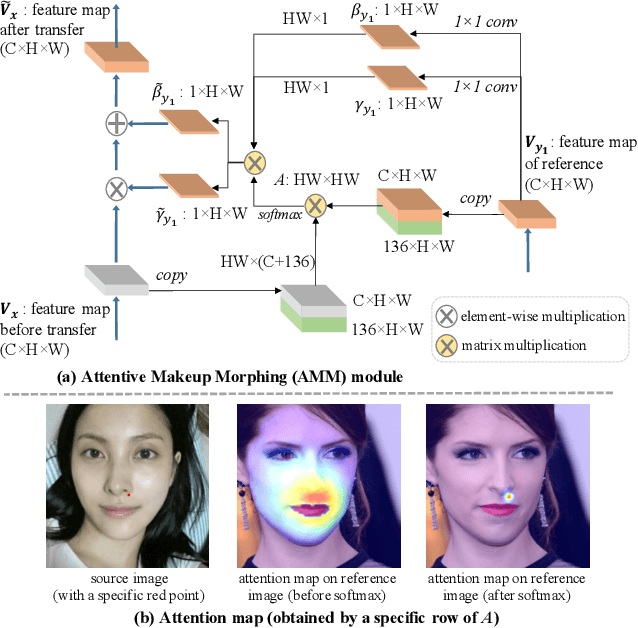
In this paper, we address the makeup transfer and removal tasks simultaneously, which aim to transfer the makeup from a reference image to a source image and remove the makeup from the with-makeup image respectively. Existing methods have achieved much advancement in constrained scenarios, but it is still very challenging for them to transfer makeup between images with large pose and expression differences, or handle makeup details like blush on cheeks or highlight on the nose. In addition, they are hardly able to control the degree of makeup during transferring or to transfer a specified part in the input face. In this work, we propose the PSGAN++, which is capable of performing both detail-preserving makeup transfer and effective makeup removal. For makeup transfer, PSGAN++ uses a Makeup Distill Network to extract makeup information, which is embedded into spatial-aware makeup matrices. We also devise an Attentive Makeup Morphing module that specifies how the makeup in the source image is morphed from the reference image, and a makeup detail loss to supervise the model within the selected makeup detail area. On the other hand, for makeup removal, PSGAN++ applies an Identity Distill Network to embed the identity information from with-makeup images into identity matrices. Finally, the obtained makeup/identity matrices are fed to a Style Transfer Network that is able to edit the feature maps to achieve makeup transfer or removal. To evaluate the effectiveness of our PSGAN++, we collect a Makeup Transfer In the Wild dataset that contains images with diverse poses and expressions and a Makeup Transfer High-Resolution dataset that contains high-resolution images. Experiments demonstrate that PSGAN++ not only achieves state-of-the-art results with fine makeup details even in cases of large pose/expression differences but also can perform partial or degree-controllable makeup transfer.
Human-centric Relation Segmentation: Dataset and Solution
May 25, 2021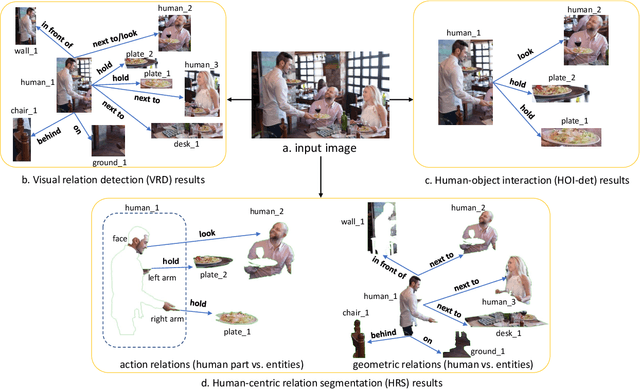

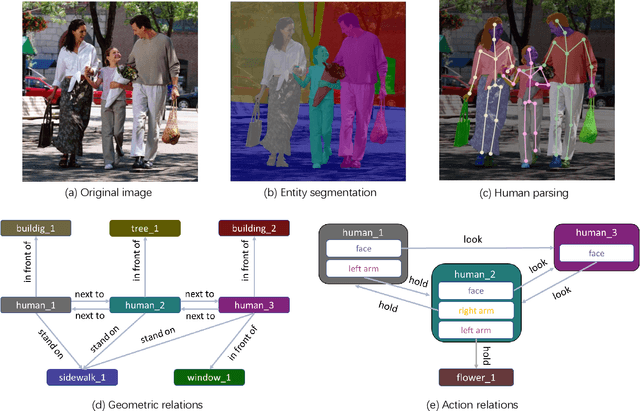
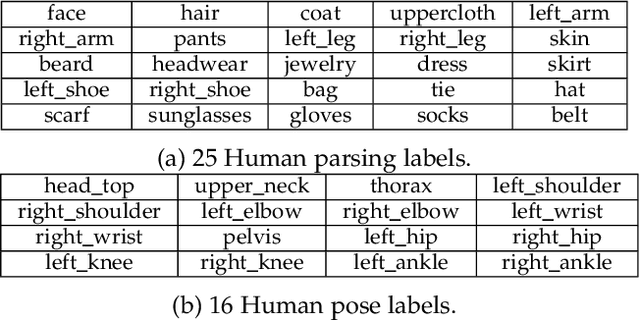
Vision and language understanding techniques have achieved remarkable progress, but currently it is still difficult to well handle problems involving very fine-grained details. For example, when the robot is told to "bring me the book in the girl's left hand", most existing methods would fail if the girl holds one book respectively in her left and right hand. In this work, we introduce a new task named human-centric relation segmentation (HRS), as a fine-grained case of HOI-det. HRS aims to predict the relations between the human and surrounding entities and identify the relation-correlated human parts, which are represented as pixel-level masks. For the above exemplar case, our HRS task produces results in the form of relation triplets <girl [left hand], hold, book> and exacts segmentation masks of the book, with which the robot can easily accomplish the grabbing task. Correspondingly, we collect a new Person In Context (PIC) dataset for this new task, which contains 17,122 high-resolution images and densely annotated entity segmentation and relations, including 141 object categories, 23 relation categories and 25 semantic human parts. We also propose a Simultaneous Matching and Segmentation (SMS) framework as a solution to the HRS task. I Outputs of the three branches are fused to produce the final HRS results. Extensive experiments on PIC and V-COCO datasets show that the proposed SMS method outperforms baselines with the 36 FPS inference speed.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Jan 28, 2021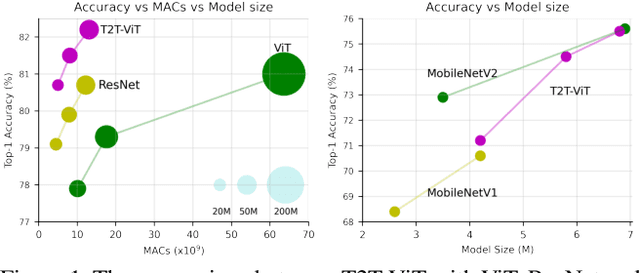
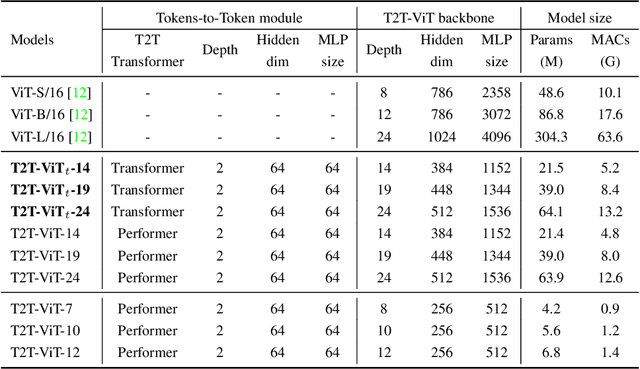

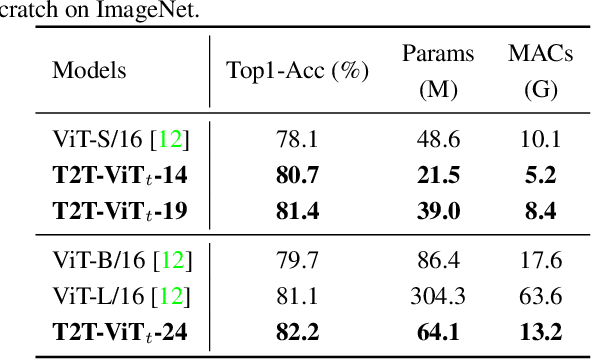
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformers (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance compared with CNNs when trained from scratch on a midsize dataset (e.g., ImageNet). We find it is because: 1) the simple tokenization of input images fails to model the important local structure (e.g., edges, lines) among neighboring pixels, leading to its low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness in fixed computation budgets and limited training samples. To overcome such limitations, we propose a new Tokens-To-Token Vision Transformers (T2T-ViT), which introduces 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study. Notably, T2T-ViT reduces the parameter counts and MACs of vanilla ViT by 200\%, while achieving more than 2.5\% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets when directly training on ImageNet. For example, T2T-ViT with ResNet50 comparable size can achieve 80.7\% top-1 accuracy on ImageNet. (Code: https://github.com/yitu-opensource/T2T-ViT)
ORDNet: Capturing Omni-Range Dependencies for Scene Parsing
Jan 11, 2021
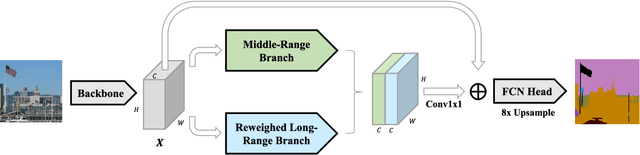
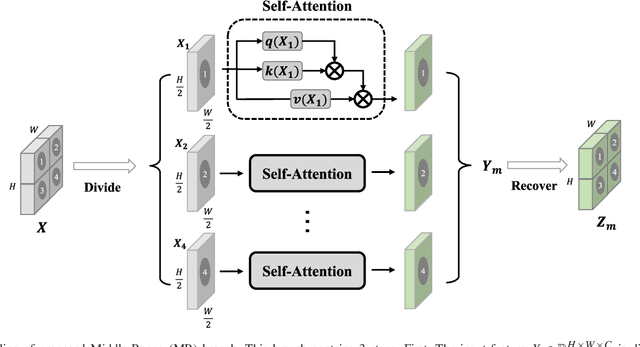
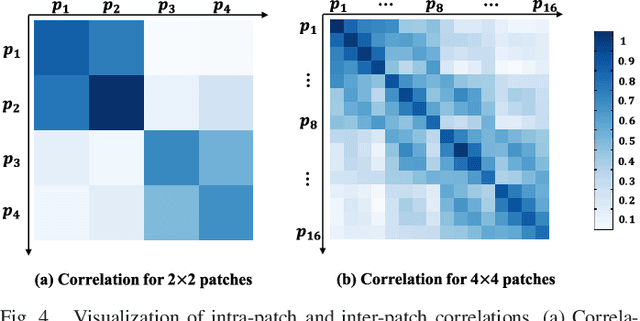
Learning to capture dependencies between spatial positions is essential to many visual tasks, especially the dense labeling problems like scene parsing. Existing methods can effectively capture long-range dependencies with self-attention mechanism while short ones by local convolution. However, there is still much gap between long-range and short-range dependencies, which largely reduces the models' flexibility in application to diverse spatial scales and relationships in complicated natural scene images. To fill such a gap, we develop a Middle-Range (MR) branch to capture middle-range dependencies by restricting self-attention into local patches. Also, we observe that the spatial regions which have large correlations with others can be emphasized to exploit long-range dependencies more accurately, and thus propose a Reweighed Long-Range (RLR) branch. Based on the proposed MR and RLR branches, we build an Omni-Range Dependencies Network (ORDNet) which can effectively capture short-, middle- and long-range dependencies. Our ORDNet is able to extract more comprehensive context information and well adapt to complex spatial variance in scene images. Extensive experiments show that our proposed ORDNet outperforms previous state-of-the-art methods on three scene parsing benchmarks including PASCAL Context, COCO Stuff and ADE20K, demonstrating the superiority of capturing omni-range dependencies in deep models for scene parsing task.
* Published at TIP
ProxylessKD: Direct Knowledge Distillation with Inherited Classifier for Face Recognition
Oct 31, 2020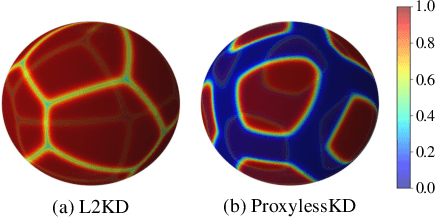
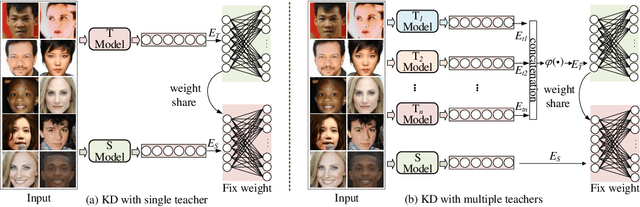
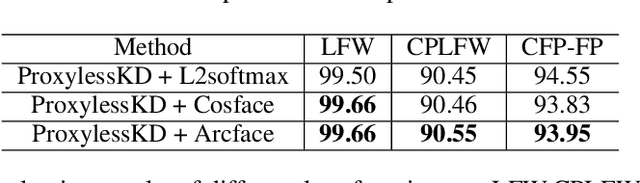
Knowledge Distillation (KD) refers to transferring knowledge from a large model to a smaller one, which is widely used to enhance model performance in machine learning. It tries to align embedding spaces generated from the teacher and the student model (i.e. to make images corresponding to the same semantics share the same embedding across different models). In this work, we focus on its application in face recognition. We observe that existing knowledge distillation models optimize the proxy tasks that force the student to mimic the teacher's behavior, instead of directly optimizing the face recognition accuracy. Consequently, the obtained student models are not guaranteed to be optimal on the target task or able to benefit from advanced constraints, such as large margin constraints (e.g. margin-based softmax). We then propose a novel method named ProxylessKD that directly optimizes face recognition accuracy by inheriting the teacher's classifier as the student's classifier to guide the student to learn discriminative embeddings in the teacher's embedding space. The proposed ProxylessKD is very easy to implement and sufficiently generic to be extended to other tasks beyond face recognition. We conduct extensive experiments on standard face recognition benchmarks, and the results demonstrate that ProxylessKD achieves superior performance over existing knowledge distillation methods.