 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPAIR: Gaussian-Kernel-Based Ultrafast 3D Photoacoustic Iterative Reconstruction
Feb 03, 2026Although the iterative reconstruction (IR) algorithm can substantially correct reconstruction artifacts in photoacoustic (PA) computed tomography (PACT), it suffers from long reconstruction times, especially for large-scale three-dimensional (3D) imaging in which IR takes hundreds of seconds to hours. The computing burden severely limits the practical applicability of IR algorithms. In this work, we proposed an ultrafast IR method for 3D PACT, called Gaussian-kernel-based Ultrafast 3D Photoacoustic Iterative Reconstruction (GPAIR), which achieves orders-of-magnitude acceleration in computing. GPAIR transforms traditional spatial grids with continuous isotropic Gaussian kernels. By deriving analytical closed-form expression for pressure waves and implementing powerful GPU-accelerated differentiable Triton operators, GPAIR demonstrates extraordinary ultrafast sub-second reconstruction speed for 3D targets containing 8.4 million voxels in animal experiments. This revolutionary ultrafast image reconstruction enables near-real-time large-scale 3D PA reconstruction, significantly advancing 3D PACT toward clinical applications.
StoTAM: Stochastic Alternating Minimization for Tucker-Structured Tensor Sensing
Jan 20, 2026Low-rank tensor sensing is a fundamental problem with broad applications in signal processing and machine learning. Among various tensor models, low-Tucker-rank tensors are particularly attractive for capturing multi-mode subspace structures in high-dimensional data. Existing recovery methods either operate on the full tensor variable with expensive tensor projections, or adopt factorized formulations that still rely on full-gradient computations, while most stochastic factorized approaches are restricted to tensor decomposition settings. In this work, we propose a stochastic alternating minimization algorithm that operates directly on the core tensor and factor matrices under a Tucker factorization. The proposed method avoids repeated tensor projections and enables efficient mini-batch updates on low-dimensional tensor factors. Numerical experiments on synthetic tensor sensing demonstrate that the proposed algorithm exhibits favorable convergence behavior in wall-clock time compared with representative stochastic tensor recovery baselines.
VirtualEnv: A Platform for Embodied AI Research
Jan 12, 2026As large language models (LLMs) continue to improve in reasoning and decision-making, there is a growing need for realistic and interactive environments where their abilities can be rigorously evaluated. We present VirtualEnv, a next-generation simulation platform built on Unreal Engine 5 that enables fine-grained benchmarking of LLMs in embodied and interactive scenarios. VirtualEnv supports rich agent-environment interactions, including object manipulation, navigation, and adaptive multi-agent collaboration, as well as game-inspired mechanics like escape rooms and procedurally generated environments. We provide a user-friendly API built on top of Unreal Engine, allowing researchers to deploy and control LLM-driven agents using natural language instructions. We integrate large-scale LLMs and vision-language models (VLMs), such as GPT-based models, to generate novel environments and structured tasks from multimodal inputs. Our experiments benchmark the performance of several popular LLMs across tasks of increasing complexity, analyzing differences in adaptability, planning, and multi-agent coordination. We also describe our methodology for procedural task generation, task validation, and real-time environment control. VirtualEnv is released as an open-source platform, we aim to advance research at the intersection of AI and gaming, enable standardized evaluation of LLMs in embodied AI settings, and pave the way for future developments in immersive simulations and interactive entertainment.
DeepHalo: A Neural Choice Model with Controllable Context Effects
Jan 08, 2026Modeling human decision-making is central to applications such as recommendation, preference learning, and human-AI alignment. While many classic models assume context-independent choice behavior, a large body of behavioral research shows that preferences are often influenced by the composition of the choice set itself -- a phenomenon known as the context effect or Halo effect. These effects can manifest as pairwise (first-order) or even higher-order interactions among the available alternatives. Recent models that attempt to capture such effects either focus on the featureless setting or, in the feature-based setting, rely on restrictive interaction structures or entangle interactions across all orders, which limits interpretability. In this work, we propose DeepHalo, a neural modeling framework that incorporates features while enabling explicit control over interaction order and principled interpretation of context effects. Our model enables systematic identification of interaction effects by order and serves as a universal approximator of context-dependent choice functions when specialized to a featureless setting. Experiments on synthetic and real-world datasets demonstrate strong predictive performance while providing greater transparency into the drivers of choice.
SlingBAG Pro: Accelerating point cloud-based iterative reconstruction for 3D photoacoustic imaging with arbitrary array geometries
Jan 06, 2026High-quality three-dimensional (3D) photoacoustic imaging (PAI) is gaining increasing attention in clinical applications. To address the challenges of limited space and high costs, irregular geometric transducer arrays that conform to specific imaging regions are promising for achieving high-quality 3D PAI with fewer transducers. However, traditional iterative reconstruction algorithms struggle with irregular array configurations, suffering from high computational complexity, substantial memory requirements, and lengthy reconstruction times. In this work, we introduce SlingBAG Pro, an advanced reconstruction algorithm based on the point cloud iteration concept of the Sliding ball adaptive growth (SlingBAG) method, while extending its compatibility to arbitrary array geometries. SlingBAG Pro maintains high reconstruction quality, reduces the number of required transducers, and employs a hierarchical optimization strategy that combines zero-gradient filtering with progressively increased temporal sampling rates during iteration. This strategy rapidly removes redundant spatial point clouds, accelerates convergence, and significantly shortens overall reconstruction time. Compared to the original SlingBAG algorithm, SlingBAG Pro achieves up to a 2.2-fold speed improvement in point cloud-based 3D PA reconstruction under irregular array geometries. The proposed method is validated through both simulation and in vivo mouse experiments, and the source code is publicly available at https://github.com/JaegerCQ/SlingBAG_Pro.
Hierarchical Prompt Learning for Image- and Text-Based Person Re-Identification
Nov 17, 2025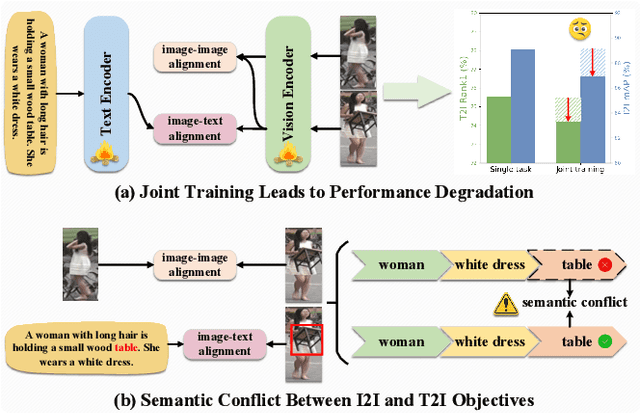
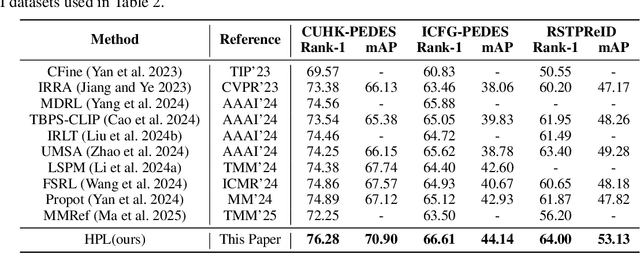
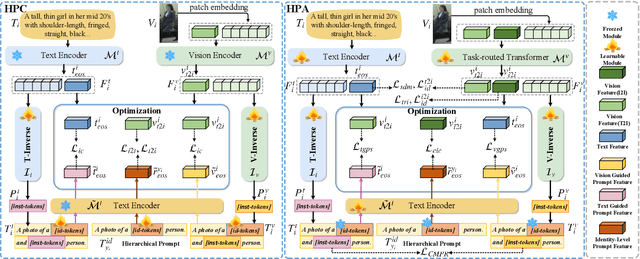
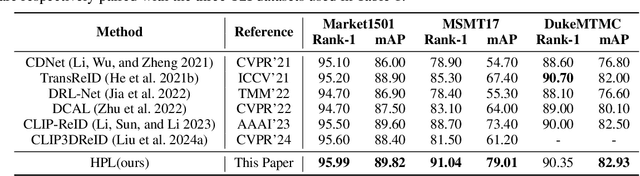
Person re-identification (ReID) aims to retrieve target pedestrian images given either visual queries (image-to-image, I2I) or textual descriptions (text-to-image, T2I). Although both tasks share a common retrieval objective, they pose distinct challenges: I2I emphasizes discriminative identity learning, while T2I requires accurate cross-modal semantic alignment. Existing methods often treat these tasks separately, which may lead to representation entanglement and suboptimal performance. To address this, we propose a unified framework named Hierarchical Prompt Learning (HPL), which leverages task-aware prompt modeling to jointly optimize both tasks. Specifically, we first introduce a Task-Routed Transformer, which incorporates dual classification tokens into a shared visual encoder to route features for I2I and T2I branches respectively. On top of this, we develop a hierarchical prompt generation scheme that integrates identity-level learnable tokens with instance-level pseudo-text tokens. These pseudo-tokens are derived from image or text features via modality-specific inversion networks, injecting fine-grained, instance-specific semantics into the prompts. Furthermore, we propose a Cross-Modal Prompt Regularization strategy to enforce semantic alignment in the prompt token space, ensuring that pseudo-prompts preserve source-modality characteristics while enhancing cross-modal transferability. Extensive experiments on multiple ReID benchmarks validate the effectiveness of our method, achieving state-of-the-art performance on both I2I and T2I tasks.
DINOv2 Driven Gait Representation Learning for Video-Based Visible-Infrared Person Re-identification
Nov 06, 2025Video-based Visible-Infrared person re-identification (VVI-ReID) aims to retrieve the same pedestrian across visible and infrared modalities from video sequences. Existing methods tend to exploit modality-invariant visual features but largely overlook gait features, which are not only modality-invariant but also rich in temporal dynamics, thus limiting their ability to model the spatiotemporal consistency essential for cross-modal video matching. To address these challenges, we propose a DINOv2-Driven Gait Representation Learning (DinoGRL) framework that leverages the rich visual priors of DINOv2 to learn gait features complementary to appearance cues, facilitating robust sequence-level representations for cross-modal retrieval. Specifically, we introduce a Semantic-Aware Silhouette and Gait Learning (SASGL) model, which generates and enhances silhouette representations with general-purpose semantic priors from DINOv2 and jointly optimizes them with the ReID objective to achieve semantically enriched and task-adaptive gait feature learning. Furthermore, we develop a Progressive Bidirectional Multi-Granularity Enhancement (PBMGE) module, which progressively refines feature representations by enabling bidirectional interactions between gait and appearance streams across multiple spatial granularities, fully leveraging their complementarity to enhance global representations with rich local details and produce highly discriminative features. Extensive experiments on HITSZ-VCM and BUPT datasets demonstrate the superiority of our approach, significantly outperforming existing state-of-the-art methods.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Geometry-aware 4D Video Generation for Robot Manipulation
Jul 01, 2025Understanding and predicting the dynamics of the physical world can enhance a robot's ability to plan and interact effectively in complex environments. While recent video generation models have shown strong potential in modeling dynamic scenes, generating videos that are both temporally coherent and geometrically consistent across camera views remains a significant challenge. To address this, we propose a 4D video generation model that enforces multi-view 3D consistency of videos by supervising the model with cross-view pointmap alignment during training. This geometric supervision enables the model to learn a shared 3D representation of the scene, allowing it to predict future video sequences from novel viewpoints based solely on the given RGB-D observations, without requiring camera poses as inputs. Compared to existing baselines, our method produces more visually stable and spatially aligned predictions across multiple simulated and real-world robotic datasets. We further show that the predicted 4D videos can be used to recover robot end-effector trajectories using an off-the-shelf 6DoF pose tracker, supporting robust robot manipulation and generalization to novel camera viewpoints.
From Local Details to Global Context: Advancing Vision-Language Models with Attention-Based Selection
May 19, 2025Pretrained vision-language models (VLMs), e.g., CLIP, demonstrate impressive zero-shot capabilities on downstream tasks. Prior research highlights the crucial role of visual augmentation techniques, like random cropping, in alignment with fine-grained class descriptions generated by large language models (LLMs), significantly enhancing zero-shot performance by incorporating multi-view information. However, the inherent randomness of these augmentations can inevitably introduce background artifacts and cause models to overly focus on local details, compromising global semantic understanding. To address these issues, we propose an \textbf{A}ttention-\textbf{B}ased \textbf{S}election (\textbf{ABS}) method from local details to global context, which applies attention-guided cropping in both raw images and feature space, supplement global semantic information through strategic feature selection. Additionally, we introduce a soft matching technique to effectively filter LLM descriptions for better alignment. \textbf{ABS} achieves state-of-the-art performance on out-of-distribution generalization and zero-shot classification tasks. Notably, \textbf{ABS} is training-free and even rivals few-shot and test-time adaptation methods. Our code is available at \href{https://github.com/BIT-DA/ABS}{\textcolor{darkgreen}{https://github.com/BIT-DA/ABS}}.