 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-parameter Adaptation of Conformer ASR Systems for Elderly and Dysarthric Speech Recognition
Jun 27, 2023Automatic recognition of disordered and elderly speech remains highly challenging tasks to date due to data scarcity. Parameter fine-tuning is often used to exploit the large quantities of non-aged and healthy speech pre-trained models, while neural architecture hyper-parameters are set using expert knowledge and remain unchanged. This paper investigates hyper-parameter adaptation for Conformer ASR systems that are pre-trained on the Librispeech corpus before being domain adapted to the DementiaBank elderly and UASpeech dysarthric speech datasets. Experimental results suggest that hyper-parameter adaptation produced word error rate (WER) reductions of 0.45% and 0.67% over parameter-only fine-tuning on DBank and UASpeech tasks respectively. An intuitive correlation is found between the performance improvements by hyper-parameter domain adaptation and the relative utterance length ratio between the source and target domain data.
ConsistentNeRF: Enhancing Neural Radiance Fields with 3D Consistency for Sparse View Synthesis
May 18, 2023Neural Radiance Fields (NeRF) has demonstrated remarkable 3D reconstruction capabilities with dense view images. However, its performance significantly deteriorates under sparse view settings. We observe that learning the 3D consistency of pixels among different views is crucial for improving reconstruction quality in such cases. In this paper, we propose ConsistentNeRF, a method that leverages depth information to regularize both multi-view and single-view 3D consistency among pixels. Specifically, ConsistentNeRF employs depth-derived geometry information and a depth-invariant loss to concentrate on pixels that exhibit 3D correspondence and maintain consistent depth relationships. Extensive experiments on recent representative works reveal that our approach can considerably enhance model performance in sparse view conditions, achieving improvements of up to 94% in PSNR, 76% in SSIM, and 31% in LPIPS compared to the vanilla baselines across various benchmarks, including DTU, NeRF Synthetic, and LLFF.
SHERF: Generalizable Human NeRF from a Single Image
Mar 22, 2023Existing Human NeRF methods for reconstructing 3D humans typically rely on multiple 2D images from multi-view cameras or monocular videos captured from fixed camera views. However, in real-world scenarios, human images are often captured from random camera angles, presenting challenges for high-quality 3D human reconstruction. In this paper, we propose SHERF, the first generalizable Human NeRF model for recovering animatable 3D humans from a single input image. SHERF extracts and encodes 3D human representations in canonical space, enabling rendering and animation from free views and poses. To achieve high-fidelity novel view and pose synthesis, the encoded 3D human representations should capture both global appearance and local fine-grained textures. To this end, we propose a bank of 3D-aware hierarchical features, including global, point-level, and pixel-aligned features, to facilitate informative encoding. Global features enhance the information extracted from the single input image and complement the information missing from the partial 2D observation. Point-level features provide strong clues of 3D human structure, while pixel-aligned features preserve more fine-grained details. To effectively integrate the 3D-aware hierarchical feature bank, we design a feature fusion transformer. Extensive experiments on THuman, RenderPeople, ZJU_MoCap, and HuMMan datasets demonstrate that SHERF achieves state-of-the-art performance, with better generalizability for novel view and pose synthesis.
Exploiting prompt learning with pre-trained language models for Alzheimer's Disease detection
Oct 29, 2022Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care and to delay further progression. Speech based automatic AD screening systems provide a non-intrusive and more scalable alternative to other clinical screening techniques. Textual embedding features produced by pre-trained language models (PLMs) such as BERT are widely used in such systems. However, PLM domain fine-tuning is commonly based on the masked word or sentence prediction costs that are inconsistent with the back-end AD detection task. To this end, this paper investigates the use of prompt-based fine-tuning of PLMs that consistently uses AD classification errors as the training objective function. Disfluency features based on hesitation or pause filler token frequencies are further incorporated into prompt phrases during PLM fine-tuning. The exploit of the complementarity between BERT or RoBERTa based PLMs that are either prompt learning fine-tuned, or optimized using conventional masked word or sentence prediction costs, decision voting based system combination between them is further applied. Mean, standard deviation and the maximum among accuracy scores over 15 experiment runs are adopted as performance measurements for the AD detection system. Mean detection accuracy of 84.20% (with std 2.09%, best 87.5%) and 82.64% (with std 4.0%, best 89.58%) were obtained using manual and ASR speech transcripts respectively on the ADReSS20 test set consisting of 48 elderly speakers.
Bayesian Neural Network Language Modeling for Speech Recognition
Aug 28, 2022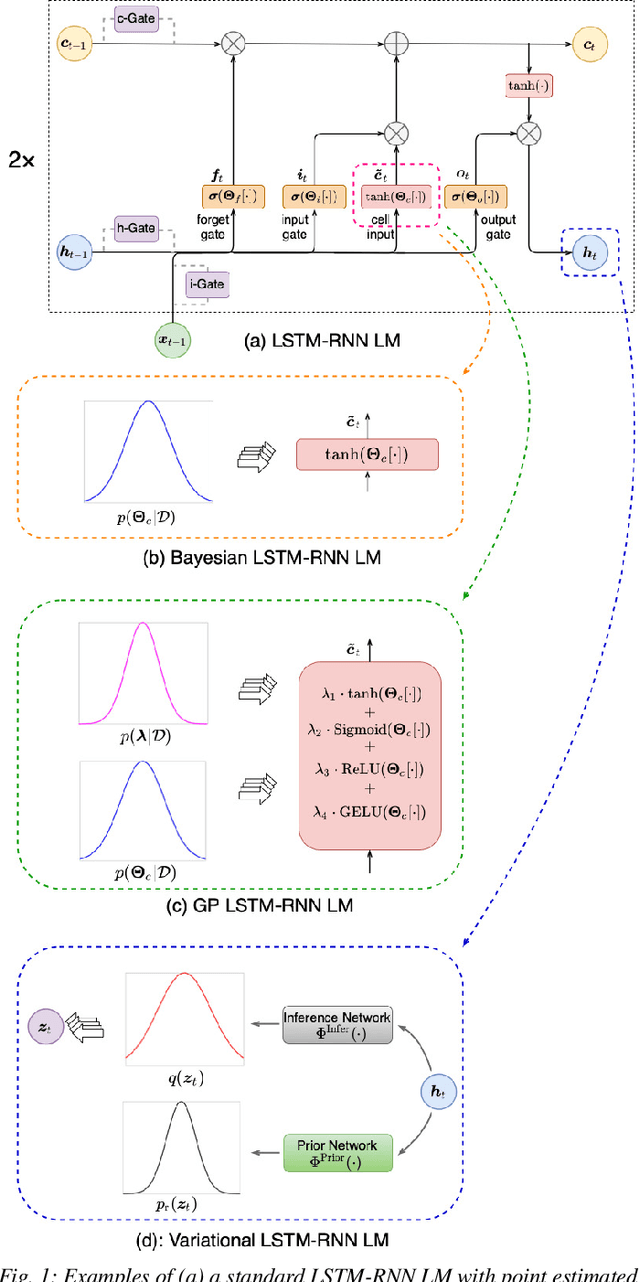
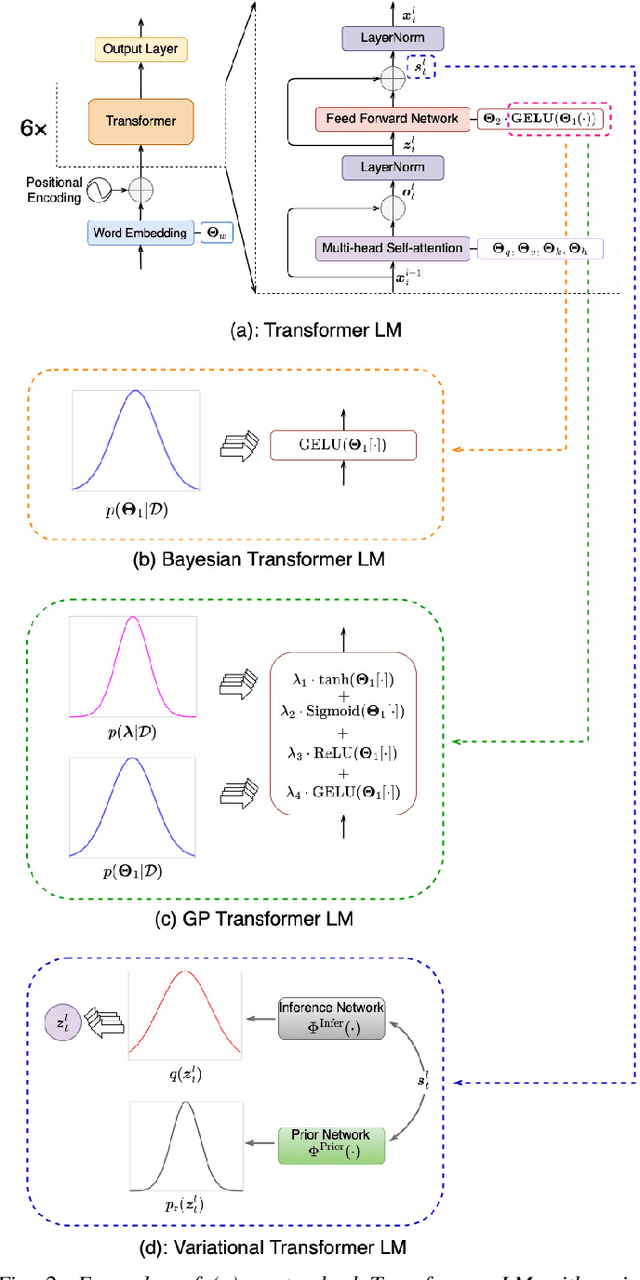
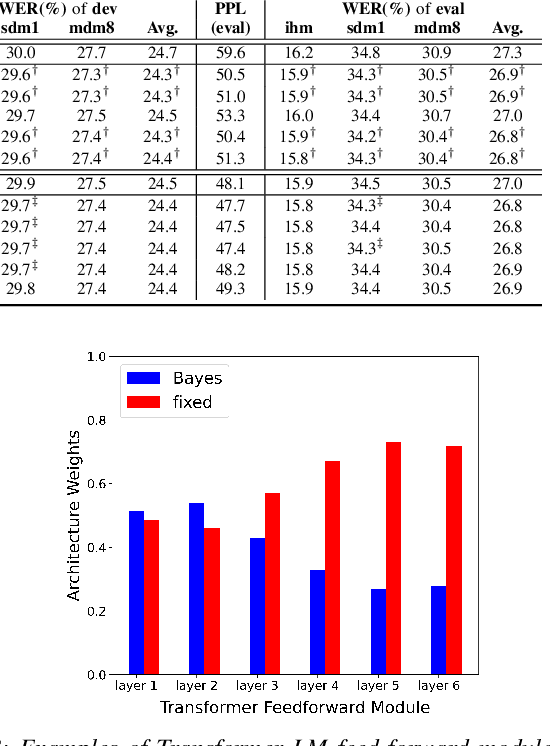
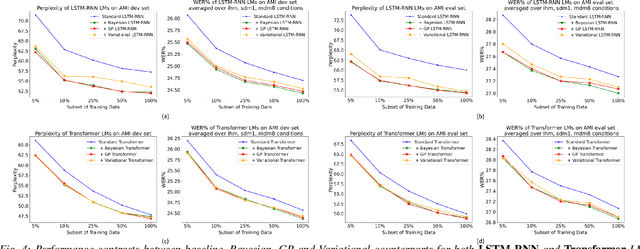
State-of-the-art neural network language models (NNLMs) represented by long short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming highly complex. They are prone to overfitting and poor generalization when given limited training data. To this end, an overarching full Bayesian learning framework encompassing three methods is proposed in this paper to account for the underlying uncertainty in LSTM-RNN and Transformer LMs. The uncertainty over their model parameters, choice of neural activations and hidden output representations are modeled using Bayesian, Gaussian Process and variational LSTM-RNN or Transformer LMs respectively. Efficient inference approaches were used to automatically select the optimal network internal components to be Bayesian learned using neural architecture search. A minimal number of Monte Carlo parameter samples as low as one was also used. These allow the computational costs incurred in Bayesian NNLM training and evaluation to be minimized. Experiments are conducted on two tasks: AMI meeting transcription and Oxford-BBC LipReading Sentences 2 (LRS2) overlapped speech recognition using state-of-the-art LF-MMI trained factored TDNN systems featuring data augmentation, speaker adaptation and audio-visual multi-channel beamforming for overlapped speech. Consistent performance improvements over the baseline LSTM-RNN and Transformer LMs with point estimated model parameters and drop-out regularization were obtained across both tasks in terms of perplexity and word error rate (WER). In particular, on the LRS2 data, statistically significant WER reductions up to 1.3% and 1.2% absolute (12.1% and 11.3% relative) were obtained over the baseline LSTM-RNN and Transformer LMs respectively after model combination between Bayesian NNLMs and their respective baselines.
Exploring linguistic feature and model combination for speech recognition based automatic AD detection
Jun 28, 2022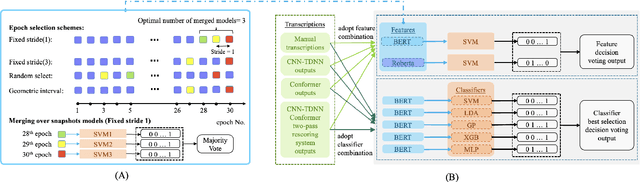
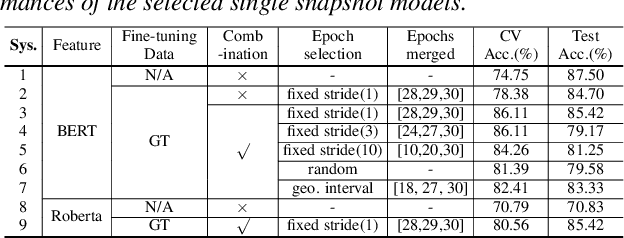
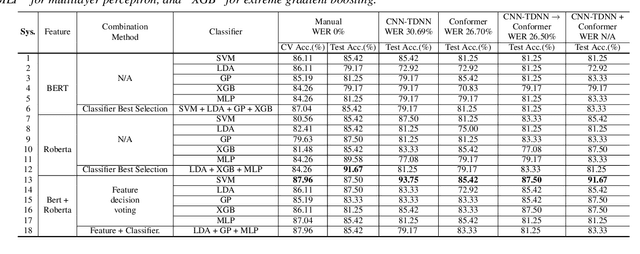
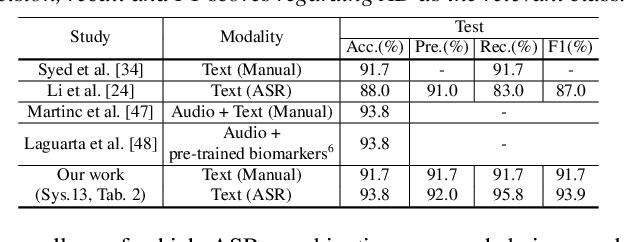
Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care and delay progression. Speech based automatic AD screening systems provide a non-intrusive and more scalable alternative to other clinical screening techniques. Scarcity of such specialist data leads to uncertainty in both model selection and feature learning when developing such systems. To this end, this paper investigates the use of feature and model combination approaches to improve the robustness of domain fine-tuning of BERT and Roberta pre-trained text encoders on limited data, before the resulting embedding features being fed into an ensemble of backend classifiers to produce the final AD detection decision via majority voting. Experiments conducted on the ADReSS20 Challenge dataset suggest consistent performance improvements were obtained using model and feature combination in system development. State-of-the-art AD detection accuracies of 91.67 percent and 93.75 percent were obtained using manual and ASR speech transcripts respectively on the ADReSS20 test set consisting of 48 elderly speakers.
Conformer Based Elderly Speech Recognition System for Alzheimer's Disease Detection
Jun 23, 2022
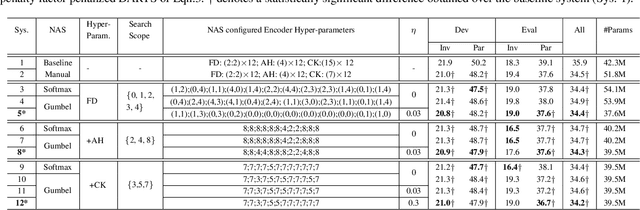
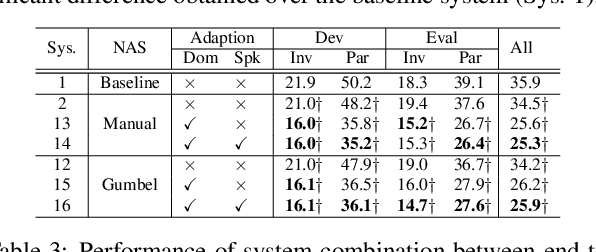
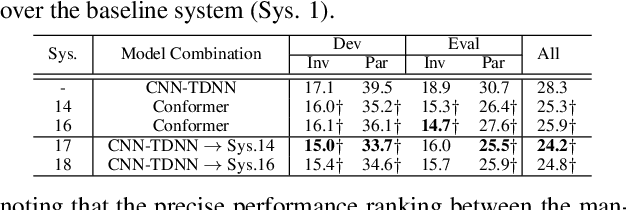
Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care to delay further progression. This paper presents the development of a state-of-the-art Conformer based speech recognition system built on the DementiaBank Pitt corpus for automatic AD detection. The baseline Conformer system trained with speed perturbation and SpecAugment based data augmentation is significantly improved by incorporating a set of purposefully designed modeling features, including neural architecture search based auto-configuration of domain-specific Conformer hyper-parameters in addition to parameter fine-tuning; fine-grained elderly speaker adaptation using learning hidden unit contributions (LHUC); and two-pass cross-system rescoring based combination with hybrid TDNN systems. An overall word error rate (WER) reduction of 13.6% absolute (34.8% relative) was obtained on the evaluation data of 48 elderly speakers. Using the final systems' recognition outputs to extract textual features, the best-published speech recognition based AD detection accuracy of 91.7% was obtained.
Towards Green ASR: Lossless 4-bit Quantization of a Hybrid TDNN System on the 300-hr Switchboard Corpus
Jun 23, 2022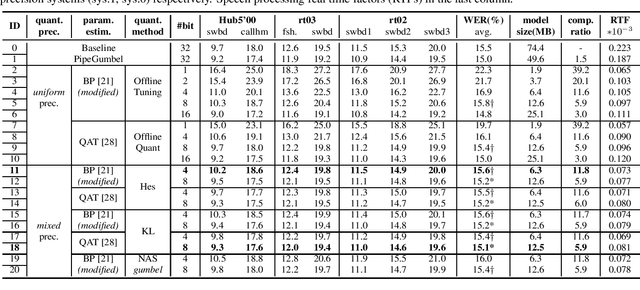
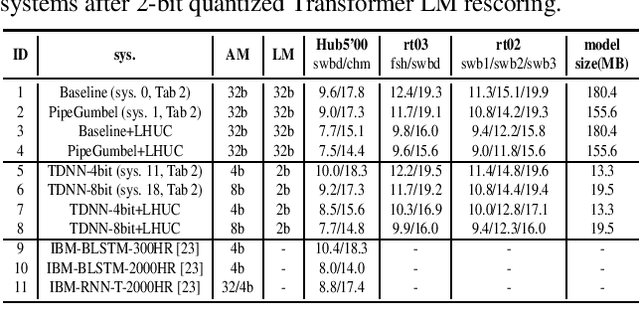
State of the art time automatic speech recognition (ASR) systems are becoming increasingly complex and expensive for practical applications. This paper presents the development of a high performance and low-footprint 4-bit quantized LF-MMI trained factored time delay neural networks (TDNNs) based ASR system on the 300-hr Switchboard corpus. A key feature of the overall system design is to account for the fine-grained, varying performance sensitivity at different model components to quantization errors. To this end, a set of neural architectural compression and mixed precision quantization approaches were used to facilitate hidden layer level auto-configuration of optimal factored TDNN weight matrix subspace dimensionality and quantization bit-widths. The proposed techniques were also used to produce 2-bit mixed precision quantized Transformer language models. Experiments conducted on the Switchboard data suggest that the proposed neural architectural compression and mixed precision quantization techniques consistently outperform the uniform precision quantised baseline systems of comparable bit-widths in terms of word error rate (WER). An overall "lossless" compression ratio of 13.6 was obtained over the baseline full precision system including both the TDNN and Transformer components while incurring no statistically significant WER increase.
Two-pass Decoding and Cross-adaptation Based System Combination of End-to-end Conformer and Hybrid TDNN ASR Systems
Jun 23, 2022
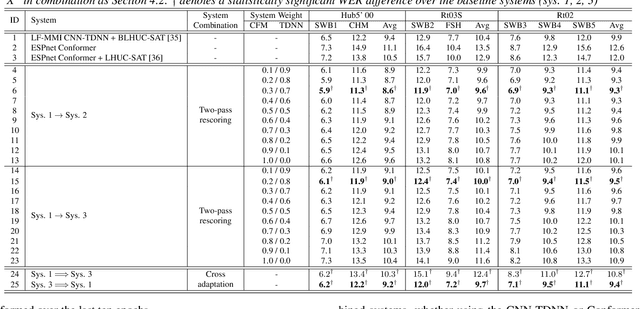
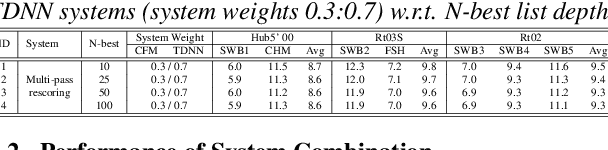
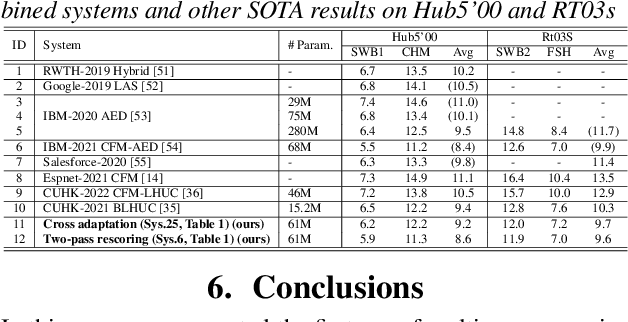
Fundamental modelling differences between hybrid and end-to-end (E2E) automatic speech recognition (ASR) systems create large diversity and complementarity among them. This paper investigates multi-pass rescoring and cross adaptation based system combination approaches for hybrid TDNN and Conformer E2E ASR systems. In multi-pass rescoring, state-of-the-art hybrid LF-MMI trained CNN-TDNN system featuring speed perturbation, SpecAugment and Bayesian learning hidden unit contributions (LHUC) speaker adaptation was used to produce initial N-best outputs before being rescored by the speaker adapted Conformer system using a 2-way cross system score interpolation. In cross adaptation, the hybrid CNN-TDNN system was adapted to the 1-best output of the Conformer system or vice versa. Experiments on the 300-hour Switchboard corpus suggest that the combined systems derived using either of the two system combination approaches outperformed the individual systems. The best combined system obtained using multi-pass rescoring produced statistically significant word error rate (WER) reductions of 2.5% to 3.9% absolute (22.5% to 28.9% relative) over the stand alone Conformer system on the NIST Hub5'00, Rt03 and Rt02 evaluation data.
Generalizing Few-Shot NAS with Gradient Matching
Apr 05, 2022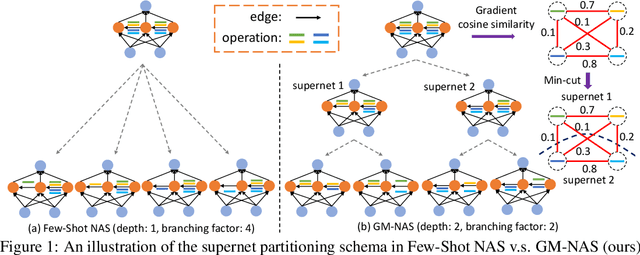
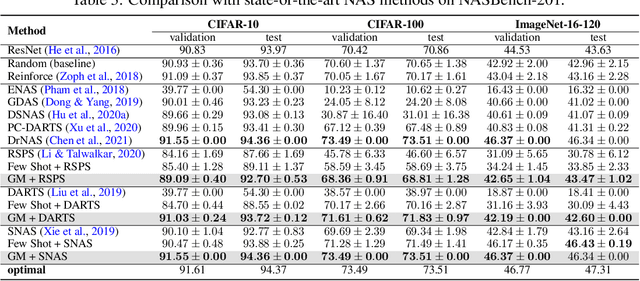
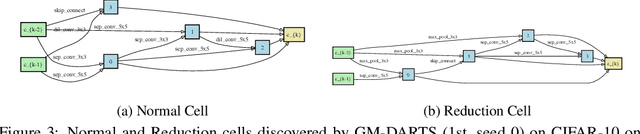
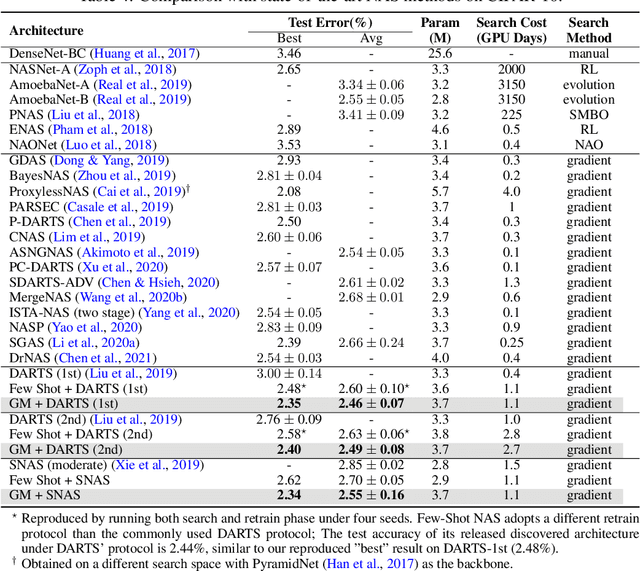
Efficient performance estimation of architectures drawn from large search spaces is essential to Neural Architecture Search. One-Shot methods tackle this challenge by training one supernet to approximate the performance of every architecture in the search space via weight-sharing, thereby drastically reducing the search cost. However, due to coupled optimization between child architectures caused by weight-sharing, One-Shot supernet's performance estimation could be inaccurate, leading to degraded search outcomes. To address this issue, Few-Shot NAS reduces the level of weight-sharing by splitting the One-Shot supernet into multiple separated sub-supernets via edge-wise (layer-wise) exhaustive partitioning. Since each partition of the supernet is not equally important, it necessitates the design of a more effective splitting criterion. In this work, we propose a gradient matching score (GM) that leverages gradient information at the shared weight for making informed splitting decisions. Intuitively, gradients from different child models can be used to identify whether they agree on how to update the shared modules, and subsequently to decide if they should share the same weight. Compared with exhaustive partitioning, the proposed criterion significantly reduces the branching factor per edge. This allows us to split more edges (layers) for a given budget, resulting in substantially improved performance as NAS search spaces usually include dozens of edges (layers). Extensive empirical evaluations of the proposed method on a wide range of search spaces (NASBench-201, DARTS, MobileNet Space), datasets (cifar10, cifar100, ImageNet) and search algorithms (DARTS, SNAS, RSPS, ProxylessNAS, OFA) demonstrate that it significantly outperforms its Few-Shot counterparts while surpassing previous comparable methods in terms of the accuracy of derived architectures.