 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Few-Shot Text Classification with Multiple Metrics
May 19, 2018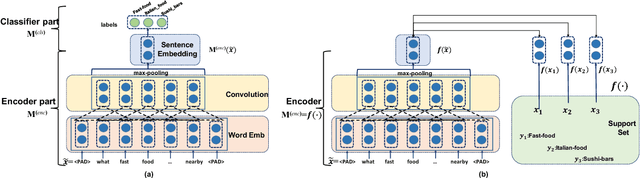
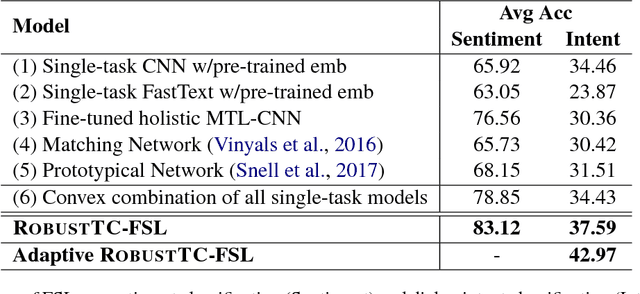
We study few-shot learning in natural language domains. Compared to many existing works that apply either metric-based or optimization-based meta-learning to image domain with low inter-task variance, we consider a more realistic setting, where tasks are diverse. However, it imposes tremendous difficulties to existing state-of-the-art metric-based algorithms since a single metric is insufficient to capture complex task variations in natural language domain. To alleviate the problem, we propose an adaptive metric learning approach that automatically determines the best weighted combination from a set of metrics obtained from meta-training tasks for a newly seen few-shot task. Extensive quantitative evaluations on real-world sentiment analysis and dialog intent classification datasets demonstrate that the proposed method performs favorably against state-of-the-art few shot learning algorithms in terms of predictive accuracy. We make our code and data available for further study.
Robust Task Clustering for Deep Many-Task Learning
May 18, 2018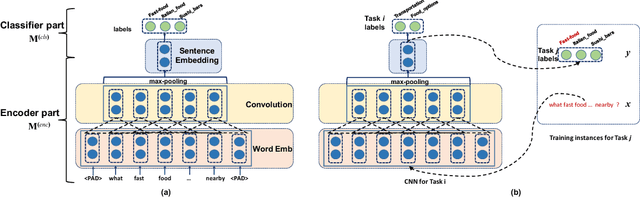
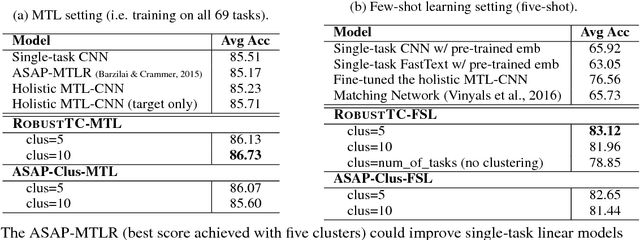
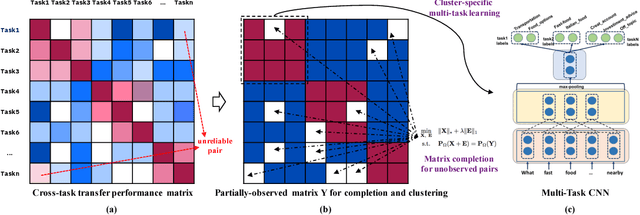
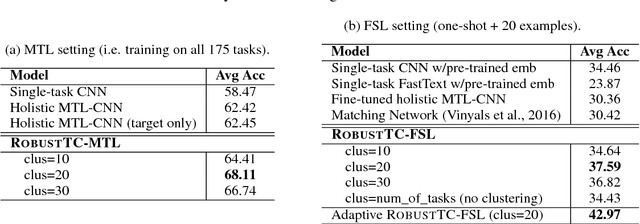
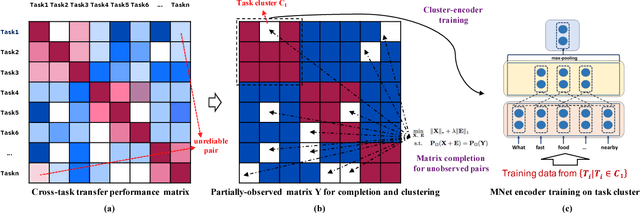
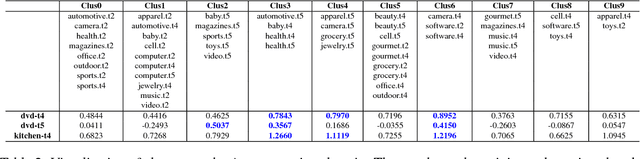
We investigate task clustering for deep-learning based multi-task and few-shot learning in a many-task setting. We propose a new method to measure task similarities with cross-task transfer performance matrix for the deep learning scenario. Although this matrix provides us critical information regarding similarity between tasks, its asymmetric property and unreliable performance scores can affect conventional clustering methods adversely. Additionally, the uncertain task-pairs, i.e., the ones with extremely asymmetric transfer scores, may collectively mislead clustering algorithms to output an inaccurate task-partition. To overcome these limitations, we propose a novel task-clustering algorithm by using the matrix completion technique. The proposed algorithm constructs a partially-observed similarity matrix based on the certainty of cluster membership of the task-pairs. We then use a matrix completion algorithm to complete the similarity matrix. Our theoretical analysis shows that under mild constraints, the proposed algorithm will perfectly recover the underlying "true" similarity matrix with a high probability. Our results show that the new task clustering method can discover task clusters for training flexible and superior neural network models in a multi-task learning setup for sentiment classification and dialog intent classification tasks. Our task clustering approach also extends metric-based few-shot learning methods to adapt multiple metrics, which demonstrates empirical advantages when the tasks are diverse.
Image Super-Resolution via Dual-State Recurrent Networks
May 07, 2018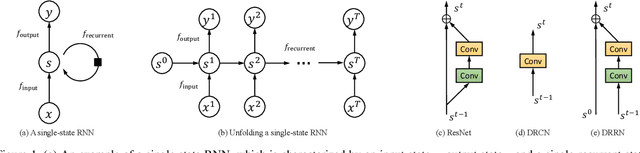
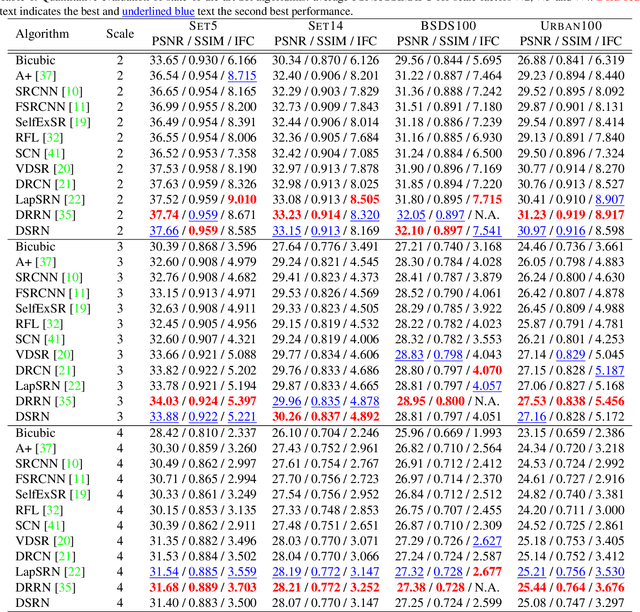
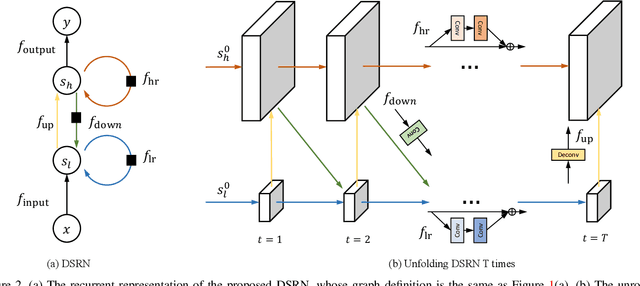
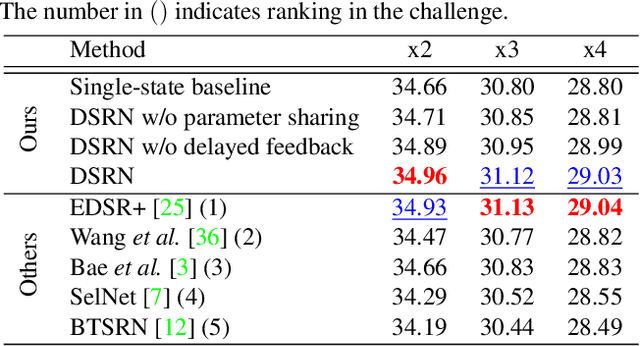
Advances in image super-resolution (SR) have recently benefited significantly from rapid developments in deep neural networks. Inspired by these recent discoveries, we note that many state-of-the-art deep SR architectures can be reformulated as a single-state recurrent neural network (RNN) with finite unfoldings. In this paper, we explore new structures for SR based on this compact RNN view, leading us to a dual-state design, the Dual-State Recurrent Network (DSRN). Compared to its single state counterparts that operate at a fixed spatial resolution, DSRN exploits both low-resolution (LR) and high-resolution (HR) signals jointly. Recurrent signals are exchanged between these states in both directions (both LR to HR and HR to LR) via delayed feedback. Extensive quantitative and qualitative evaluations on benchmark datasets and on a recent challenge demonstrate that the proposed DSRN performs favorably against state-of-the-art algorithms in terms of both memory consumption and predictive accuracy.
Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
Apr 26, 2018

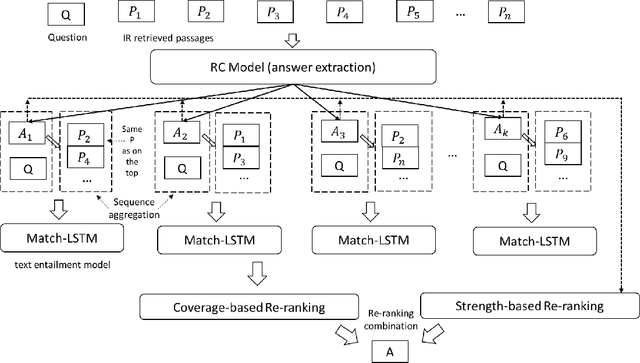
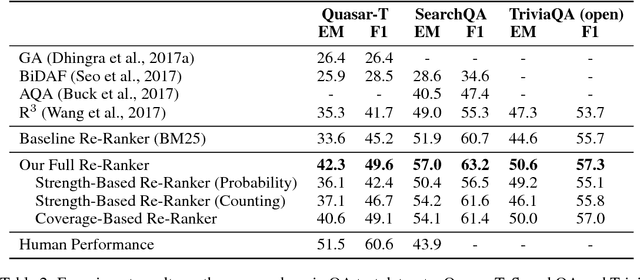
A popular recent approach to answering open-domain questions is to first search for question-related passages and then apply reading comprehension models to extract answers. Existing methods usually extract answers from single passages independently. But some questions require a combination of evidence from across different sources to answer correctly. In this paper, we propose two models which make use of multiple passages to generate their answers. Both use an answer-reranking approach which reorders the answer candidates generated by an existing state-of-the-art QA model. We propose two methods, namely, strength-based re-ranking and coverage-based re-ranking, to make use of the aggregated evidence from different passages to better determine the answer. Our models have achieved state-of-the-art results on three public open-domain QA datasets: Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8 percentage points of improvement over the former two datasets.
Deep Learning Based Speech Beamforming
Feb 15, 2018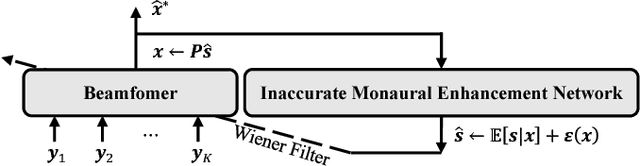
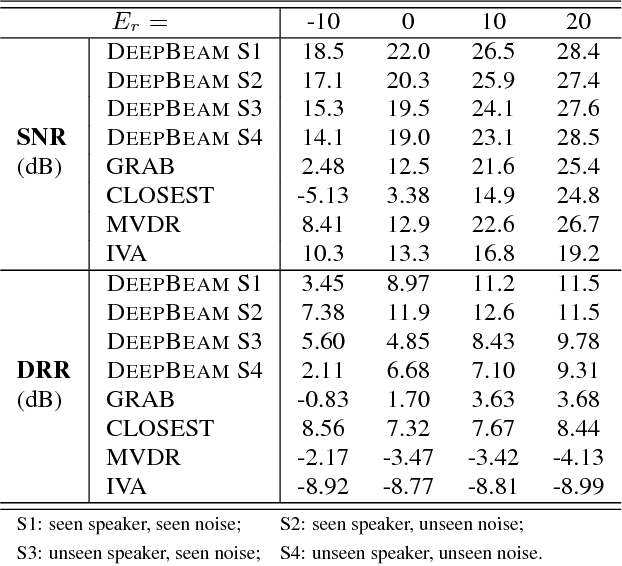
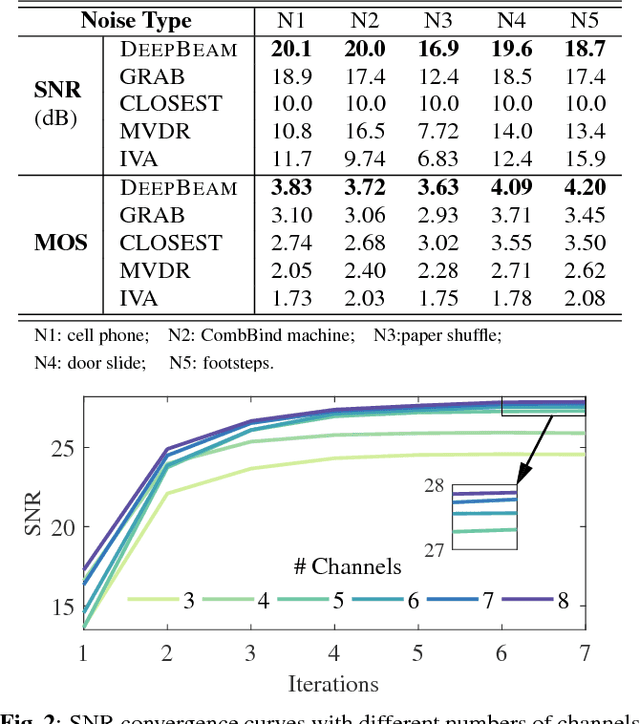
Multi-channel speech enhancement with ad-hoc sensors has been a challenging task. Speech model guided beamforming algorithms are able to recover natural sounding speech, but the speech models tend to be oversimplified or the inference would otherwise be too complicated. On the other hand, deep learning based enhancement approaches are able to learn complicated speech distributions and perform efficient inference, but they are unable to deal with variable number of input channels. Also, deep learning approaches introduce a lot of errors, particularly in the presence of unseen noise types and settings. We have therefore proposed an enhancement framework called DEEPBEAM, which combines the two complementary classes of algorithms. DEEPBEAM introduces a beamforming filter to produce natural sounding speech, but the filter coefficients are determined with the help of a monaural speech enhancement neural network. Experiments on synthetic and real-world data show that DEEPBEAM is able to produce clean, dry and natural sounding speech, and is robust against unseen noise.
Dilated Recurrent Neural Networks
Nov 02, 2017
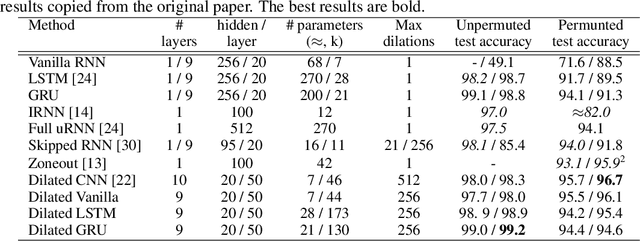
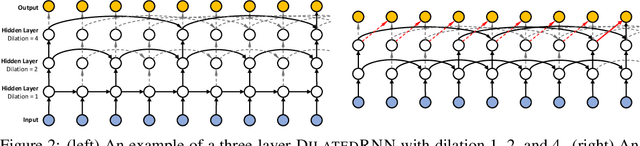
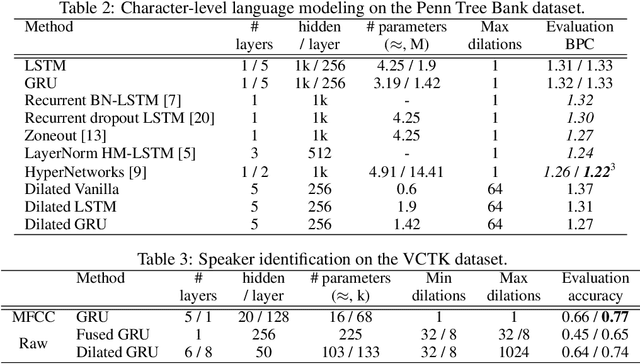
Learning with recurrent neural networks (RNNs) on long sequences is a notoriously difficult task. There are three major challenges: 1) complex dependencies, 2) vanishing and exploding gradients, and 3) efficient parallelization. In this paper, we introduce a simple yet effective RNN connection structure, the DilatedRNN, which simultaneously tackles all of these challenges. The proposed architecture is characterized by multi-resolution dilated recurrent skip connections and can be combined flexibly with diverse RNN cells. Moreover, the DilatedRNN reduces the number of parameters needed and enhances training efficiency significantly, while matching state-of-the-art performance (even with standard RNN cells) in tasks involving very long-term dependencies. To provide a theory-based quantification of the architecture's advantages, we introduce a memory capacity measure, the mean recurrent length, which is more suitable for RNNs with long skip connections than existing measures. We rigorously prove the advantages of the DilatedRNN over other recurrent neural architectures. The code for our method is publicly available at https://github.com/code-terminator/DilatedRNN
Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
Sep 29, 2017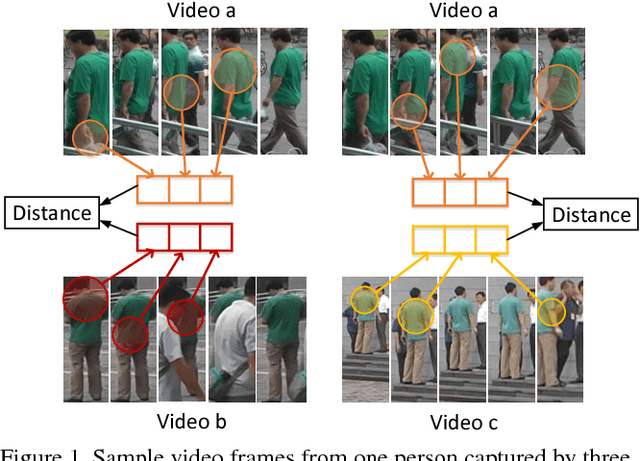
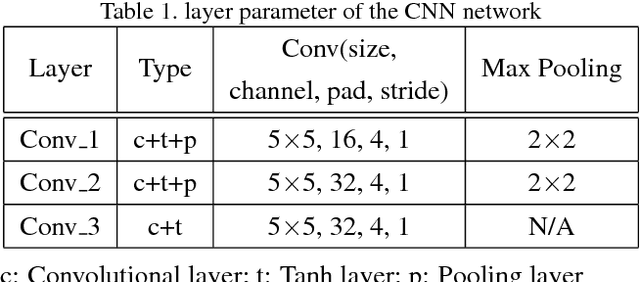
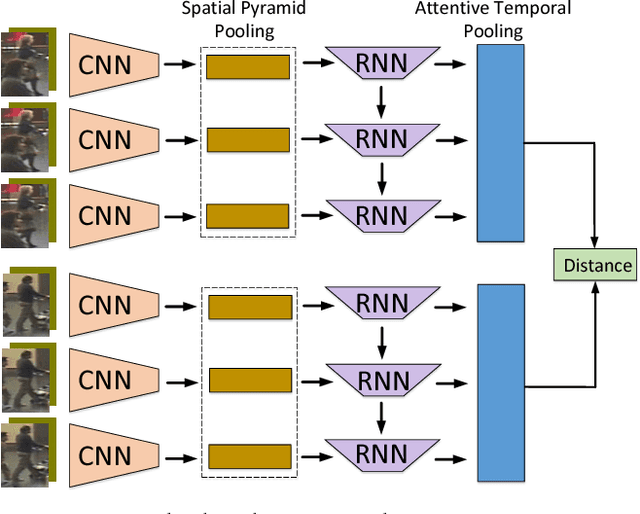
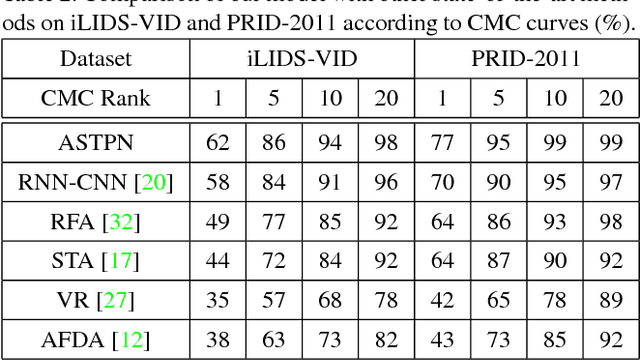
Person Re-Identification (person re-id) is a crucial task as its applications in visual surveillance and human-computer interaction. In this work, we present a novel joint Spatial and Temporal Attention Pooling Network (ASTPN) for video-based person re-identification, which enables the feature extractor to be aware of the current input video sequences, in a way that interdependency from the matching items can directly influence the computation of each other's representation. Specifically, the spatial pooling layer is able to select regions from each frame, while the attention temporal pooling performed can select informative frames over the sequence, both pooling guided by the information from distance matching. Experiments are conduced on the iLIDS-VID, PRID-2011 and MARS datasets and the results demonstrate that this approach outperforms existing state-of-art methods. We also analyze how the joint pooling in both dimensions can boost the person re-id performance more effectively than using either of them separately.
Fast Generation for Convolutional Autoregressive Models
Apr 20, 2017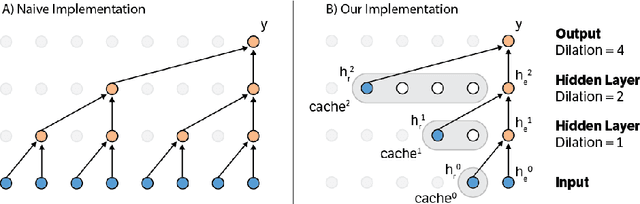
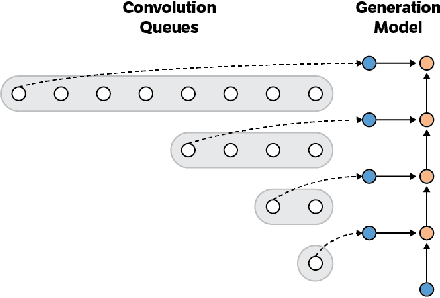
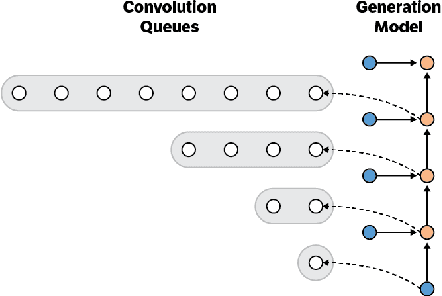
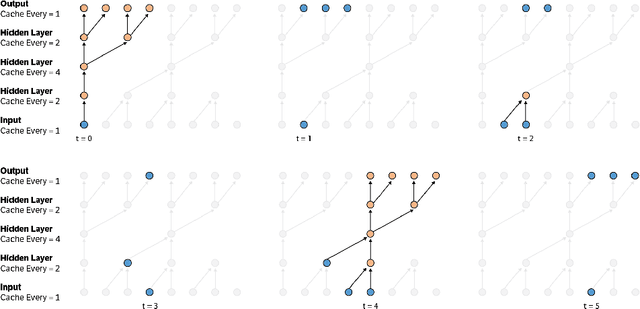
Convolutional autoregressive models have recently demonstrated state-of-the-art performance on a number of generation tasks. While fast, parallel training methods have been crucial for their success, generation is typically implemented in a na\"{i}ve fashion where redundant computations are unnecessarily repeated. This results in slow generation, making such models infeasible for production environments. In this work, we describe a method to speed up generation in convolutional autoregressive models. The key idea is to cache hidden states to avoid redundant computation. We apply our fast generation method to the Wavenet and PixelCNN++ models and achieve up to $21\times$ and $183\times$ speedups respectively.
Fast Wavenet Generation Algorithm
Nov 29, 2016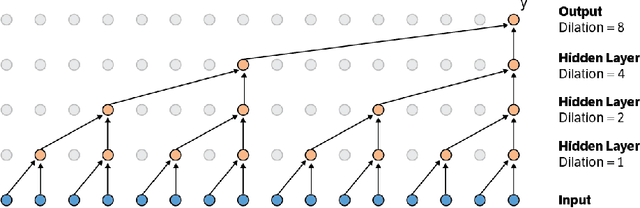
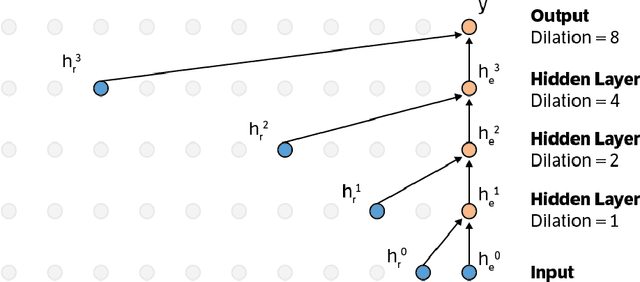
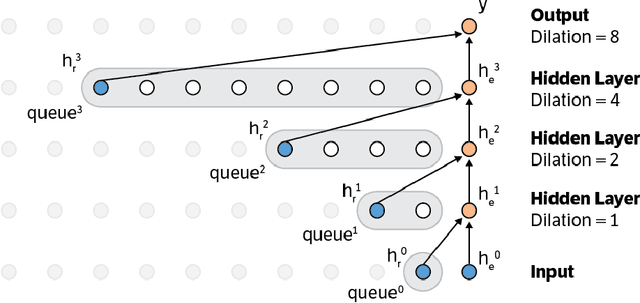
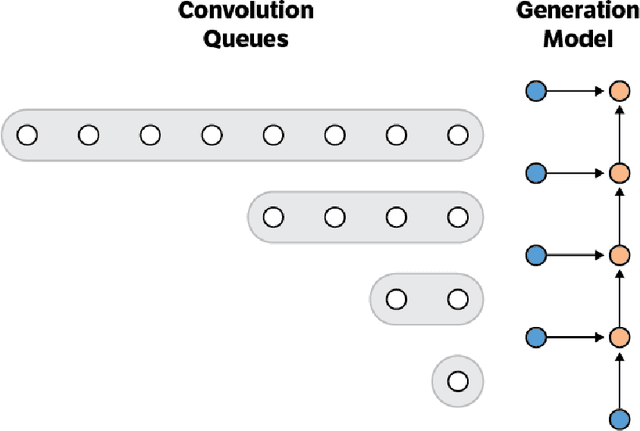
This paper presents an efficient implementation of the Wavenet generation process called Fast Wavenet. Compared to a naive implementation that has complexity O(2^L) (L denotes the number of layers in the network), our proposed approach removes redundant convolution operations by caching previous calculations, thereby reducing the complexity to O(L) time. Timing experiments show significant advantages of our fast implementation over a naive one. While this method is presented for Wavenet, the same scheme can be applied anytime one wants to perform autoregressive generation or online prediction using a model with dilated convolution layers. The code for our method is publicly available.
Stacked Approximated Regression Machine: A Simple Deep Learning Approach
Sep 08, 2016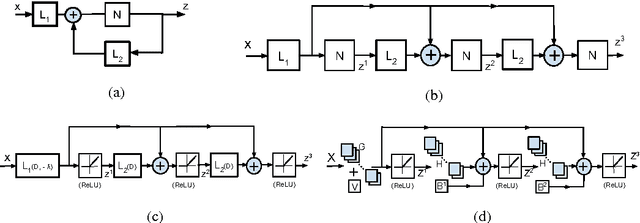
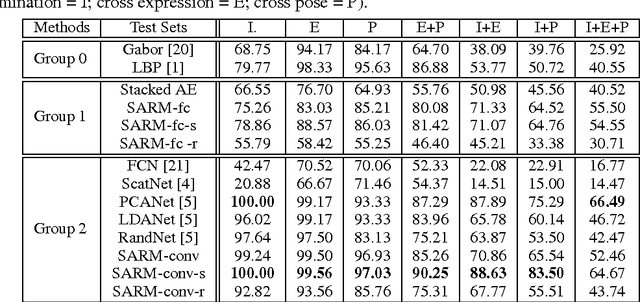
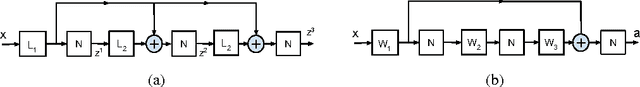

With the agreement of my coauthors, I Zhangyang Wang would like to withdraw the manuscript "Stacked Approximated Regression Machine: A Simple Deep Learning Approach". Some experimental procedures were not included in the manuscript, which makes a part of important claims not meaningful. In the relevant research, I was solely responsible for carrying out the experiments; the other coauthors joined in the discussions leading to the main algorithm. Please see the updated text for more details.