 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEPT: Towards Efficient Scene Representation Learning for Motion Prediction
Oct 03, 2023Motion prediction is crucial for autonomous vehicles to operate safely in complex traffic environments. Extracting effective spatiotemporal relationships among traffic elements is key to accurate forecasting. Inspired by the successful practice of pretrained large language models, this paper presents SEPT, a modeling framework that leverages self-supervised learning to develop powerful spatiotemporal understanding for complex traffic scenes. Specifically, our approach involves three masking-reconstruction modeling tasks on scene inputs including agents' trajectories and road network, pretraining the scene encoder to capture kinematics within trajectory, spatial structure of road network, and interactions among roads and agents. The pretrained encoder is then finetuned on the downstream forecasting task. Extensive experiments demonstrate that SEPT, without elaborate architectural design or manual feature engineering, achieves state-of-the-art performance on the Argoverse 1 and Argoverse 2 motion forecasting benchmarks, outperforming previous methods on all main metrics by a large margin.
Safe Reinforcement Learning with Dual Robustness
Sep 13, 2023

Reinforcement learning (RL) agents are vulnerable to adversarial disturbances, which can deteriorate task performance or compromise safety specifications. Existing methods either address safety requirements under the assumption of no adversary (e.g., safe RL) or only focus on robustness against performance adversaries (e.g., robust RL). Learning one policy that is both safe and robust remains a challenging open problem. The difficulty is how to tackle two intertwined aspects in the worst cases: feasibility and optimality. Optimality is only valid inside a feasible region, while identification of maximal feasible region must rely on learning the optimal policy. To address this issue, we propose a systematic framework to unify safe RL and robust RL, including problem formulation, iteration scheme, convergence analysis and practical algorithm design. This unification is built upon constrained two-player zero-sum Markov games. A dual policy iteration scheme is proposed, which simultaneously optimizes a task policy and a safety policy. The convergence of this iteration scheme is proved. Furthermore, we design a deep RL algorithm for practical implementation, called dually robust actor-critic (DRAC). The evaluations with safety-critical benchmarks demonstrate that DRAC achieves high performance and persistent safety under all scenarios (no adversary, safety adversary, performance adversary), outperforming all baselines significantly.
Feasible Policy Iteration
Apr 18, 2023Safe reinforcement learning (RL) aims to solve an optimal control problem under safety constraints. Existing $\textit{direct}$ safe RL methods use the original constraint throughout the learning process. They either lack theoretical guarantees of the policy during iteration or suffer from infeasibility problems. To address this issue, we propose an $\textit{indirect}$ safe RL method called feasible policy iteration (FPI) that iteratively uses the feasible region of the last policy to constrain the current policy. The feasible region is represented by a feasibility function called constraint decay function (CDF). The core of FPI is a region-wise policy update rule called feasible policy improvement, which maximizes the return under the constraint of the CDF inside the feasible region and minimizes the CDF outside the feasible region. This update rule is always feasible and ensures that the feasible region monotonically expands and the state-value function monotonically increases inside the feasible region. Using the feasible Bellman equation, we prove that FPI converges to the maximum feasible region and the optimal state-value function. Experiments on classic control tasks and Safety Gym show that our algorithms achieve lower constraint violations and comparable or higher performance than the baselines.
Smoothing Policy Iteration for Zero-sum Markov Games
Dec 03, 2022



Zero-sum Markov Games (MGs) has been an efficient framework for multi-agent systems and robust control, wherein a minimax problem is constructed to solve the equilibrium policies. At present, this formulation is well studied under tabular settings wherein the maximum operator is primarily and exactly solved to calculate the worst-case value function. However, it is non-trivial to extend such methods to handle complex tasks, as finding the maximum over large-scale action spaces is usually cumbersome. In this paper, we propose the smoothing policy iteration (SPI) algorithm to solve the zero-sum MGs approximately, where the maximum operator is replaced by the weighted LogSumExp (WLSE) function to obtain the nearly optimal equilibrium policies. Specially, the adversarial policy is served as the weight function to enable an efficient sampling over action spaces.We also prove the convergence of SPI and analyze its approximation error in $\infty -$norm based on the contraction mapping theorem. Besides, we propose a model-based algorithm called Smooth adversarial Actor-critic (SaAC) by extending SPI with the function approximations. The target value related to WLSE function is evaluated by the sampled trajectories and then mean square error is constructed to optimize the value function, and the gradient-ascent-descent methods are adopted to optimize the protagonist and adversarial policies jointly. In addition, we incorporate the reparameterization technique in model-based gradient back-propagation to prevent the gradient vanishing due to sampling from the stochastic policies. We verify our algorithm in both tabular and function approximation settings. Results show that SPI can approximate the worst-case value function with a high accuracy and SaAC can stabilize the training process and improve the adversarial robustness in a large margin.
Integrated Decision and Control for High-Level Automated Vehicles by Mixed Policy Gradient and Its Experiment Verification
Oct 19, 2022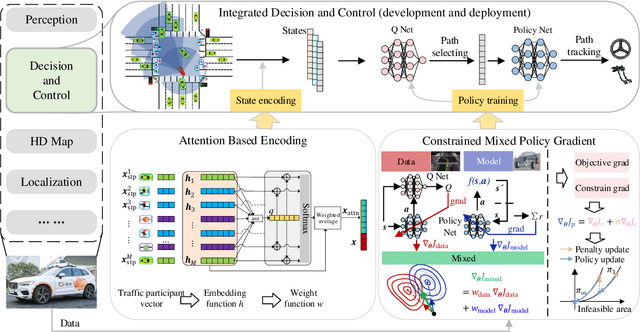
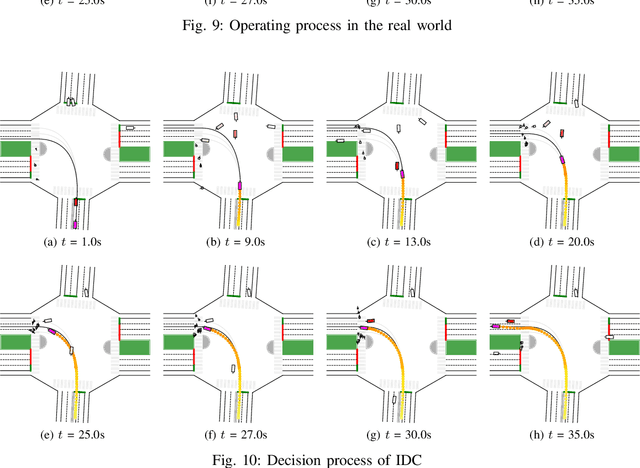
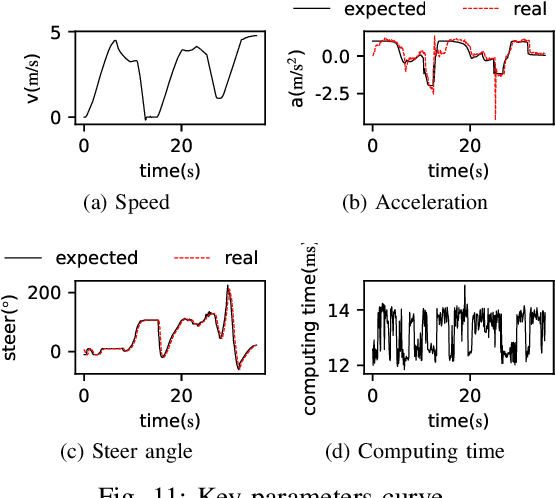
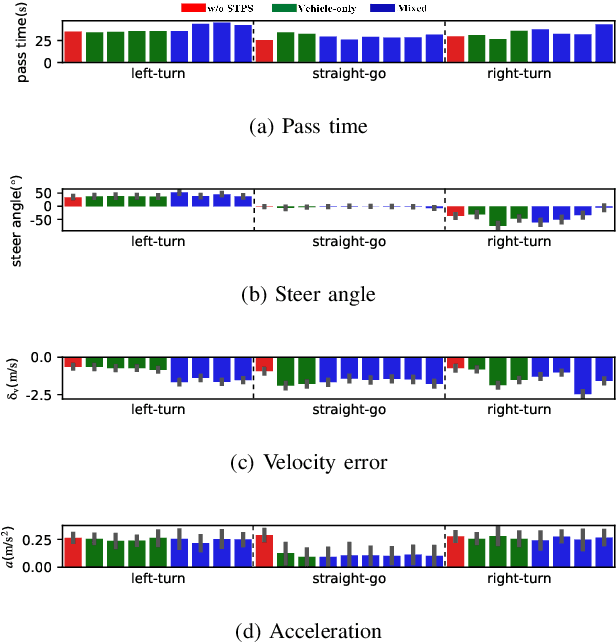
Self-evolution is indispensable to realize full autonomous driving. This paper presents a self-evolving decision-making system based on the Integrated Decision and Control (IDC), an advanced framework built on reinforcement learning (RL). First, an RL algorithm called constrained mixed policy gradient (CMPG) is proposed to consistently upgrade the driving policy of the IDC. It adapts the MPG under the penalty method so that it can solve constrained optimization problems using both the data and model. Second, an attention-based encoding (ABE) method is designed to tackle the state representation issue. It introduces an embedding network for feature extraction and a weighting network for feature fusion, fulfilling order-insensitive encoding and importance distinguishing of road users. Finally, by fusing CMPG and ABE, we develop the first data-driven decision and control system under the IDC architecture, and deploy the system on a fully-functional self-driving vehicle running in daily operation. Experiment results show that boosting by data, the system can achieve better driving ability over model-based methods. It also demonstrates safe, efficient and smart driving behavior in various complex scenes at a signalized intersection with real mixed traffic flow.
Safe Model-Based Reinforcement Learning with an Uncertainty-Aware Reachability Certificate
Oct 14, 2022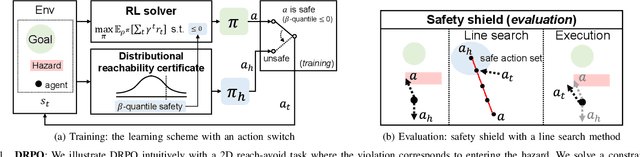
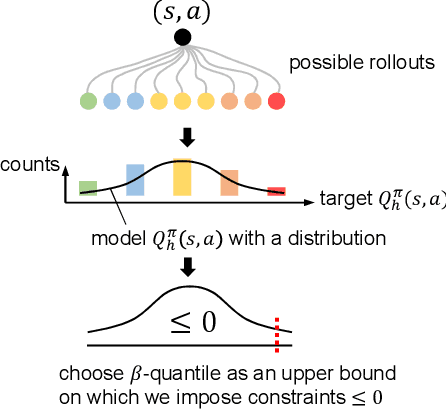
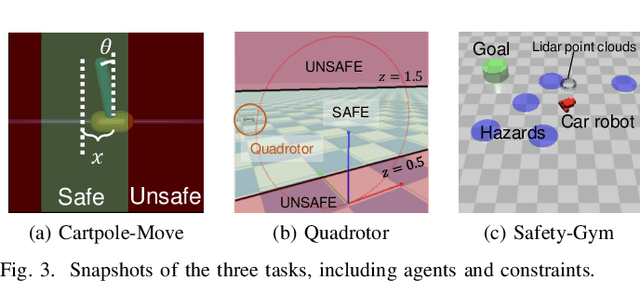
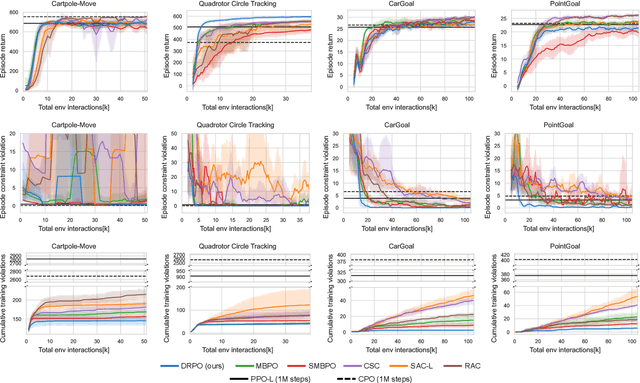
Safe reinforcement learning (RL) that solves constraint-satisfactory policies provides a promising way to the broader safety-critical applications of RL in real-world problems such as robotics. Among all safe RL approaches, model-based methods reduce training time violations further due to their high sample efficiency. However, lacking safety robustness against the model uncertainties remains an issue in safe model-based RL, especially in training time safety. In this paper, we propose a distributional reachability certificate (DRC) and its Bellman equation to address model uncertainties and characterize robust persistently safe states. Furthermore, we build a safe RL framework to resolve constraints required by the DRC and its corresponding shield policy. We also devise a line search method to maintain safety and reach higher returns simultaneously while leveraging the shield policy. Comprehensive experiments on classical benchmarks such as constrained tracking and navigation indicate that the proposed algorithm achieves comparable returns with much fewer constraint violations during training.
Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
Oct 08, 2022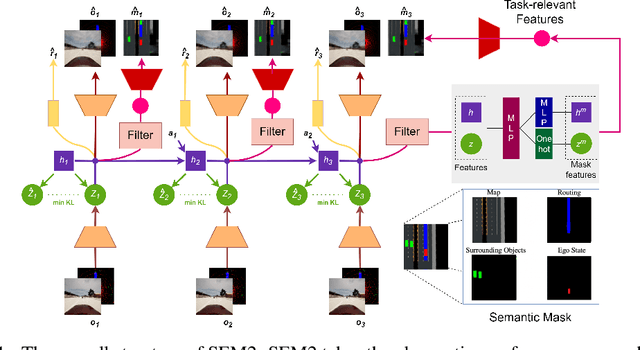

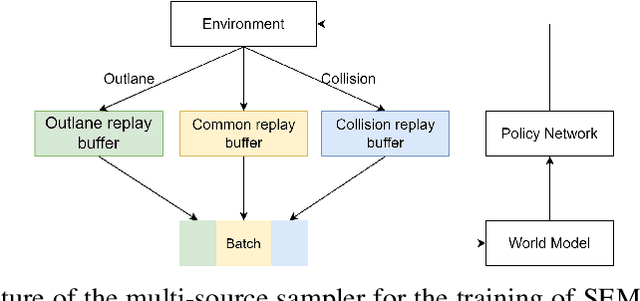
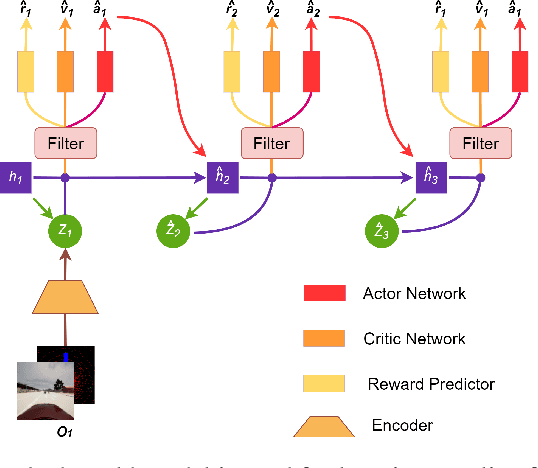
End-to-end autonomous driving provides a feasible way to automatically maximize overall driving system performance by directly mapping the raw pixels from a front-facing camera to control signals. Recent advanced methods construct a latent world model to map the high dimensional observations into compact latent space. However, the latent states embedded by the world model proposed in previous works may contain a large amount of task-irrelevant information, resulting in low sampling efficiency and poor robustness to input perturbations. Meanwhile, the training data distribution is usually unbalanced, and the learned policy is hard to cope with the corner cases during the driving process. To solve the above challenges, we present a semantic masked recurrent world model (SEM2), which introduces a latent filter to extract key task-relevant features and reconstruct a semantic mask via the filtered features, and is trained with a multi-source data sampler, which aggregates common data and multiple corner case data in a single batch, to balance the data distribution. Extensive experiments on CARLA show that our method outperforms the state-of-the-art approaches in terms of sample efficiency and robustness to input permutations.
Synthesize Efficient Safety Certificates for Learning-Based Safe Control using Magnitude Regularization
Sep 23, 2022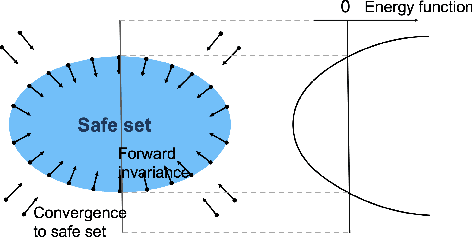
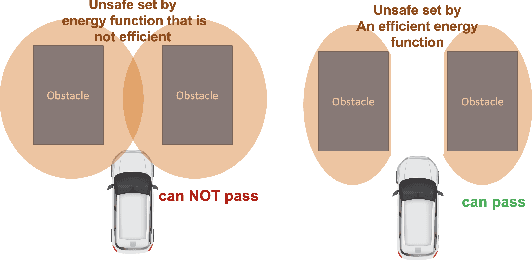
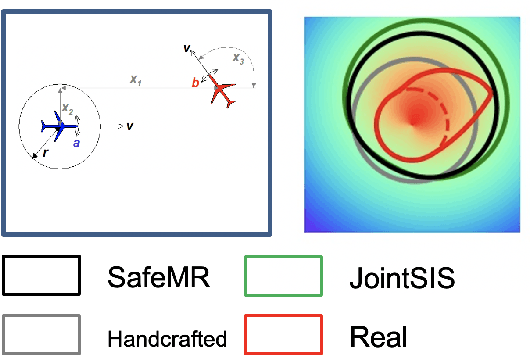

Energy-function-based safety certificates can provide provable safety guarantees for the safe control tasks of complex robotic systems. However, all recent studies about learning-based energy function synthesis only consider the feasibility, which might cause over-conservativeness and result in less efficient controllers. In this work, we proposed the magnitude regularization technique to improve the efficiency of safe controllers by reducing the conservativeness inside the energy function while keeping the promising provable safety guarantees. Specifically, we quantify the conservativeness by the magnitude of the energy function, and we reduce the conservativeness by adding a magnitude regularization term to the synthesis loss. We propose the SafeMR algorithm that uses reinforcement learning (RL) for the synthesis to unify the learning processes of safe controllers and energy functions. Experimental results show that the proposed method does reduce the conservativeness of the energy functions and outperforms the baselines in terms of the controller efficiency while guaranteeing safety.
Performance-Driven Controller Tuning via Derivative-Free Reinforcement Learning
Sep 11, 2022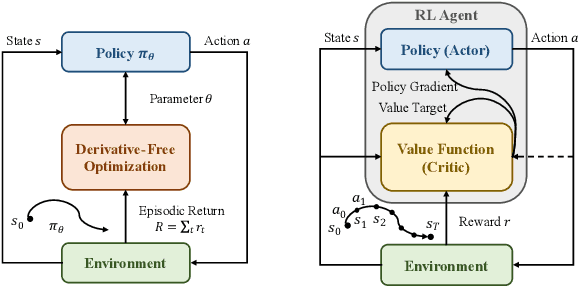
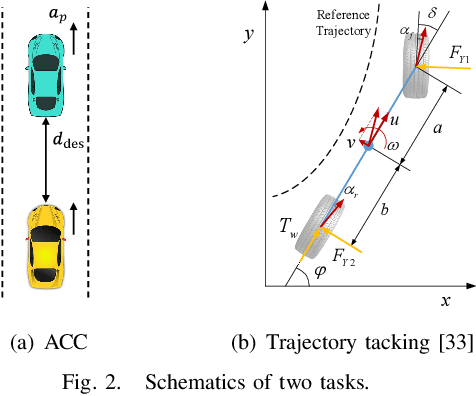
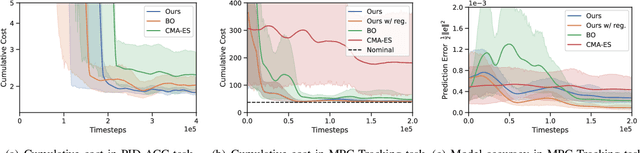
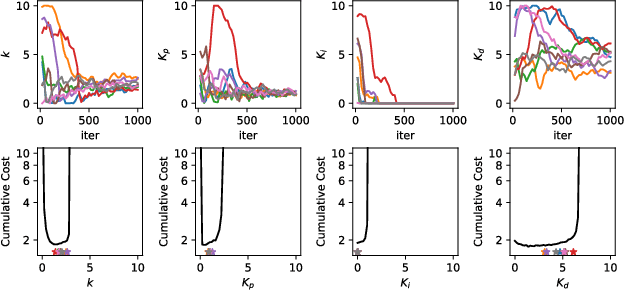
Choosing an appropriate parameter set for the designed controller is critical for the final performance but usually requires a tedious and careful tuning process, which implies a strong need for automatic tuning methods. However, among existing methods, derivative-free ones suffer from poor scalability or low efficiency, while gradient-based ones are often unavailable due to possibly non-differentiable controller structure. To resolve the issues, we tackle the controller tuning problem using a novel derivative-free reinforcement learning (RL) framework, which performs timestep-wise perturbation in parameter space during experience collection and integrates derivative-free policy updates into the advanced actor-critic RL architecture to achieve high versatility and efficiency. To demonstrate the framework's efficacy, we conduct numerical experiments on two concrete examples from autonomous driving, namely, adaptive cruise control with PID controller and trajectory tracking with MPC controller. Experimental results show that the proposed method outperforms popular baselines and highlight its strong potential for controller tuning.
Reachability Constrained Reinforcement Learning
May 16, 2022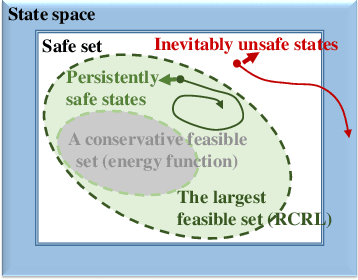
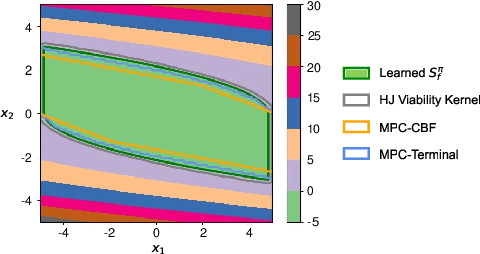
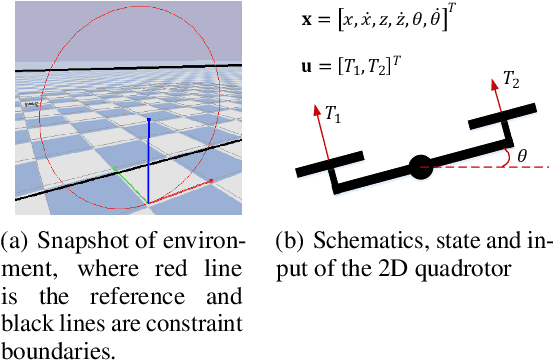
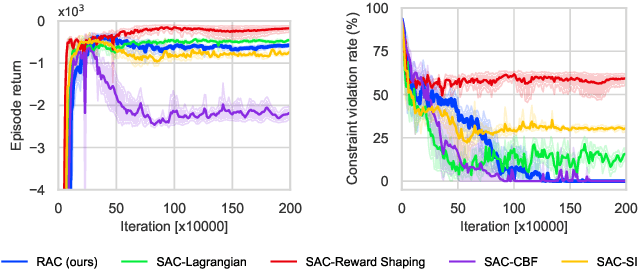
Constrained Reinforcement Learning (CRL) has gained significant interest recently, since the satisfaction of safety constraints is critical for real world problems. However, existing CRL methods constraining discounted cumulative costs generally lack rigorous definition and guarantee of safety. On the other hand, in the safe control research, safety is defined as persistently satisfying certain state constraints. Such persistent safety is possible only on a subset of the state space, called feasible set, where an optimal largest feasible set exists for a given environment. Recent studies incorporating safe control with CRL using energy-based methods such as control barrier function (CBF), safety index (SI) leverage prior conservative estimation of feasible sets, which harms performance of the learned policy. To deal with this problem, this paper proposes a reachability CRL (RCRL) method by using reachability analysis to characterize the largest feasible sets. We characterize the feasible set by the established self-consistency condition, then a safety value function can be learned and used as constraints in CRL. We also use the multi-time scale stochastic approximation theory to prove that the proposed algorithm converges to a local optimum, where the largest feasible set can be guaranteed. Empirical results on different benchmarks such as safe-control-gym and Safety-Gym validate the learned feasible set, the performance in optimal criteria, and constraint satisfaction of RCRL, compared to state-of-the-art CRL baselines.