 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision Avoidance Verification of Multiagent Systems with Learned Policies
Mar 05, 2024For many multiagent control problems, neural networks (NNs) have enabled promising new capabilities. However, many of these systems lack formal guarantees (e.g., collision avoidance, robustness), which prevents leveraging these advances in safety-critical settings. While there is recent work on formal verification of NN-controlled systems, most existing techniques cannot handle scenarios with more than one agent. To address this research gap, this paper presents a backward reachability-based approach for verifying the collision avoidance properties of Multi-Agent Neural Feedback Loops (MA-NFLs). Given the dynamics models and trained control policies of each agent, the proposed algorithm computes relative backprojection sets by solving a series of Mixed Integer Linear Programs (MILPs) offline for each pair of agents. Our pair-wise approach is parallelizable and thus scales well with increasing number of agents, and we account for state measurement uncertainties, making it well aligned with real-world scenarios. Using those results, the agents can quickly check for collision avoidance online by solving low-dimensional Linear Programs (LPs). We demonstrate the proposed algorithm can verify collision-free properties of a MA-NFL with agents trained to imitate a collision avoidance algorithm (Reciprocal Velocity Obstacles). We further demonstrate the computational scalability of the approach on systems with up to 10 agents.
Deconstructing Cooperation and Ostracism via Multi-Agent Reinforcement Learning
Oct 06, 2023



Cooperation is challenging in biological systems, human societies, and multi-agent systems in general. While a group can benefit when everyone cooperates, it is tempting for each agent to act selfishly instead. Prior human studies show that people can overcome such social dilemmas while choosing interaction partners, i.e., strategic network rewiring. However, little is known about how agents, including humans, can learn about cooperation from strategic rewiring and vice versa. Here, we perform multi-agent reinforcement learning simulations in which two agents play the Prisoner's Dilemma game iteratively. Each agent has two policies: one controls whether to cooperate or defect; the other controls whether to rewire connections with another agent. This setting enables us to disentangle complex causal dynamics between cooperation and network rewiring. We find that network rewiring facilitates mutual cooperation even when one agent always offers cooperation, which is vulnerable to free-riding. We then confirm that the network-rewiring effect is exerted through agents' learning of ostracism, that is, connecting to cooperators and disconnecting from defectors. However, we also find that ostracism alone is not sufficient to make cooperation emerge. Instead, ostracism emerges from the learning of cooperation, and existing cooperation is subsequently reinforced due to the presence of ostracism. Our findings provide insights into the conditions and mechanisms necessary for the emergence of cooperation with network rewiring.
DRIP: Domain Refinement Iteration with Polytopes for Backward Reachability Analysis of Neural Feedback Loops
Dec 09, 2022



Safety certification of data-driven control techniques remains a major open problem. This work investigates backward reachability as a framework for providing collision avoidance guarantees for systems controlled by neural network (NN) policies. Because NNs are typically not invertible, existing methods conservatively assume a domain over which to relax the NN, which causes loose over-approximations of the set of states that could lead the system into the obstacle (i.e., backprojection (BP) sets). To address this issue, we introduce DRIP, an algorithm with a refinement loop on the relaxation domain, which substantially tightens the BP set bounds. Furthermore, we introduce a formulation that enables directly obtaining closed-form representations of polytopes to bound the BP sets tighter than prior work, which required solving linear programs and using hyper-rectangles. Furthermore, this work extends the NN relaxation algorithm to handle polytope domains, which further tightens the bounds on BP sets. DRIP is demonstrated in numerical experiments on control systems, including a ground robot controlled by a learned NN obstacle avoidance policy.
Multi-Agent Reinforcement Learning for Microprocessor Design Space Exploration
Nov 29, 2022



Microprocessor architects are increasingly resorting to domain-specific customization in the quest for high-performance and energy-efficiency. As the systems grow in complexity, fine-tuning architectural parameters across multiple sub-systems (e.g., datapath, memory blocks in different hierarchies, interconnects, compiler optimization, etc.) quickly results in a combinatorial explosion of design space. This makes domain-specific customization an extremely challenging task. Prior work explores using reinforcement learning (RL) and other optimization methods to automatically explore the large design space. However, these methods have traditionally relied on single-agent RL/ML formulations. It is unclear how scalable single-agent formulations are as we increase the complexity of the design space (e.g., full stack System-on-Chip design). Therefore, we propose an alternative formulation that leverages Multi-Agent RL (MARL) to tackle this problem. The key idea behind using MARL is an observation that parameters across different sub-systems are more or less independent, thus allowing a decentralized role assigned to each agent. We test this hypothesis by designing domain-specific DRAM memory controller for several workload traces. Our evaluation shows that the MARL formulation consistently outperforms single-agent RL baselines such as Proximal Policy Optimization and Soft Actor-Critic over different target objectives such as low power and latency. To this end, this work opens the pathway for new and promising research in MARL solutions for hardware architecture search.
Game Theoretic Rating in N-player general-sum games with Equilibria
Oct 05, 2022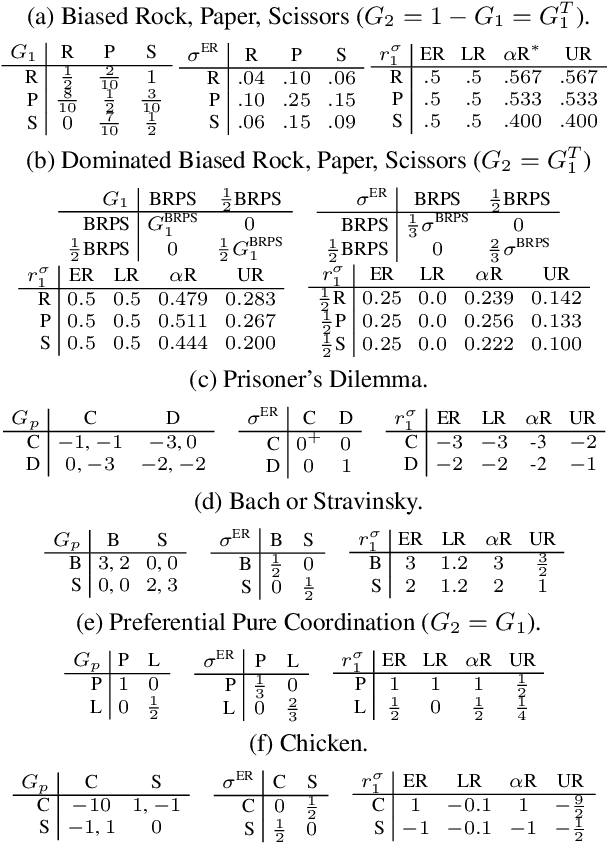
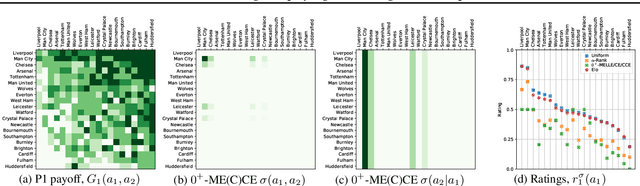
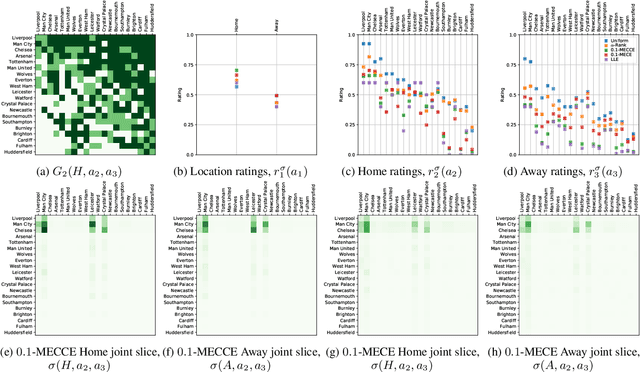
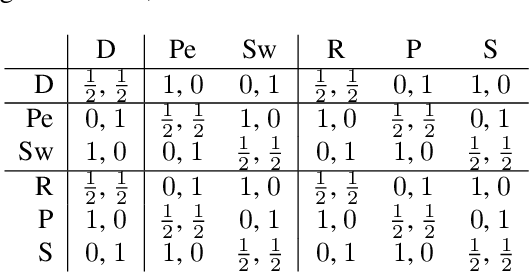
Rating strategies in a game is an important area of research in game theory and artificial intelligence, and can be applied to any real-world competitive or cooperative setting. Traditionally, only transitive dependencies between strategies have been used to rate strategies (e.g. Elo), however recent work has expanded ratings to utilize game theoretic solutions to better rate strategies in non-transitive games. This work generalizes these ideas and proposes novel algorithms suitable for N-player, general-sum rating of strategies in normal-form games according to the payoff rating system. This enables well-established solution concepts, such as equilibria, to be leveraged to efficiently rate strategies in games with complex strategic interactions, which arise in multiagent training and real-world interactions between many agents. We empirically validate our methods on real world normal-form data (Premier League) and multiagent reinforcement learning agent evaluation.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022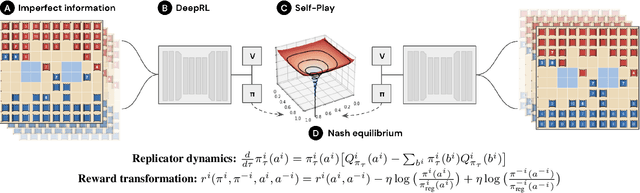
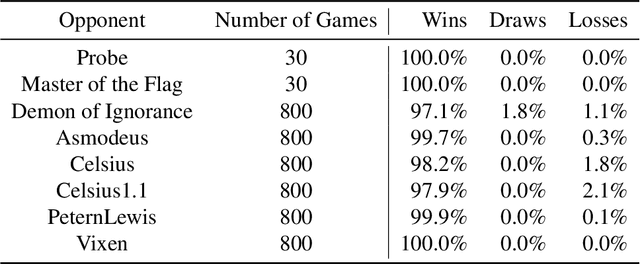
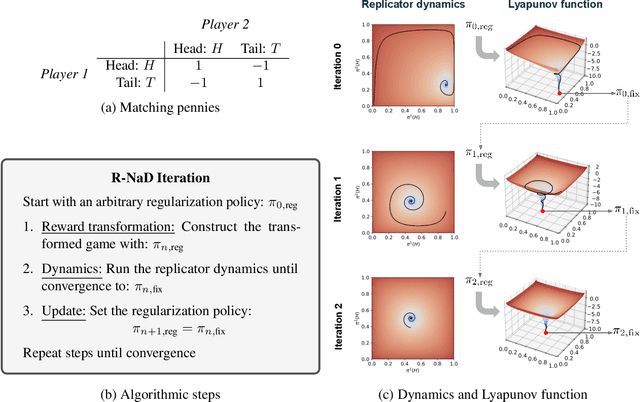

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Beyond Rewards: a Hierarchical Perspective on Offline Multiagent Behavioral Analysis
Jun 17, 2022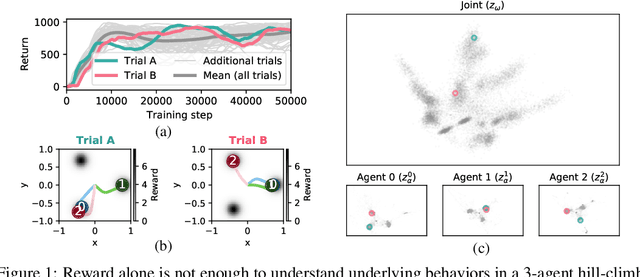
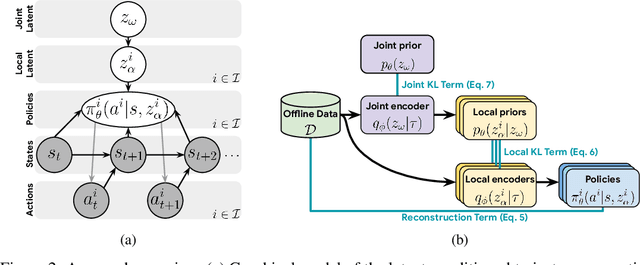
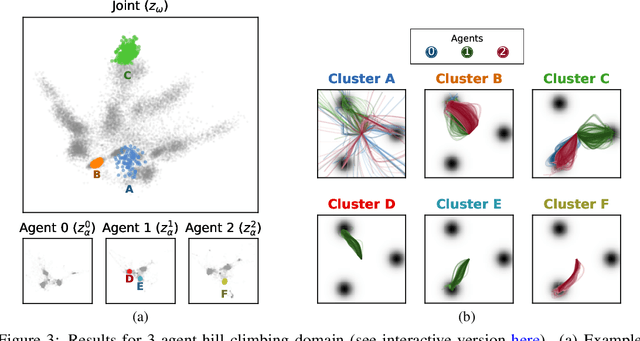

Each year, expert-level performance is attained in increasingly-complex multiagent domains, notable examples including Go, Poker, and StarCraft II. This rapid progression is accompanied by a commensurate need to better understand how such agents attain this performance, to enable their safe deployment, identify limitations, and reveal potential means of improving them. In this paper we take a step back from performance-focused multiagent learning, and instead turn our attention towards agent behavior analysis. We introduce a model-agnostic method for discovery of behavior clusters in multiagent domains, using variational inference to learn a hierarchy of behaviors at the joint and local agent levels. Our framework makes no assumption about agents' underlying learning algorithms, does not require access to their latent states or models, and can be trained using entirely offline observational data. We illustrate the effectiveness of our method for enabling the coupled understanding of behaviors at the joint and local agent level, detection of behavior changepoints throughout training, discovery of core behavioral concepts (e.g., those that facilitate higher returns), and demonstrate the approach's scalability to a high-dimensional multiagent MuJoCo control domain.
Evolutionary Dynamics and $Φ$-Regret Minimization in Games
Jun 28, 2021
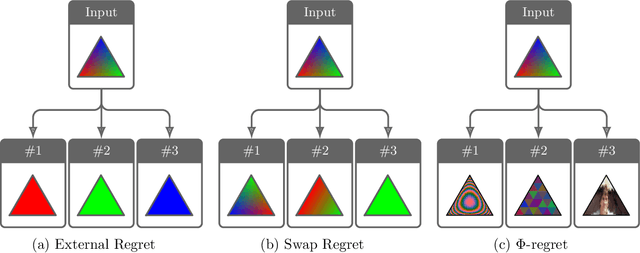
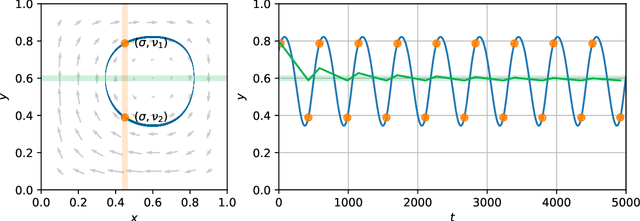
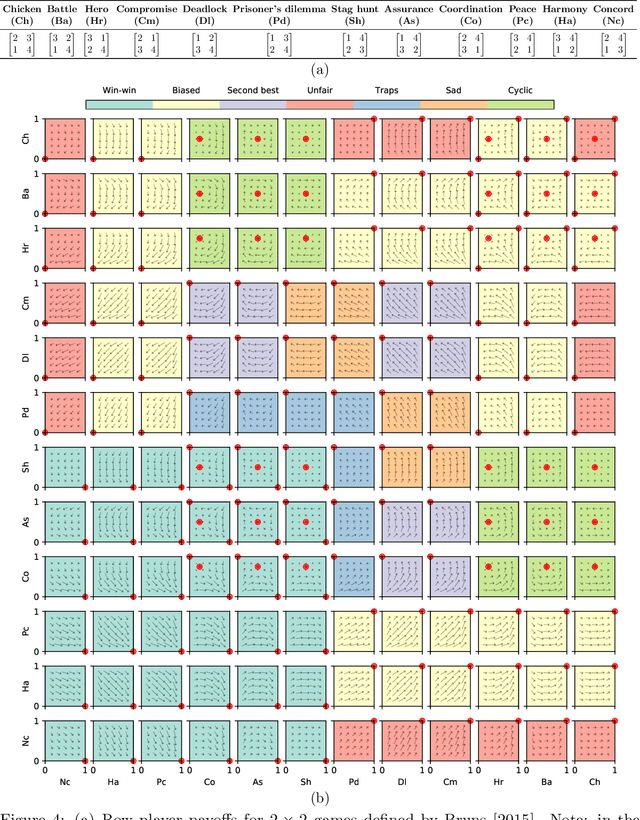
Regret has been established as a foundational concept in online learning, and likewise has important applications in the analysis of learning dynamics in games. Regret quantifies the difference between a learner's performance against a baseline in hindsight. It is well-known that regret-minimizing algorithms converge to certain classes of equilibria in games; however, traditional forms of regret used in game theory predominantly consider baselines that permit deviations to deterministic actions or strategies. In this paper, we revisit our understanding of regret from the perspective of deviations over partitions of the full \emph{mixed} strategy space (i.e., probability distributions over pure strategies), under the lens of the previously-established $\Phi$-regret framework, which provides a continuum of stronger regret measures. Importantly, $\Phi$-regret enables learning agents to consider deviations from and to mixed strategies, generalizing several existing notions of regret such as external, internal, and swap regret, and thus broadening the insights gained from regret-based analysis of learning algorithms. We prove here that the well-studied evolutionary learning algorithm of replicator dynamics (RD) seamlessly minimizes the strongest possible form of $\Phi$-regret in generic $2 \times 2$ games, without any modification of the underlying algorithm itself. We subsequently conduct experiments validating our theoretical results in a suite of 144 $2 \times 2$ games wherein RD exhibits a diverse set of behaviors. We conclude by providing empirical evidence of $\Phi$-regret minimization by RD in some larger games, hinting at further opportunity for $\Phi$-regret based study of such algorithms from both a theoretical and empirical perspective.
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021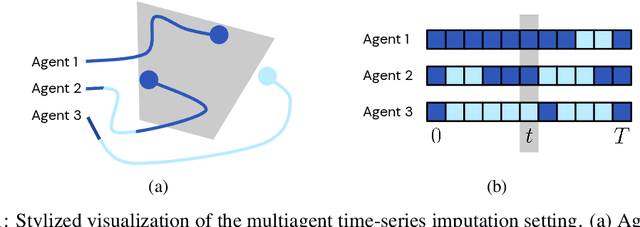
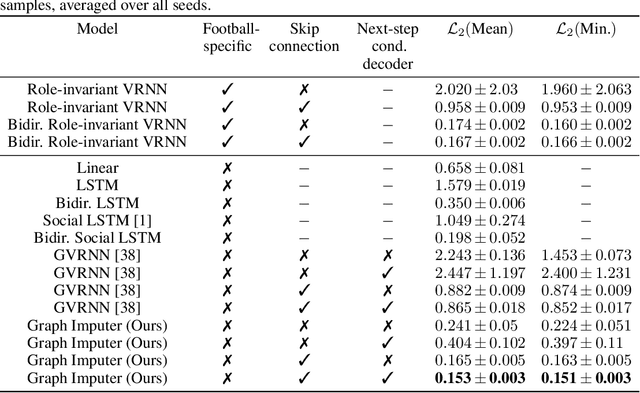
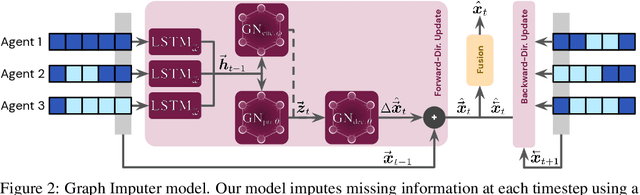
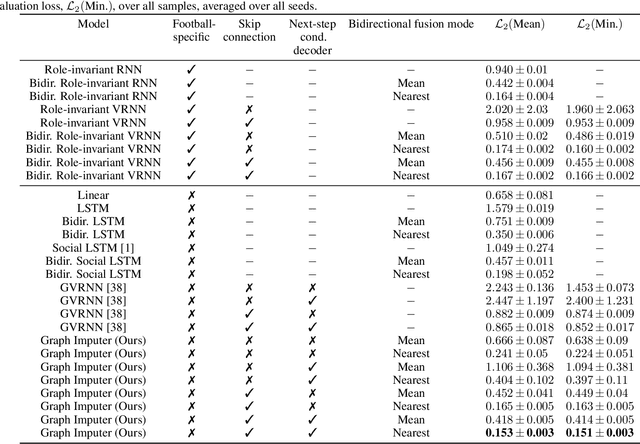
In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021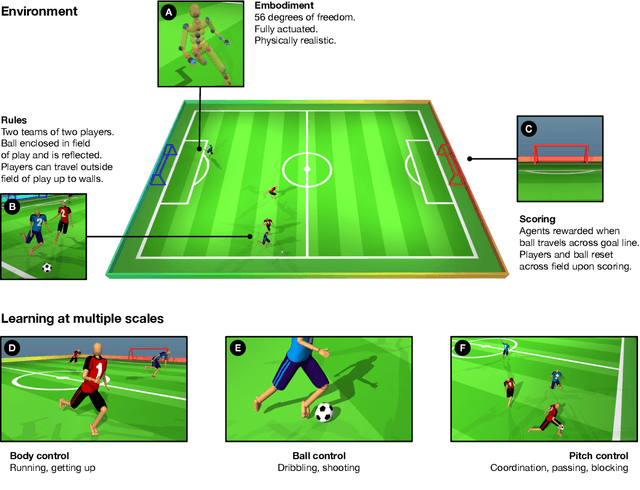

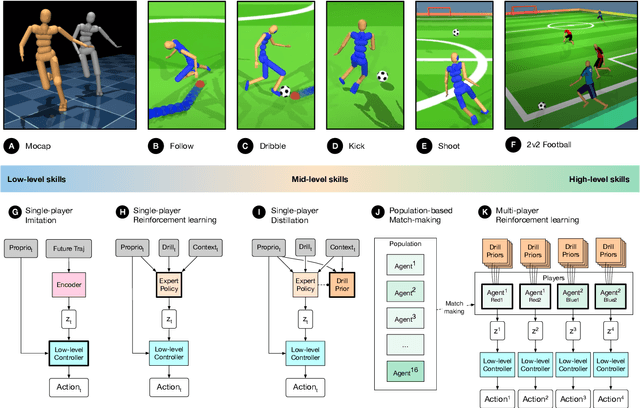

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.