 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Light Video Enhancement with Synthetic Event Guidance
Aug 23, 2022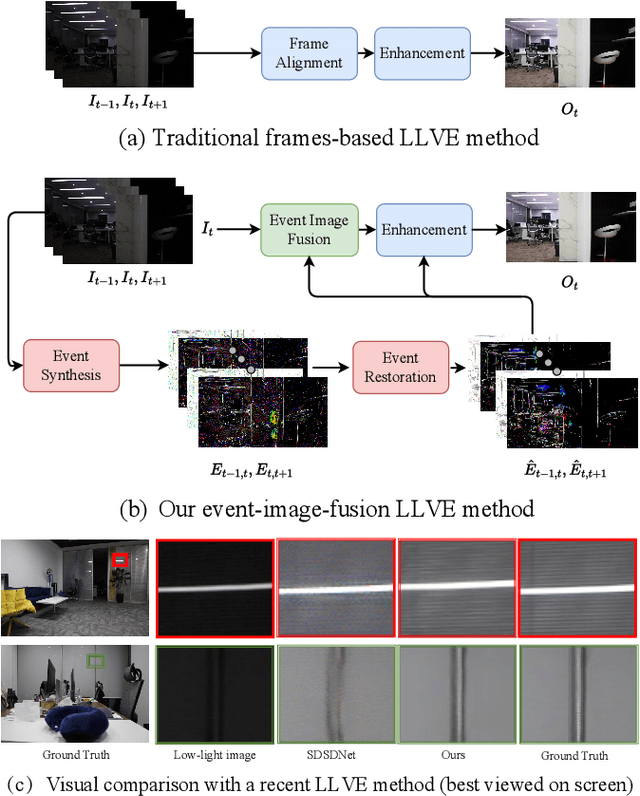
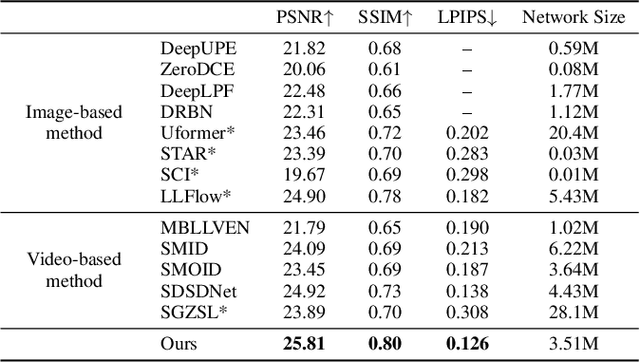

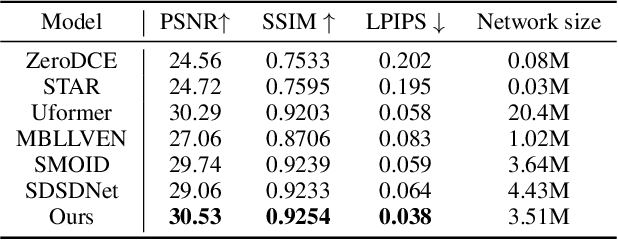
Low-light video enhancement (LLVE) is an important yet challenging task with many applications such as photographing and autonomous driving. Unlike single image low-light enhancement, most LLVE methods utilize temporal information from adjacent frames to restore the color and remove the noise of the target frame. However, these algorithms, based on the framework of multi-frame alignment and enhancement, may produce multi-frame fusion artifacts when encountering extreme low light or fast motion. In this paper, inspired by the low latency and high dynamic range of events, we use synthetic events from multiple frames to guide the enhancement and restoration of low-light videos. Our method contains three stages: 1) event synthesis and enhancement, 2) event and image fusion, and 3) low-light enhancement. In this framework, we design two novel modules (event-image fusion transform and event-guided dual branch) for the second and third stages, respectively. Extensive experiments show that our method outperforms existing low-light video or single image enhancement approaches on both synthetic and real LLVE datasets.
Disentangling 3D Attributes from a Single 2D Image: Human Pose, Shape and Garment
Aug 05, 2022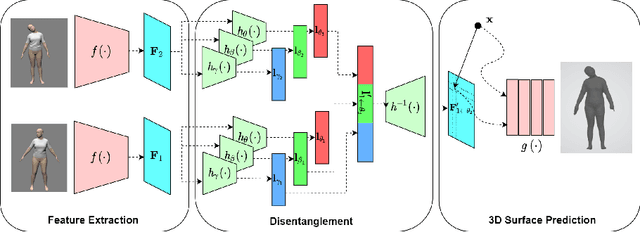

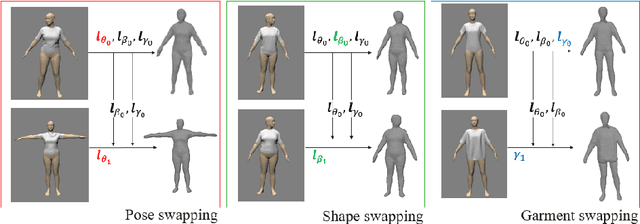
For visual manipulation tasks, we aim to represent image content with semantically meaningful features. However, learning implicit representations from images often lacks interpretability, especially when attributes are intertwined. We focus on the challenging task of extracting disentangled 3D attributes only from 2D image data. Specifically, we focus on human appearance and learn implicit pose, shape and garment representations of dressed humans from RGB images. Our method learns an embedding with disentangled latent representations of these three image properties and enables meaningful re-assembling of features and property control through a 2D-to-3D encoder-decoder structure. The 3D model is inferred solely from the feature map in the learned embedding space. To the best of our knowledge, our method is the first to achieve cross-domain disentanglement for this highly under-constrained problem. We qualitatively and quantitatively demonstrate our framework's ability to transfer pose, shape, and garments in 3D reconstruction on virtual data and show how an implicit shape loss can benefit the model's ability to recover fine-grained reconstruction details.
SJ-HD^2R: Selective Joint High Dynamic Range and Denoising Imaging for Dynamic Scenes
Jun 20, 2022



Ghosting artifacts, motion blur, and low fidelity in highlight are the main challenges in High Dynamic Range (HDR) imaging from multiple Low Dynamic Range (LDR) images. These issues come from using the medium-exposed image as the reference frame in previous methods. To deal with them, we propose to use the under-exposed image as the reference to avoid these issues. However, the heavy noise in dark regions of the under-exposed image becomes a new problem. Therefore, we propose a joint HDR and denoising pipeline, containing two sub-networks: (i) a pre-denoising network (PreDNNet) to adaptively denoise input LDRs by exploiting exposure priors; (ii) a pyramid cascading fusion network (PCFNet), introducing an attention mechanism and cascading structure in a multi-scale manner. To further leverage these two paradigms, we propose a selective and joint HDR and denoising (SJ-HD$^2$R) imaging framework, utilizing scenario-specific priors to conduct the path selection with an accuracy of more than 93.3$\%$. We create the first joint HDR and denoising benchmark dataset, which contains a variety of challenging HDR and denoising scenes and supports the switching of the reference image. Extensive experiment results show that our method achieves superior performance to previous methods.
TAPE: Task-Agnostic Prior Embedding for Image Restoration
Mar 11, 2022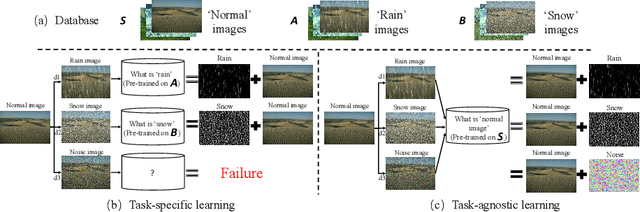

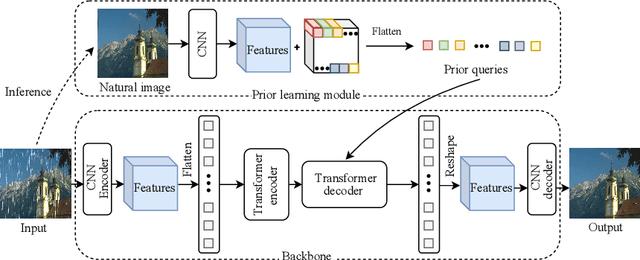

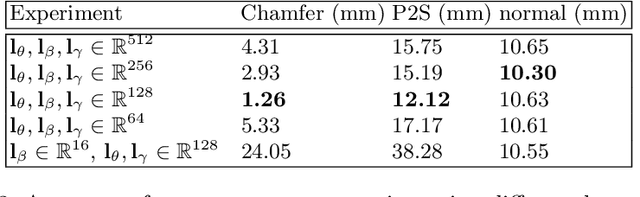
Learning an generalized prior for natural image restoration is an important yet challenging task. Early methods mostly involved handcrafted priors including normalized sparsity, L0 gradients, dark channel priors, etc. Recently, deep neural networks have been used to learn various image priors but do not guarantee to generalize. In this paper, we propose a novel approach that embeds a task-agnostic prior into a transformer. Our approach, named Task-Agnostic Prior Embedding (TAPE), consists of three stages, namely, task-agnostic pre-training, task-agnostic fine-tuning, and task-specific fine-tuning, where the first one embeds prior knowledge about natural images into the transformer and the latter two extracts the knowledge to assist downstream image restoration. Experiments on various types of degradation validate the effectiveness of TAPE. The image restoration performance in terms of PSNR is improved by as much as 1.45 dB and even outperforms task-specific algorithms. More importantly, TAPE shows the ability of disentangling generalized image priors from degraded images, which enjoys favorable transfer ability to unknown downstream tasks.
SiamTrans: Zero-Shot Multi-Frame Image Restoration with Pre-Trained Siamese Transformers
Dec 17, 2021
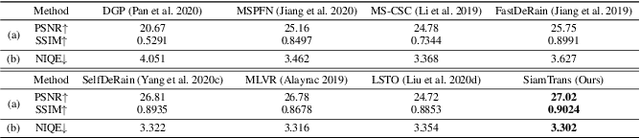
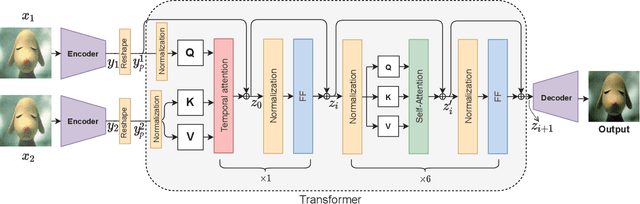
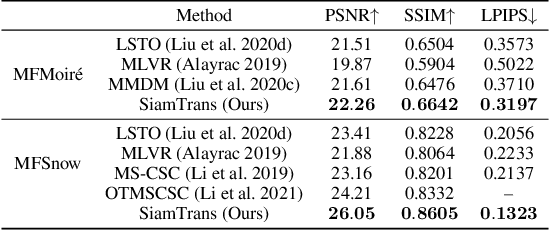
We propose a novel zero-shot multi-frame image restoration method for removing unwanted obstruction elements (such as rains, snow, and moire patterns) that vary in successive frames. It has three stages: transformer pre-training, zero-shot restoration, and hard patch refinement. Using the pre-trained transformers, our model is able to tell the motion difference between the true image information and the obstructing elements. For zero-shot image restoration, we design a novel model, termed SiamTrans, which is constructed by Siamese transformers, encoders, and decoders. Each transformer has a temporal attention layer and several self-attention layers, to capture both temporal and spatial information of multiple frames. Only pre-trained (self-supervised) on the denoising task, SiamTrans is tested on three different low-level vision tasks (deraining, demoireing, and desnowing). Compared with related methods, ours achieves the best performances, even outperforming those with supervised learning.
Wavelet-Based Network For High Dynamic Range Imaging
Aug 03, 2021


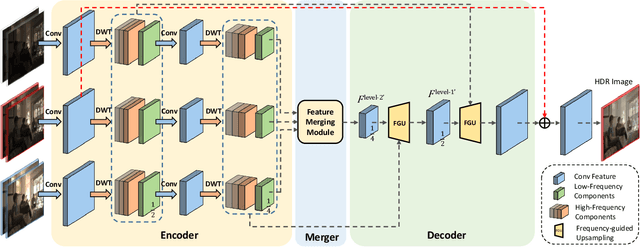
High dynamic range (HDR) imaging from multiple low dynamic range (LDR) images has been suffering from ghosting artifacts caused by scene and objects motion. Existing methods, such as optical flow based and end-to-end deep learning based solutions, are error-prone either in detail restoration or ghosting artifacts removal. Comprehensive empirical evidence shows that ghosting artifacts caused by large foreground motion are mainly low-frequency signals and the details are mainly high-frequency signals. In this work, we propose a novel frequency-guided end-to-end deep neural network (FHDRNet) to conduct HDR fusion in the frequency domain, and Discrete Wavelet Transform (DWT) is used to decompose inputs into different frequency bands. The low-frequency signals are used to avoid specific ghosting artifacts, while the high-frequency signals are used for preserving details. Using a U-Net as the backbone, we propose two novel modules: merging module and frequency-guided upsampling module. The merging module applies the attention mechanism to the low-frequency components to deal with the ghost caused by large foreground motion. The frequency-guided upsampling module reconstructs details from multiple frequency-specific components with rich details. In addition, a new RAW dataset is created for training and evaluating multi-frame HDR imaging algorithms in the RAW domain. Extensive experiments are conducted on public datasets and our RAW dataset, showing that the proposed FHDRNet achieves state-of-the-art performance.
Self-Adaptively Learning to Demoire from Focused and Defocused Image Pairs
Nov 05, 2020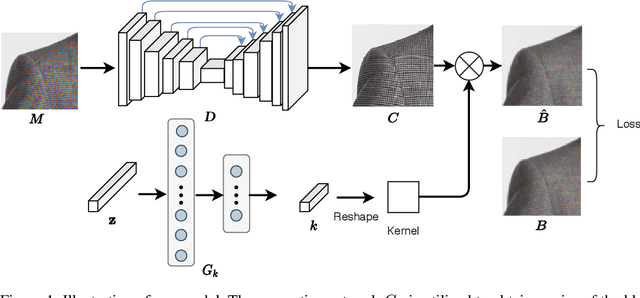



Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moire patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.
Video Super-resolution with Temporal Group Attention
Jul 21, 2020
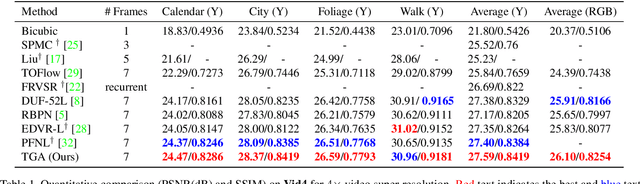
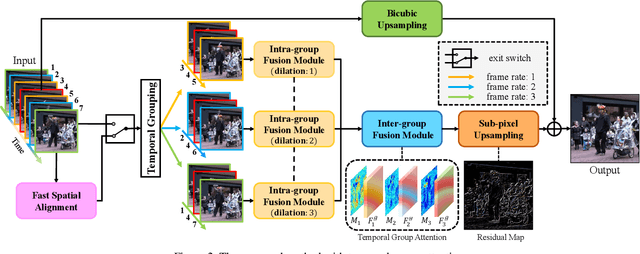

Video super-resolution, which aims at producing a high-resolution video from its corresponding low-resolution version, has recently drawn increasing attention. In this work, we propose a novel method that can effectively incorporate temporal information in a hierarchical way. The input sequence is divided into several groups, with each one corresponding to a kind of frame rate. These groups provide complementary information to recover missing details in the reference frame, which is further integrated with an attention module and a deep intra-group fusion module. In addition, a fast spatial alignment is proposed to handle videos with large motion. Extensive results demonstrate the capability of the proposed model in handling videos with various motion. It achieves favorable performance against state-of-the-art methods on several benchmark datasets.
Wavelet-Based Dual-Branch Network for Image Demoireing
Jul 17, 2020

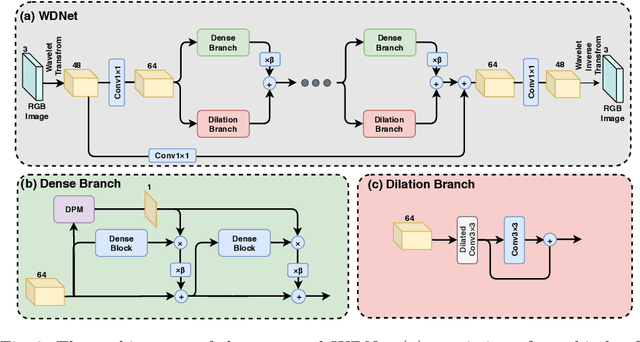

When smartphone cameras are used to take photos of digital screens, usually moire patterns result, severely degrading photo quality. In this paper, we design a wavelet-based dual-branch network (WDNet) with a spatial attention mechanism for image demoireing. Existing image restoration methods working in the RGB domain have difficulty in distinguishing moire patterns from true scene texture. Unlike these methods, our network removes moire patterns in the wavelet domain to separate the frequencies of moire patterns from the image content. The network combines dense convolution modules and dilated convolution modules supporting large receptive fields. Extensive experiments demonstrate the effectiveness of our method, and we further show that WDNet generalizes to removing moire artifacts on non-screen images. Although designed for image demoireing, WDNet has been applied to two other low-levelvision tasks, outperforming state-of-the-art image deraining and derain-drop methods on the Rain100h and Raindrop800 data sets, respectively.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.