 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation
Dec 15, 2022Human evaluation is the foundation upon which the evaluation of both summarization systems and automatic metrics rests. However, existing human evaluation protocols and benchmarks for summarization either exhibit low inter-annotator agreement or lack the scale needed to draw statistically significant conclusions, and an in-depth analysis of human evaluation is lacking. In this work, we address the shortcomings of existing summarization evaluation along the following axes: 1) We propose a modified summarization salience protocol, Atomic Content Units (ACUs), which relies on fine-grained semantic units and allows for high inter-annotator agreement. 2) We curate the Robust Summarization Evaluation (RoSE) benchmark, a large human evaluation dataset consisting of over 22k summary-level annotations over state-of-the-art systems on three datasets. 3) We compare our ACU protocol with three other human evaluation protocols, underscoring potential confounding factors in evaluation setups. 4) We evaluate existing automatic metrics using the collected human annotations across evaluation protocols and demonstrate how our benchmark leads to more statistically stable and significant results. Furthermore, our findings have important implications for evaluating large language models (LLMs), as we show that LLMs adjusted by human feedback (e.g., GPT-3.5) may overfit unconstrained human evaluation, which is affected by the annotators' prior, input-agnostic preferences, calling for more robust, targeted evaluation methods.
Learning Label Modular Prompts for Text Classification in the Wild
Dec 05, 2022



Machine learning models usually assume i.i.d data during training and testing, but data and tasks in real world often change over time. To emulate the transient nature of real world, we propose a challenging but practical task: text classification in-the-wild, which introduces different non-stationary training/testing stages. Decomposing a complex task into modular components can enable robust generalisation under such non-stationary environment. However, current modular approaches in NLP do not take advantage of recent advances in parameter efficient tuning of pretrained language models. To close this gap, we propose MODULARPROMPT, a label-modular prompt tuning framework for text classification tasks. In MODULARPROMPT, the input prompt consists of a sequence of soft label prompts, each encoding modular knowledge related to the corresponding class label. In two of most formidable settings, MODULARPROMPT outperforms relevant baselines by a large margin demonstrating strong generalisation ability. We also conduct comprehensive analysis to validate whether the learned prompts satisfy properties of a modular representation.
BotSIM: An End-to-End Bot Simulation Toolkit for Commercial Task-Oriented Dialog Systems
Nov 30, 2022



We introduce BotSIM, a modular, open-source Bot SIMulation environment with dialog generation, user simulation and conversation analytics capabilities. BotSIM aims to serve as a one-stop solution for large-scale data-efficient end-to-end evaluation, diagnosis and remediation of commercial task-oriented dialog (TOD) systems to significantly accelerate commercial bot development and evaluation, reduce cost and time-to-market. BotSIM adopts a layered design comprising the infrastructure layer, the adaptor layer and the application layer. The infrastructure layer hosts key models and components to support BotSIM's major functionalities via a streamlined "generation-simulation-remediation" pipeline. The adaptor layer is used to extend BotSIM to accommodate new bot platforms. The application layer provides a suite of command line tools and a Web App to significantly lower the entry barrier for BotSIM users such as bot admins or practitioners. In this report, we focus on the technical designs of various system components. A detailed case study using Einstein BotBuilder is also presented to show how to apply BotSIM pipeline for bot evaluation and remediation. The detailed system descriptions can be found in our system demo paper. The toolkit is available at: https://github.com/salesforce/BotSIM .
BotSIM: An End-to-End Bot Simulation Framework for Commercial Task-Oriented Dialog Systems
Nov 30, 2022



We present BotSIM, a data-efficient end-to-end Bot SIMulation toolkit for commercial text-based task-oriented dialog (TOD) systems. BotSIM consists of three major components: 1) a Generator that can infer semantic-level dialog acts and entities from bot definitions and generate user queries via model-based paraphrasing; 2) an agenda-based dialog user Simulator (ABUS) to simulate conversations with the dialog agents; 3) a Remediator to analyze the simulated conversations, visualize the bot health reports and provide actionable remediation suggestions for bot troubleshooting and improvement. We demonstrate BotSIM's effectiveness in end-to-end evaluation, remediation and multi-intent dialog generation via case studies on two commercial bot platforms. BotSIM's "generation-simulation-remediation" paradigm accelerates the end-to-end bot evaluation and iteration process by: 1) reducing manual test cases creation efforts; 2) enabling a holistic gauge of the bot in terms of NLU and end-to-end performance via extensive dialog simulation; 3) improving the bot troubleshooting process with actionable suggestions. A demo of our system can be found at https://tinyurl.com/mryu74cd and a demo video at https://youtu.be/qLi5iSoly30. We have open-sourced the toolkit at https://github.com/salesforce/botsim
Towards Robust Low-Resource Fine-Tuning with Multi-View Compressed Representations
Nov 16, 2022Due to the huge amount of parameters, fine-tuning of pretrained language models (PLMs) is prone to overfitting in the low resource scenarios. In this work, we present a novel method that operates on the hidden representations of a PLM to reduce overfitting. During fine-tuning, our method inserts random autoencoders between the hidden layers of a PLM, which transform activations from the previous layers into a multi-view compressed representation before feeding it into the upper layers. The autoencoders are plugged out after fine-tuning, so our method does not add extra parameters or increase computation cost during inference. Our method demonstrates promising performance improvement across a wide range of sequence- and token-level low-resource NLP tasks.
Alleviating Sparsity of Open Knowledge Graphs with Ternary Contrastive Learning
Nov 08, 2022Sparsity of formal knowledge and roughness of non-ontological construction make sparsity problem particularly prominent in Open Knowledge Graphs (OpenKGs). Due to sparse links, learning effective representation for few-shot entities becomes difficult. We hypothesize that by introducing negative samples, a contrastive learning (CL) formulation could be beneficial in such scenarios. However, existing CL methods model KG triplets as binary objects of entities ignoring the relation-guided ternary propagation patterns and they are too generic, i.e., they ignore zero-shot, few-shot and synonymity problems that appear in OpenKGs. To address this, we propose TernaryCL, a CL framework based on ternary propagation patterns among head, relation and tail. TernaryCL designs Contrastive Entity and Contrastive Relation to mine ternary discriminative features with both negative entities and relations, introduces Contrastive Self to help zero- and few-shot entities learn discriminative features, Contrastive Synonym to model synonymous entities, and Contrastive Fusion to aggregate graph features from multiple paths. Extensive experiments on benchmarks demonstrate the superiority of TernaryCL over state-of-the-art models.
Towards Summary Candidates Fusion
Oct 17, 2022
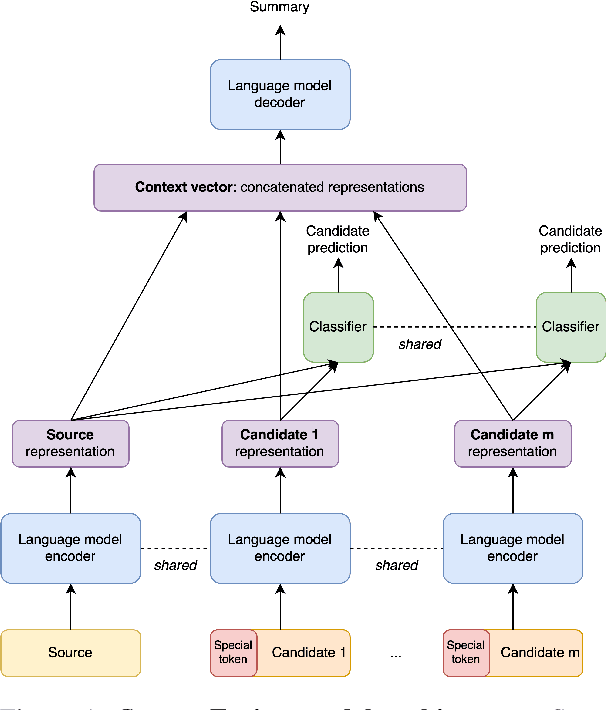

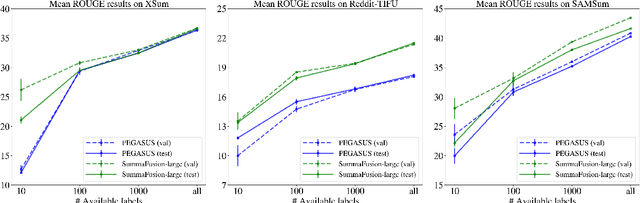
Sequence-to-sequence deep neural models fine-tuned for abstractive summarization can achieve great performance on datasets with enough human annotations. Yet, it has been shown that they have not reached their full potential, with a wide gap between the top beam search output and the oracle beam. Recently, re-ranking methods have been proposed, to learn to select a better summary candidate. However, such methods are limited by the summary quality aspects captured by the first-stage candidates. To bypass this limitation, we propose a new paradigm in second-stage abstractive summarization called SummaFusion that fuses several summary candidates to produce a novel abstractive second-stage summary. Our method works well on several summarization datasets, improving both the ROUGE scores and qualitative properties of fused summaries. It is especially good when the candidates to fuse are worse, such as in the few-shot setup where we set a new state-of-the-art. We will make our code and checkpoints available at https://github.com/ntunlp/SummaFusion/.
OpenCQA: Open-ended Question Answering with Charts
Oct 12, 2022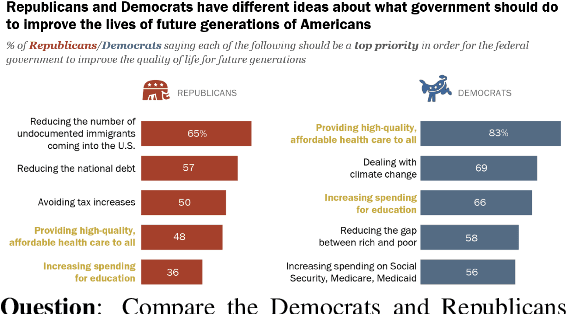

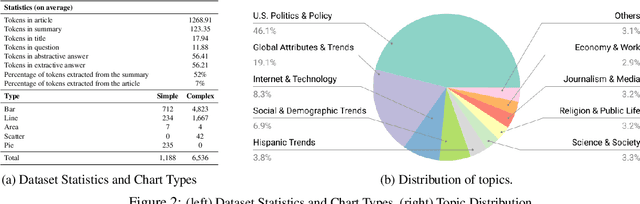
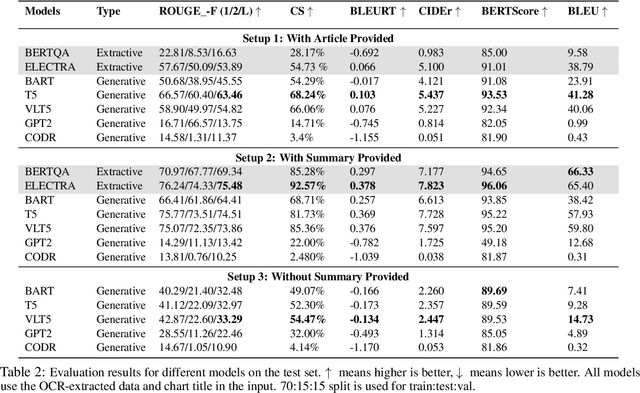
Charts are very popular to analyze data and convey important insights. People often analyze visualizations to answer open-ended questions that require explanatory answers. Answering such questions are often difficult and time-consuming as it requires a lot of cognitive and perceptual efforts. To address this challenge, we introduce a new task called OpenCQA, where the goal is to answer an open-ended question about a chart with descriptive texts. We present the annotation process and an in-depth analysis of our dataset. We implement and evaluate a set of baselines under three practical settings. In the first setting, a chart and the accompanying article is provided as input to the model. The second setting provides only the relevant paragraph(s) to the chart instead of the entire article, whereas the third setting requires the model to generate an answer solely based on the chart. Our analysis of the results show that the top performing models generally produce fluent and coherent text while they struggle to perform complex logical and arithmetic reasoning.
Improving Conversational Recommender System via Contextual and Time-Aware Modeling with Less Domain-Specific Knowledge
Sep 23, 2022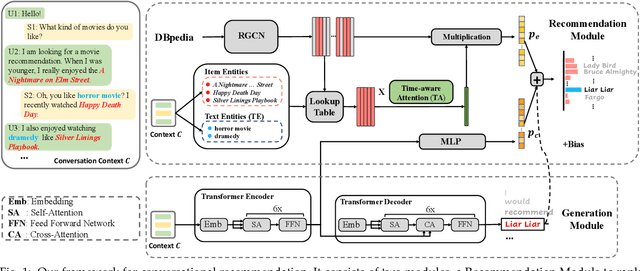
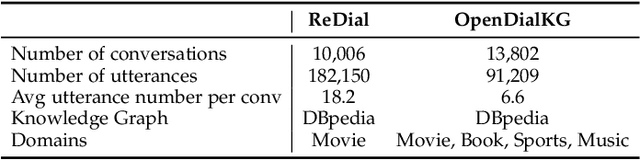
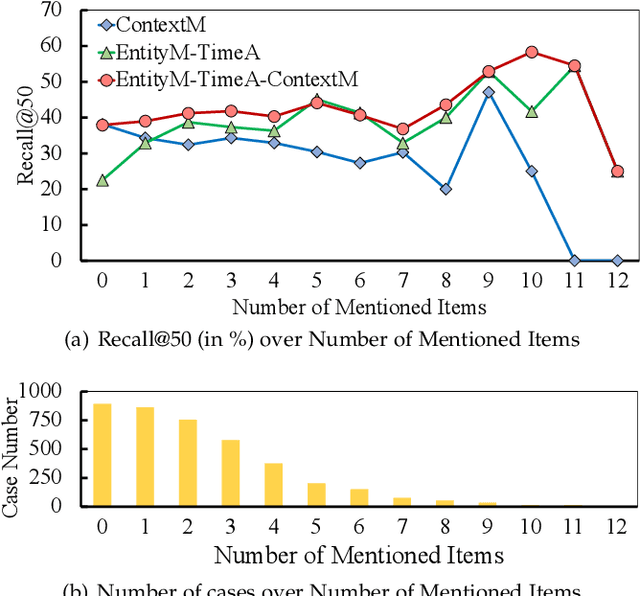
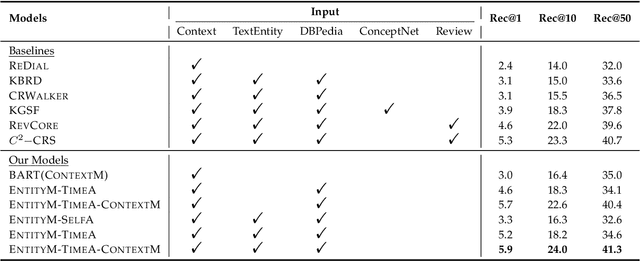
Conversational Recommender Systems (CRS) has become an emerging research topic seeking to perform recommendations through interactive conversations, which generally consist of generation and recommendation modules. Prior work on CRS tends to incorporate more external and domain-specific knowledge like item reviews to enhance performance. Despite the fact that the collection and annotation of the external domain-specific information needs much human effort and degenerates the generalizability, too much extra knowledge introduces more difficulty to balance among them. Therefore, we propose to fully discover and extract internal knowledge from the context. We capture both entity-level and contextual-level representations to jointly model user preferences for the recommendation, where a time-aware attention is designed to emphasize the recently appeared items in entity-level representations. We further use the pre-trained BART to initialize the generation module to alleviate the data scarcity and enhance the context modeling. In addition to conducting experiments on a popular dataset (ReDial), we also include a multi-domain dataset (OpenDialKG) to show the effectiveness of our model. Experiments on both datasets show that our model achieves better performance on most evaluation metrics with less external knowledge and generalizes well to other domains. Additional analyses on the recommendation and generation tasks demonstrate the effectiveness of our model in different scenarios.
CoHS-CQG: Context and History Selection for Conversational Question Generation
Sep 14, 2022
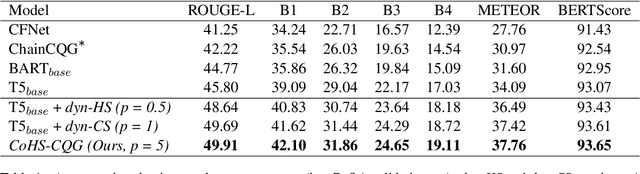
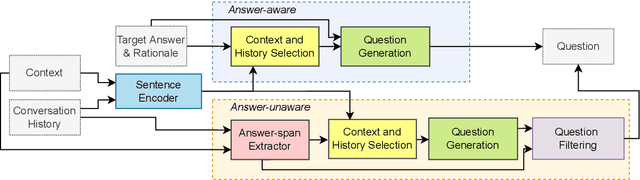
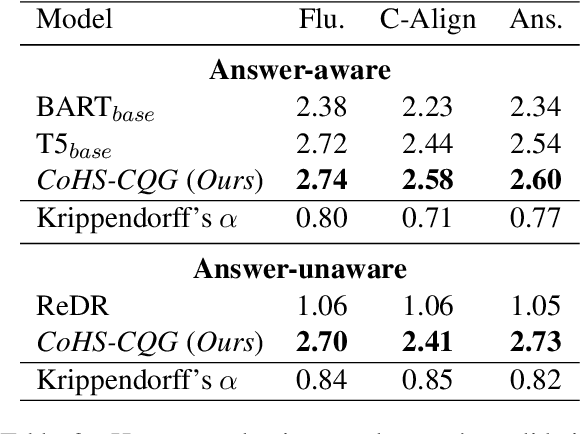
Conversational question generation (CQG) serves as a vital task for machines to assist humans, such as interactive reading comprehension, through conversations. Compared to traditional single-turn question generation (SQG), CQG is more challenging in the sense that the generated question is required not only to be meaningful, but also to align with the occurred conversation history. While previous studies mainly focus on how to model the flow and alignment of the conversation, there has been no thorough study to date on which parts of the context and history are necessary for the model. We argue that shortening the context and history is crucial as it can help the model to optimise more on the conversational alignment property. To this end, we propose CoHS-CQG, a two-stage CQG framework, which adopts a CoHS module to shorten the context and history of the input. In particular, CoHS selects contiguous sentences and history turns according to their relevance scores by a top-p strategy. Our model achieves state-of-the-art performances on CoQA in both the answer-aware and answer-unaware settings.