 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Attention: Semantic-aware Attention Values for Concept Personalization
Jan 02, 2025Personalizing text-to-image models to generate images of specific subjects across diverse scenes and styles is a rapidly advancing field. Current approaches often face challenges in maintaining a balance between identity preservation and alignment with the input text prompt. Some methods rely on a single textual token to represent a subject, which limits expressiveness, while others employ richer representations but disrupt the model's prior, diminishing prompt alignment. In this work, we introduce Nested Attention, a novel mechanism that injects a rich and expressive image representation into the model's existing cross-attention layers. Our key idea is to generate query-dependent subject values, derived from nested attention layers that learn to select relevant subject features for each region in the generated image. We integrate these nested layers into an encoder-based personalization method, and show that they enable high identity preservation while adhering to input text prompts. Our approach is general and can be trained on various domains. Additionally, its prior preservation allows us to combine multiple personalized subjects from different domains in a single image.
AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Dec 19, 2024



We propose AV-Link, a unified framework for Video-to-Audio and Audio-to-Video generation that leverages the activations of frozen video and audio diffusion models for temporally-aligned cross-modal conditioning. The key to our framework is a Fusion Block that enables bidirectional information exchange between our backbone video and audio diffusion models through a temporally-aligned self attention operation. Unlike prior work that uses feature extractors pretrained for other tasks for the conditioning signal, AV-Link can directly leverage features obtained by the complementary modality in a single framework i.e. video features to generate audio, or audio features to generate video. We extensively evaluate our design choices and demonstrate the ability of our method to achieve synchronized and high-quality audiovisual content, showcasing its potential for applications in immersive media generation. Project Page: snap-research.github.io/AVLink/
Wonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024



This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024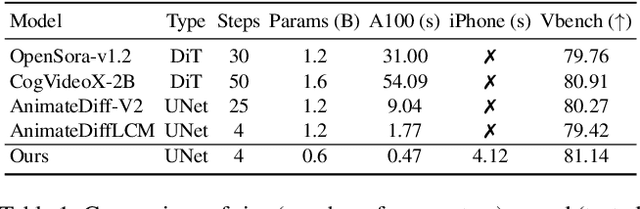
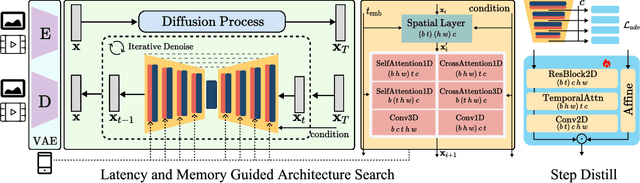
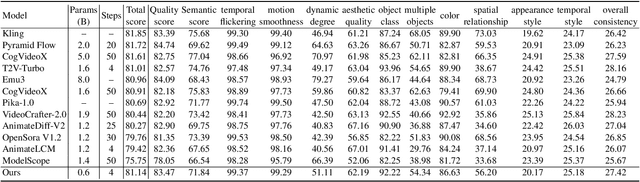
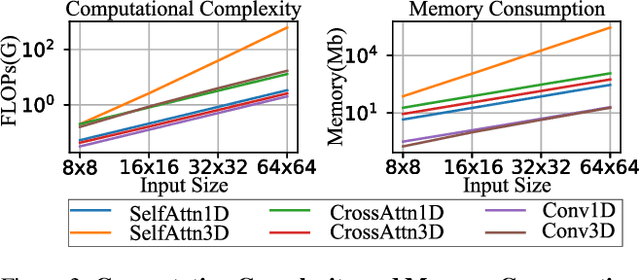
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
Omni-ID: Holistic Identity Representation Designed for Generative Tasks
Dec 12, 2024We introduce Omni-ID, a novel facial representation designed specifically for generative tasks. Omni-ID encodes holistic information about an individual's appearance across diverse expressions and poses within a fixed-size representation. It consolidates information from a varied number of unstructured input images into a structured representation, where each entry represents certain global or local identity features. Our approach uses a few-to-many identity reconstruction training paradigm, where a limited set of input images is used to reconstruct multiple target images of the same individual in various poses and expressions. A multi-decoder framework is further employed to leverage the complementary strengths of diverse decoders during training. Unlike conventional representations, such as CLIP and ArcFace, which are typically learned through discriminative or contrastive objectives, Omni-ID is optimized with a generative objective, resulting in a more comprehensive and nuanced identity capture for generative tasks. Trained on our MFHQ dataset -- a multi-view facial image collection, Omni-ID demonstrates substantial improvements over conventional representations across various generative tasks.
Video Motion Transfer with Diffusion Transformers
Dec 10, 2024



We propose DiTFlow, a method for transferring the motion of a reference video to a newly synthesized one, designed specifically for Diffusion Transformers (DiT). We first process the reference video with a pre-trained DiT to analyze cross-frame attention maps and extract a patch-wise motion signal called the Attention Motion Flow (AMF). We guide the latent denoising process in an optimization-based, training-free, manner by optimizing latents with our AMF loss to generate videos reproducing the motion of the reference one. We also apply our optimization strategy to transformer positional embeddings, granting us a boost in zero-shot motion transfer capabilities. We evaluate DiTFlow against recently published methods, outperforming all across multiple metrics and human evaluation.
Mind the Time: Temporally-Controlled Multi-Event Video Generation
Dec 06, 2024



Real-world videos consist of sequences of events. Generating such sequences with precise temporal control is infeasible with existing video generators that rely on a single paragraph of text as input. When tasked with generating multiple events described using a single prompt, such methods often ignore some of the events or fail to arrange them in the correct order. To address this limitation, we present MinT, a multi-event video generator with temporal control. Our key insight is to bind each event to a specific period in the generated video, which allows the model to focus on one event at a time. To enable time-aware interactions between event captions and video tokens, we design a time-based positional encoding method, dubbed ReRoPE. This encoding helps to guide the cross-attention operation. By fine-tuning a pre-trained video diffusion transformer on temporally grounded data, our approach produces coherent videos with smoothly connected events. For the first time in the literature, our model offers control over the timing of events in generated videos. Extensive experiments demonstrate that MinT outperforms existing open-source models by a large margin.
4Real-Video: Learning Generalizable Photo-Realistic 4D Video Diffusion
Dec 05, 2024



We propose 4Real-Video, a novel framework for generating 4D videos, organized as a grid of video frames with both time and viewpoint axes. In this grid, each row contains frames sharing the same timestep, while each column contains frames from the same viewpoint. We propose a novel two-stream architecture. One stream performs viewpoint updates on columns, and the other stream performs temporal updates on rows. After each diffusion transformer layer, a synchronization layer exchanges information between the two token streams. We propose two implementations of the synchronization layer, using either hard or soft synchronization. This feedforward architecture improves upon previous work in three ways: higher inference speed, enhanced visual quality (measured by FVD, CLIP, and VideoScore), and improved temporal and viewpoint consistency (measured by VideoScore and Dust3R-Confidence).
AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers
Dec 02, 2024



Numerous works have recently integrated 3D camera control into foundational text-to-video models, but the resulting camera control is often imprecise, and video generation quality suffers. In this work, we analyze camera motion from a first principles perspective, uncovering insights that enable precise 3D camera manipulation without compromising synthesis quality. First, we determine that motion induced by camera movements in videos is low-frequency in nature. This motivates us to adjust train and test pose conditioning schedules, accelerating training convergence while improving visual and motion quality. Then, by probing the representations of an unconditional video diffusion transformer, we observe that they implicitly perform camera pose estimation under the hood, and only a sub-portion of their layers contain the camera information. This suggested us to limit the injection of camera conditioning to a subset of the architecture to prevent interference with other video features, leading to 4x reduction of training parameters, improved training speed and 10% higher visual quality. Finally, we complement the typical dataset for camera control learning with a curated dataset of 20K diverse dynamic videos with stationary cameras. This helps the model disambiguate the difference between camera and scene motion, and improves the dynamics of generated pose-conditioned videos. We compound these findings to design the Advanced 3D Camera Control (AC3D) architecture, the new state-of-the-art model for generative video modeling with camera control.