 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Dec 19, 2024



We propose AV-Link, a unified framework for Video-to-Audio and Audio-to-Video generation that leverages the activations of frozen video and audio diffusion models for temporally-aligned cross-modal conditioning. The key to our framework is a Fusion Block that enables bidirectional information exchange between our backbone video and audio diffusion models through a temporally-aligned self attention operation. Unlike prior work that uses feature extractors pretrained for other tasks for the conditioning signal, AV-Link can directly leverage features obtained by the complementary modality in a single framework i.e. video features to generate audio, or audio features to generate video. We extensively evaluate our design choices and demonstrate the ability of our method to achieve synchronized and high-quality audiovisual content, showcasing its potential for applications in immersive media generation. Project Page: snap-research.github.io/AVLink/
Differentiable Robot Rendering
Oct 17, 2024



Vision foundation models trained on massive amounts of visual data have shown unprecedented reasoning and planning skills in open-world settings. A key challenge in applying them to robotic tasks is the modality gap between visual data and action data. We introduce differentiable robot rendering, a method allowing the visual appearance of a robot body to be directly differentiable with respect to its control parameters. Our model integrates a kinematics-aware deformable model and Gaussians Splatting and is compatible with any robot form factors and degrees of freedom. We demonstrate its capability and usage in applications including reconstruction of robot poses from images and controlling robots through vision language models. Quantitative and qualitative results show that our differentiable rendering model provides effective gradients for robotic control directly from pixels, setting the foundation for the future applications of vision foundation models in robotics.
EraseDraw: Learning to Insert Objects by Erasing Them from Images
Aug 31, 2024



Creative processes such as painting often involve creating different components of an image one by one. Can we build a computational model to perform this task? Prior works often fail by making global changes to the image, inserting objects in unrealistic spatial locations, and generating inaccurate lighting details. We observe that while state-of-the-art models perform poorly on object insertion, they can remove objects and erase the background in natural images very well. Inverting the direction of object removal, we obtain high-quality data for learning to insert objects that are spatially, physically, and optically consistent with the surroundings. With this scalable automatic data generation pipeline, we can create a dataset for learning object insertion, which is used to train our proposed text conditioned diffusion model. Qualitative and quantitative experiments have shown that our model achieves state-of-the-art results in object insertion, particularly for in-the-wild images. We show compelling results on diverse insertion prompts and images across various domains.In addition, we automate iterative insertion by combining our insertion model with beam search guided by CLIP.
Cloth Funnels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation
Oct 17, 2022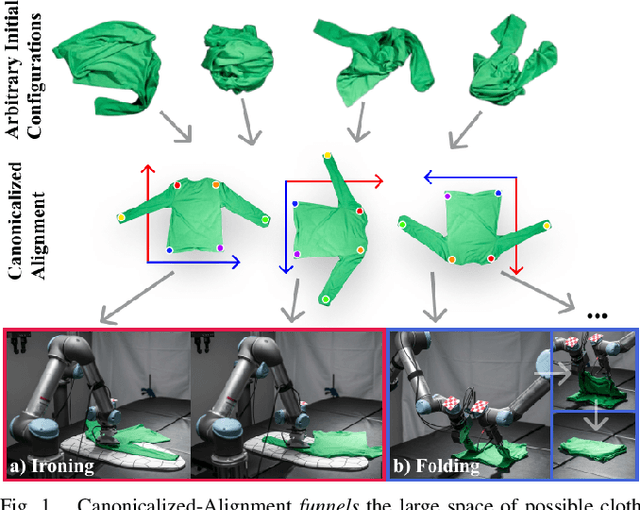
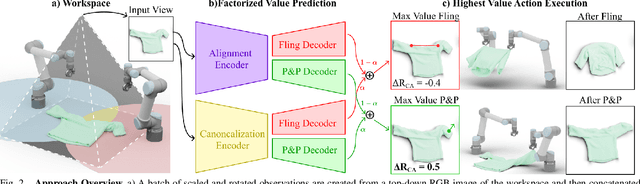
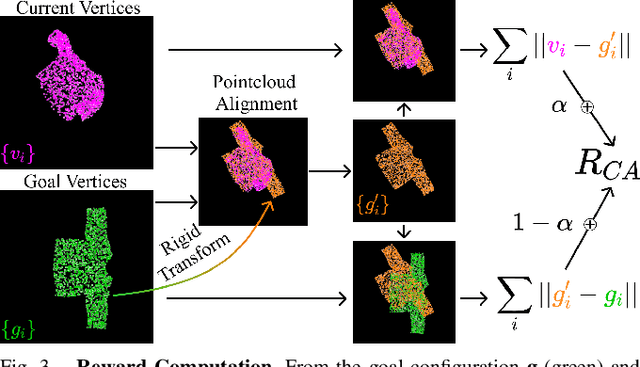
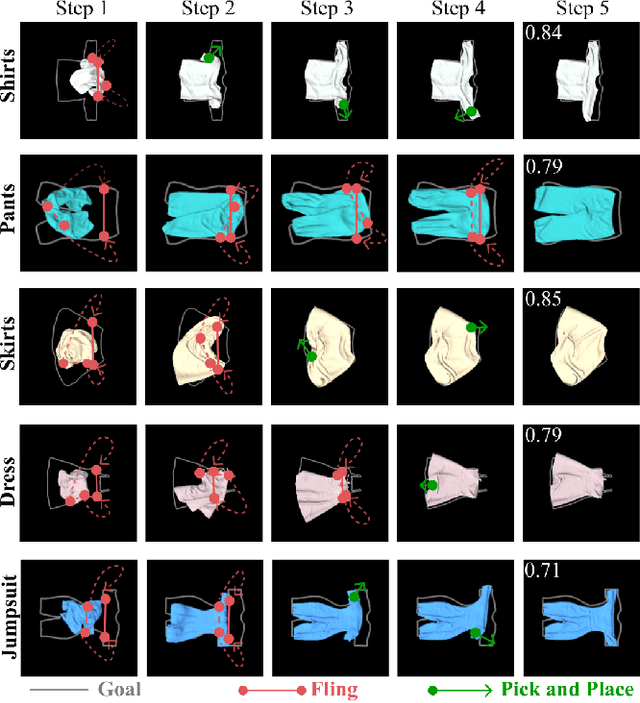
Automating garment manipulation is challenging due to extremely high variability in object configurations. To reduce this intrinsic variation, we introduce the task of "canonicalized-alignment" that simplifies downstream applications by reducing the possible garment configurations. This task can be considered as "cloth state funnel" that manipulates arbitrarily configured clothing items into a predefined deformable configuration (i.e. canonicalization) at an appropriate rigid pose (i.e. alignment). In the end, the cloth items will result in a compact set of structured and highly visible configurations - which are desirable for downstream manipulation skills. To enable this task, we propose a novel canonicalized-alignment objective that effectively guides learning to avoid adverse local minima during learning. Using this objective, we learn a multi-arm, multi-primitive policy that strategically chooses between dynamic flings and quasi-static pick and place actions to achieve efficient canonicalized-alignment. We evaluate this approach on a real-world ironing and folding system that relies on this learned policy as the common first step. Empirically, we demonstrate that our task-agnostic canonicalized-alignment can enable even simple manually-designed policies to work well where they were previously inadequate, thus bridging the gap between automated non-deformable manufacturing and deformable manipulation. Code and qualitative visualizations are available at https://clothfunnels.cs.columbia.edu/. Video can be found at https://www.youtube.com/watch?v=TkUn0b7mbj0.
Learning Human Objectives from Sequences of Physical Corrections
Mar 31, 2021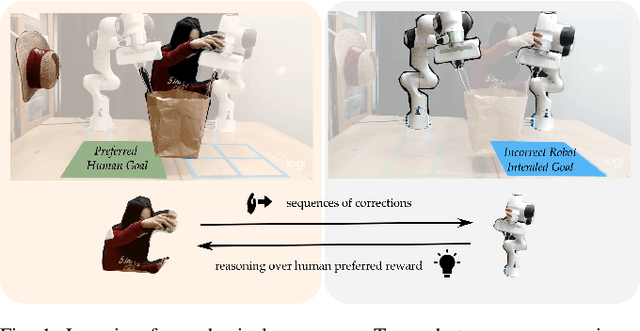
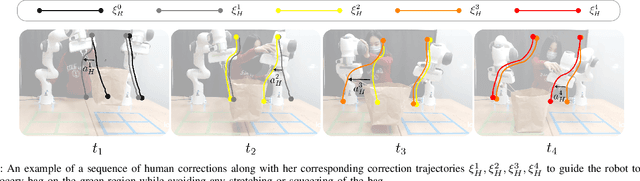
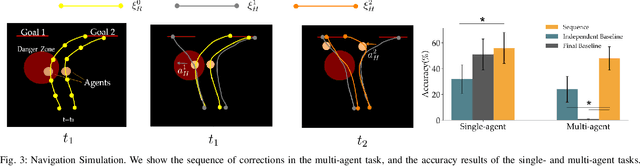
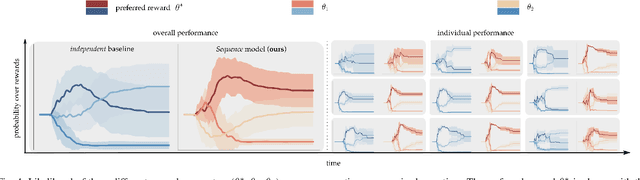
When personal, assistive, and interactive robots make mistakes, humans naturally and intuitively correct those mistakes through physical interaction. In simple situations, one correction is sufficient to convey what the human wants. But when humans are working with multiple robots or the robot is performing an intricate task often the human must make several corrections to fix the robot's behavior. Prior research assumes each of these physical corrections are independent events, and learns from them one-at-a-time. However, this misses out on crucial information: each of these interactions are interconnected, and may only make sense if viewed together. Alternatively, other work reasons over the final trajectory produced by all of the human's corrections. But this method must wait until the end of the task to learn from corrections, as opposed to inferring from the corrections in an online fashion. In this paper we formalize an approach for learning from sequences of physical corrections during the current task. To do this we introduce an auxiliary reward that captures the human's trade-off between making corrections which improve the robot's immediate reward and long-term performance. We evaluate the resulting algorithm in remote and in-person human-robot experiments, and compare to both independent and final baselines. Our results indicate that users are best able to convey their objective when the robot reasons over their sequence of corrections.