 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Contact: Unsupervised Human-Machine Co-Adaptation via Mutual Information Maximization
May 24, 2022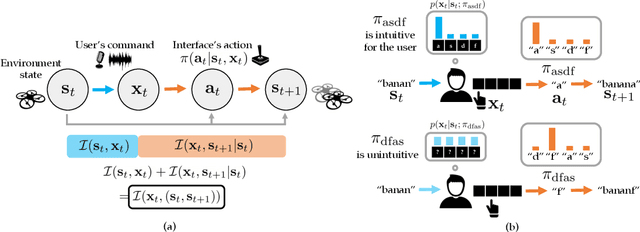

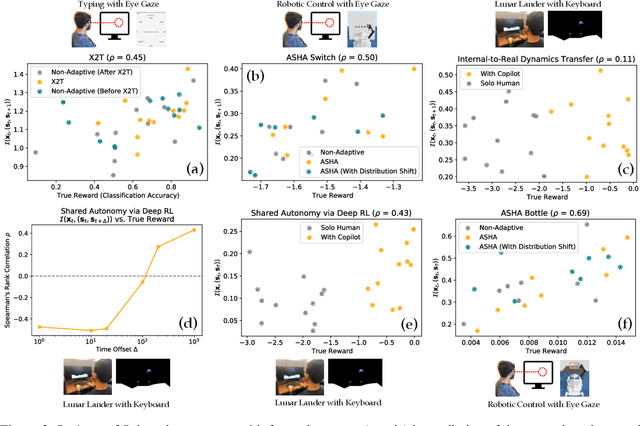
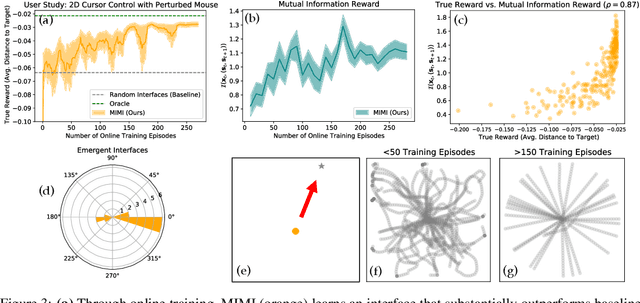
How can we train an assistive human-machine interface (e.g., an electromyography-based limb prosthesis) to translate a user's raw command signals into the actions of a robot or computer when there is no prior mapping, we cannot ask the user for supervision in the form of action labels or reward feedback, and we do not have prior knowledge of the tasks the user is trying to accomplish? The key idea in this paper is that, regardless of the task, when an interface is more intuitive, the user's commands are less noisy. We formalize this idea as a completely unsupervised objective for optimizing interfaces: the mutual information between the user's command signals and the induced state transitions in the environment. To evaluate whether this mutual information score can distinguish between effective and ineffective interfaces, we conduct an observational study on 540K examples of users operating various keyboard and eye gaze interfaces for typing, controlling simulated robots, and playing video games. The results show that our mutual information scores are predictive of the ground-truth task completion metrics in a variety of domains, with an average Spearman's rank correlation of 0.43. In addition to offline evaluation of existing interfaces, we use our unsupervised objective to learn an interface from scratch: we randomly initialize the interface, have the user attempt to perform their desired tasks using the interface, measure the mutual information score, and update the interface to maximize mutual information through reinforcement learning. We evaluate our method through a user study with 12 participants who perform a 2D cursor control task using a perturbed mouse, and an experiment with one user playing the Lunar Lander game using hand gestures. The results show that we can learn an interface from scratch, without any user supervision or prior knowledge of tasks, in under 30 minutes.
Planning with Diffusion for Flexible Behavior Synthesis
May 20, 2022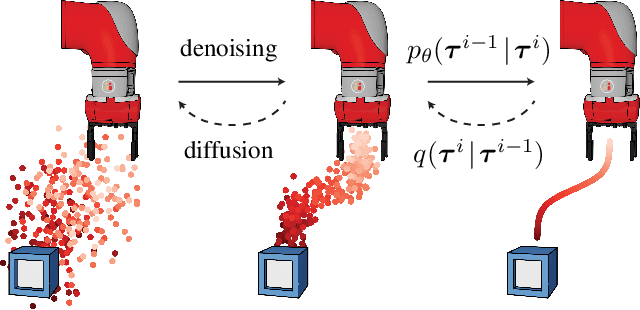
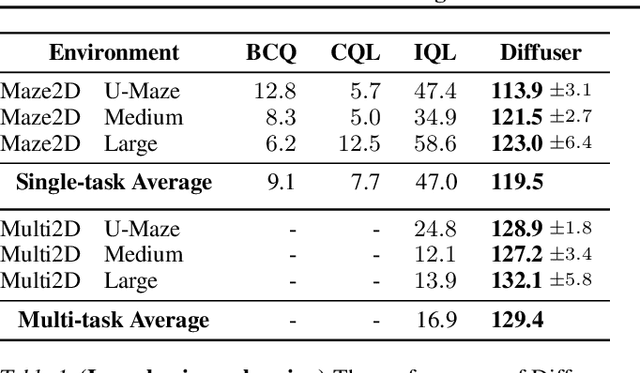
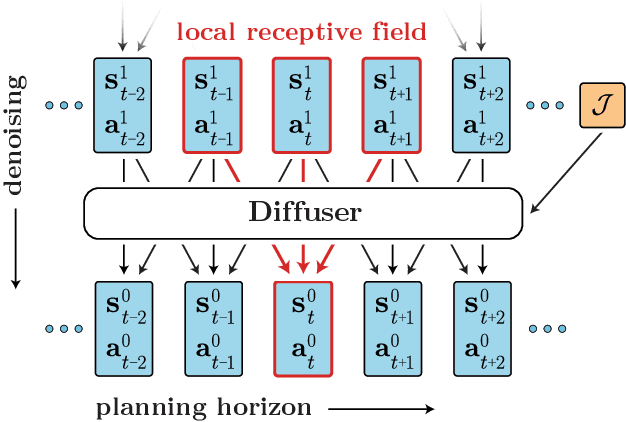
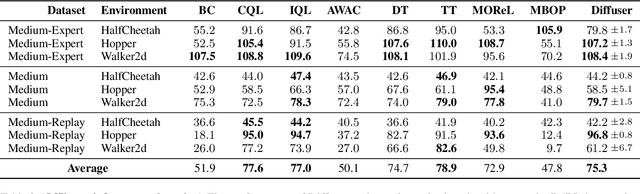
Model-based reinforcement learning methods often use learning only for the purpose of estimating an approximate dynamics model, offloading the rest of the decision-making work to classical trajectory optimizers. While conceptually simple, this combination has a number of empirical shortcomings, suggesting that learned models may not be well-suited to standard trajectory optimization. In this paper, we consider what it would look like to fold as much of the trajectory optimization pipeline as possible into the modeling problem, such that sampling from the model and planning with it become nearly identical. The core of our technical approach lies in a diffusion probabilistic model that plans by iteratively denoising trajectories. We show how classifier-guided sampling and image inpainting can be reinterpreted as coherent planning strategies, explore the unusual and useful properties of diffusion-based planning methods, and demonstrate the effectiveness of our framework in control settings that emphasize long-horizon decision-making and test-time flexibility.
Planning to Practice: Efficient Online Fine-Tuning by Composing Goals in Latent Space
May 17, 2022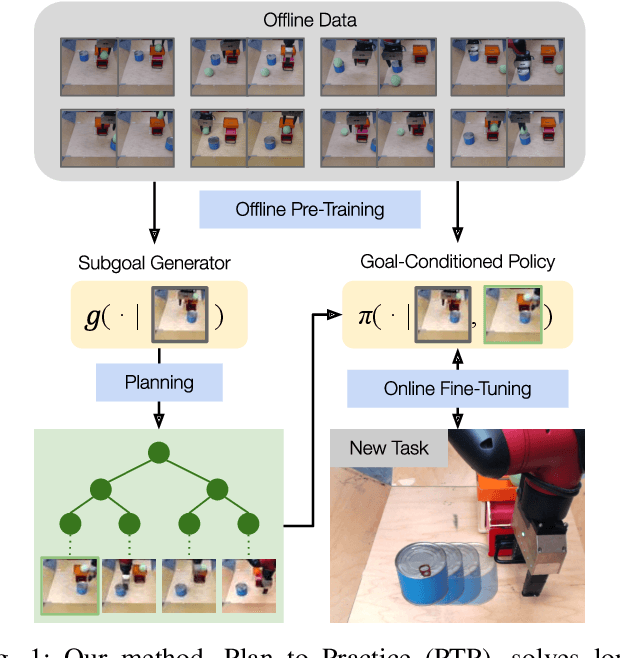
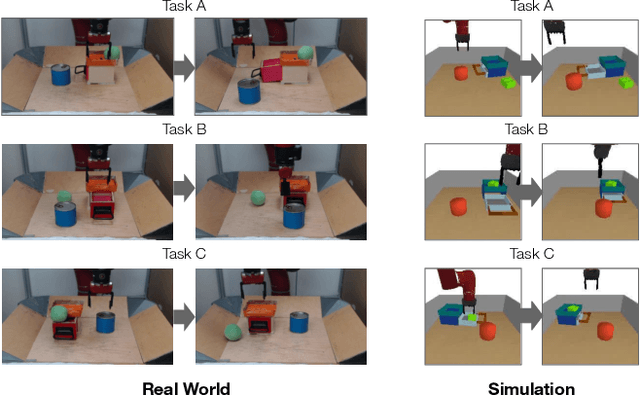
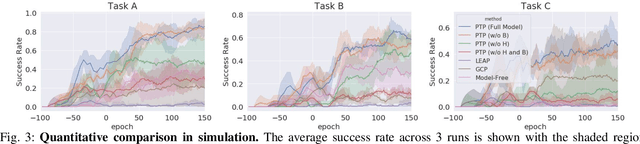

General-purpose robots require diverse repertoires of behaviors to complete challenging tasks in real-world unstructured environments. To address this issue, goal-conditioned reinforcement learning aims to acquire policies that can reach configurable goals for a wide range of tasks on command. However, such goal-conditioned policies are notoriously difficult and time-consuming to train from scratch. In this paper, we propose Planning to Practice (PTP), a method that makes it practical to train goal-conditioned policies for long-horizon tasks that require multiple distinct types of interactions to solve. Our approach is based on two key ideas. First, we decompose the goal-reaching problem hierarchically, with a high-level planner that sets intermediate subgoals using conditional subgoal generators in the latent space for a low-level model-free policy. Second, we propose a hybrid approach which first pre-trains both the conditional subgoal generator and the policy on previously collected data through offline reinforcement learning, and then fine-tunes the policy via online exploration. This fine-tuning process is itself facilitated by the planned subgoals, which breaks down the original target task into short-horizon goal-reaching tasks that are significantly easier to learn. We conduct experiments in both the simulation and real world, in which the policy is pre-trained on demonstrations of short primitive behaviors and fine-tuned for temporally extended tasks that are unseen in the offline data. Our experimental results show that PTP can generate feasible sequences of subgoals that enable the policy to efficiently solve the target tasks.
ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
May 05, 2022
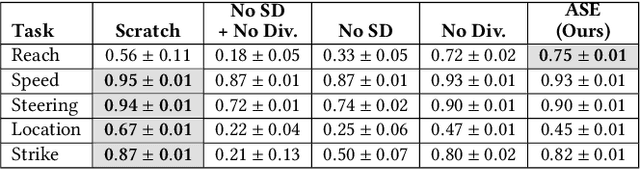
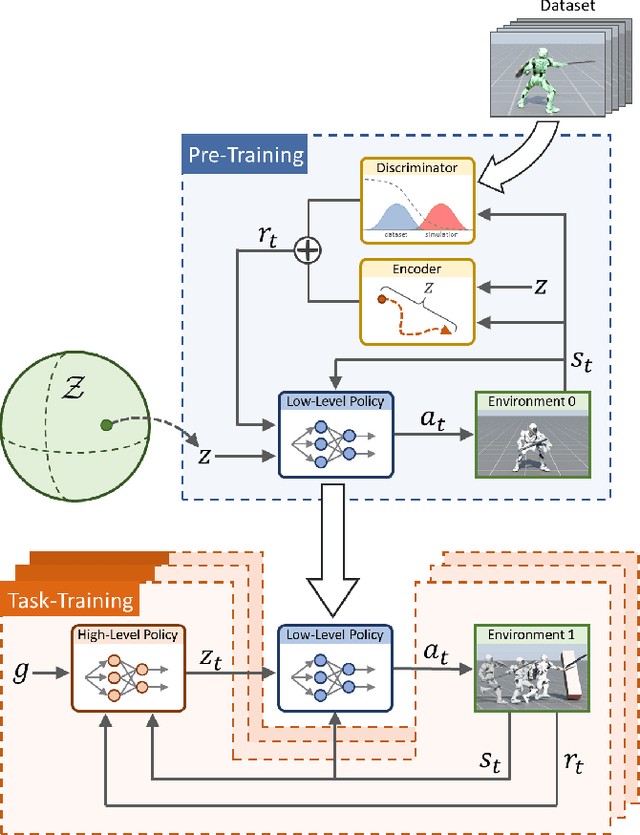
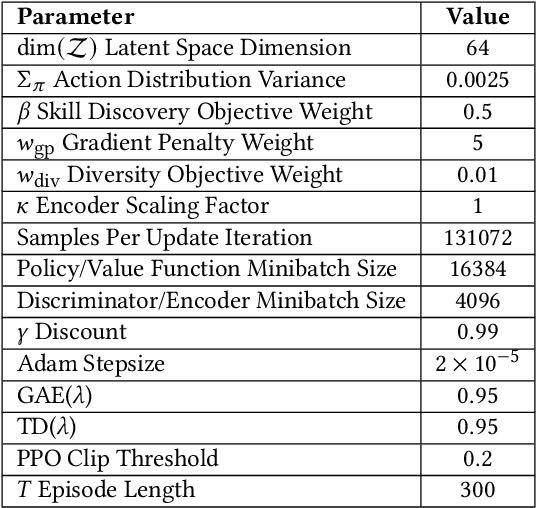
The incredible feats of athleticism demonstrated by humans are made possible in part by a vast repertoire of general-purpose motor skills, acquired through years of practice and experience. These skills not only enable humans to perform complex tasks, but also provide powerful priors for guiding their behaviors when learning new tasks. This is in stark contrast to what is common practice in physics-based character animation, where control policies are most typically trained from scratch for each task. In this work, we present a large-scale data-driven framework for learning versatile and reusable skill embeddings for physically simulated characters. Our approach combines techniques from adversarial imitation learning and unsupervised reinforcement learning to develop skill embeddings that produce life-like behaviors, while also providing an easy to control representation for use on new downstream tasks. Our models can be trained using large datasets of unstructured motion clips, without requiring any task-specific annotation or segmentation of the motion data. By leveraging a massively parallel GPU-based simulator, we are able to train skill embeddings using over a decade of simulated experiences, enabling our model to learn a rich and versatile repertoire of skills. We show that a single pre-trained model can be effectively applied to perform a diverse set of new tasks. Our system also allows users to specify tasks through simple reward functions, and the skill embedding then enables the character to automatically synthesize complex and naturalistic strategies in order to achieve the task objectives.
Control-Aware Prediction Objectives for Autonomous Driving
Apr 28, 2022
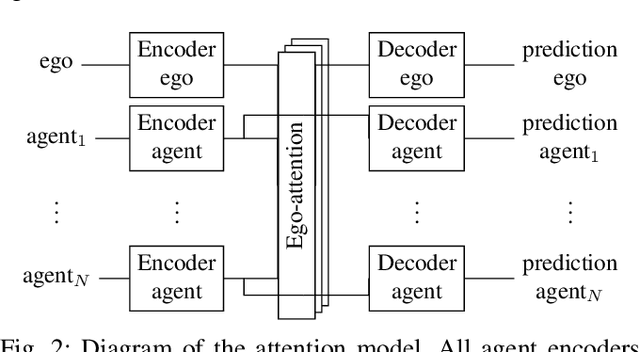
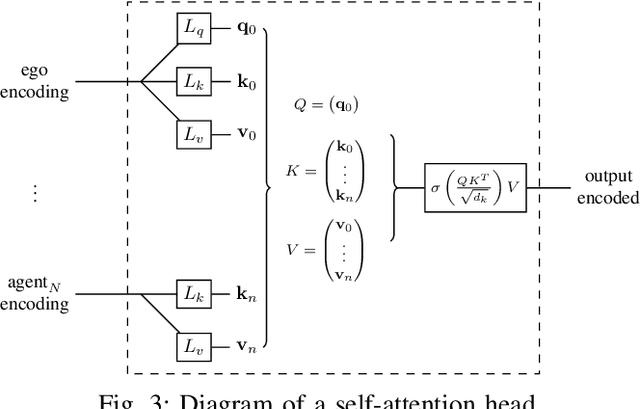

Autonomous vehicle software is typically structured as a modular pipeline of individual components (e.g., perception, prediction, and planning) to help separate concerns into interpretable sub-tasks. Even when end-to-end training is possible, each module has its own set of objectives used for safety assurance, sample efficiency, regularization, or interpretability. However, intermediate objectives do not always align with overall system performance. For example, optimizing the likelihood of a trajectory prediction module might focus more on easy-to-predict agents than safety-critical or rare behaviors (e.g., jaywalking). In this paper, we present control-aware prediction objectives (CAPOs), to evaluate the downstream effect of predictions on control without requiring the planner be differentiable. We propose two types of importance weights that weight the predictive likelihood: one using an attention model between agents, and another based on control variation when exchanging predicted trajectories for ground truth trajectories. Experimentally, we show our objectives improve overall system performance in suburban driving scenarios using the CARLA simulator.
Bisimulation Makes Analogies in Goal-Conditioned Reinforcement Learning
Apr 28, 2022
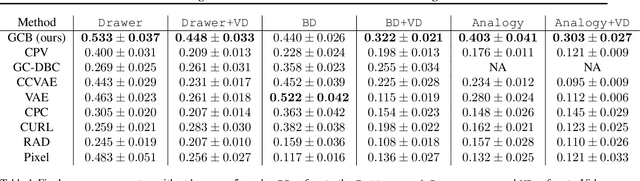


Building generalizable goal-conditioned agents from rich observations is a key to reinforcement learning (RL) solving real world problems. Traditionally in goal-conditioned RL, an agent is provided with the exact goal they intend to reach. However, it is often not realistic to know the configuration of the goal before performing a task. A more scalable framework would allow us to provide the agent with an example of an analogous task, and have the agent then infer what the goal should be for its current state. We propose a new form of state abstraction called goal-conditioned bisimulation that captures functional equivariance, allowing for the reuse of skills to achieve new goals. We learn this representation using a metric form of this abstraction, and show its ability to generalize to new goals in simulation manipulation tasks. Further, we prove that this learned representation is sufficient not only for goal conditioned tasks, but is amenable to any downstream task described by a state-only reward function. Videos can be found at https://sites.google.com/view/gc-bisimulation.
Context-Aware Language Modeling for Goal-Oriented Dialogue Systems
Apr 22, 2022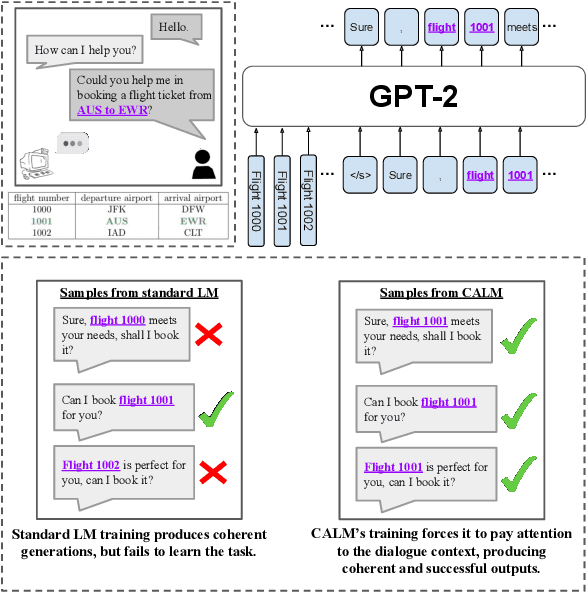
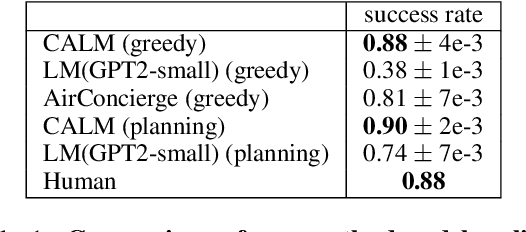


Goal-oriented dialogue systems face a trade-off between fluent language generation and task-specific control. While supervised learning with large language models is capable of producing realistic text, how to steer such responses towards completing a specific task without sacrificing language quality remains an open question. In this work, we formulate goal-oriented dialogue as a partially observed Markov decision process, interpreting the language model as a representation of both the dynamics and the policy. This view allows us to extend techniques from learning-based control, such as task relabeling, to derive a simple and effective method to finetune language models in a goal-aware way, leading to significantly improved task performance. We additionally introduce a number of training strategies that serve to better focus the model on the task at hand. We evaluate our method, Context-Aware Language Models (CALM), on a practical flight-booking task using AirDialogue. Empirically, CALM outperforms the state-of-the-art method by 7% in terms of task success, matching human-level task performance.
INFOrmation Prioritization through EmPOWERment in Visual Model-Based RL
Apr 18, 2022
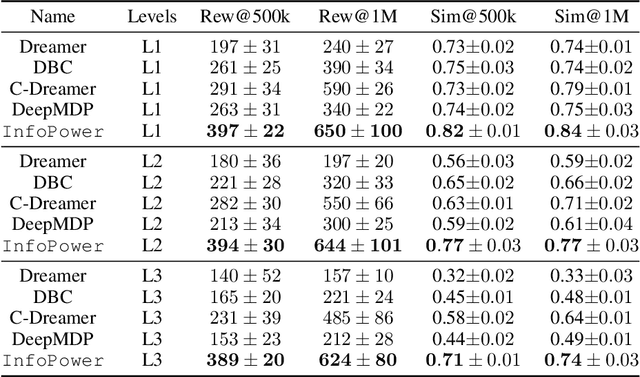
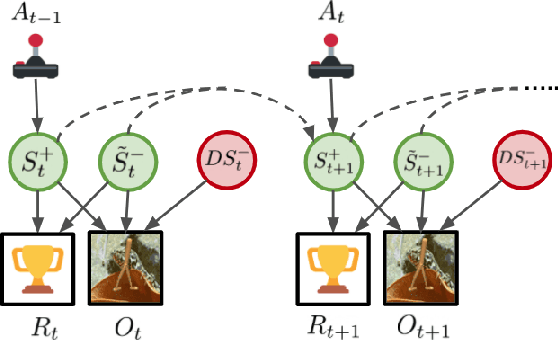
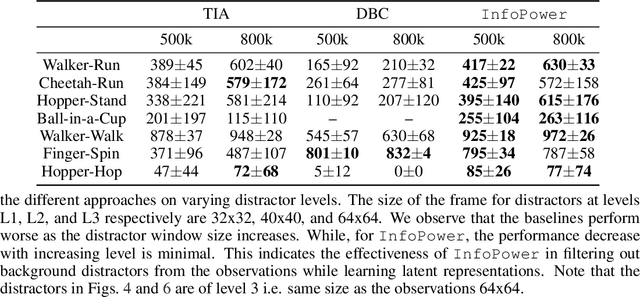
Model-based reinforcement learning (RL) algorithms designed for handling complex visual observations typically learn some sort of latent state representation, either explicitly or implicitly. Standard methods of this sort do not distinguish between functionally relevant aspects of the state and irrelevant distractors, instead aiming to represent all available information equally. We propose a modified objective for model-based RL that, in combination with mutual information maximization, allows us to learn representations and dynamics for visual model-based RL without reconstruction in a way that explicitly prioritizes functionally relevant factors. The key principle behind our design is to integrate a term inspired by variational empowerment into a state-space model based on mutual information. This term prioritizes information that is correlated with action, thus ensuring that functionally relevant factors are captured first. Furthermore, the same empowerment term also promotes faster exploration during the RL process, especially for sparse-reward tasks where the reward signal is insufficient to drive exploration in the early stages of learning. We evaluate the approach on a suite of vision-based robot control tasks with natural video backgrounds, and show that the proposed prioritized information objective outperforms state-of-the-art model based RL approaches with higher sample efficiency and episodic returns. https://sites.google.com/view/information-empowerment
CHAI: A CHatbot AI for Task-Oriented Dialogue with Offline Reinforcement Learning
Apr 18, 2022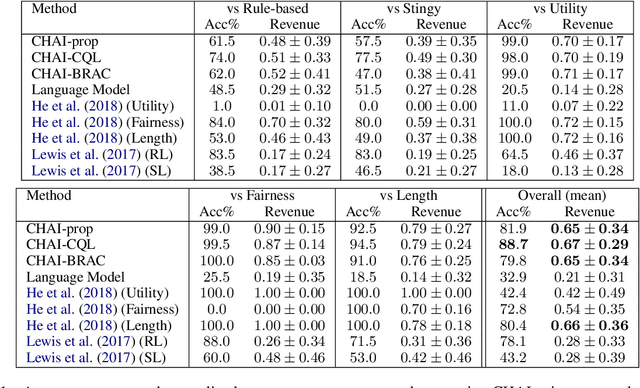


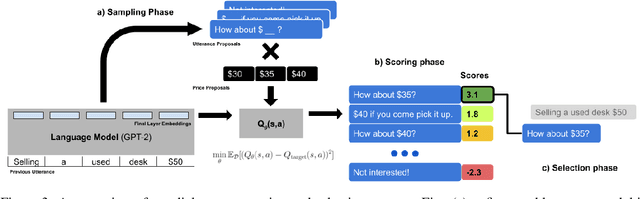
Conventionally, generation of natural language for dialogue agents may be viewed as a statistical learning problem: determine the patterns in human-provided data and generate appropriate responses with similar statistical properties. However, dialogue can also be regarded as a goal directed process, where speakers attempt to accomplish a specific task. Reinforcement learning (RL) algorithms are designed specifically for solving such goal-directed problems, but the most direct way to apply RL -- through trial-and-error learning in human conversations, -- is costly. In this paper, we study how offline reinforcement learning can instead be used to train dialogue agents entirely using static datasets collected from human speakers. Our experiments show that recently developed offline RL methods can be combined with language models to yield realistic dialogue agents that better accomplish task goals.
When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning?
Apr 12, 2022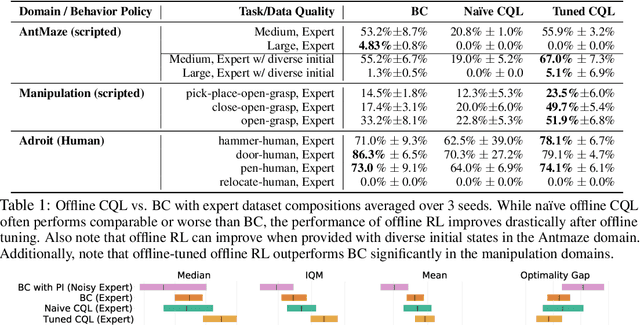
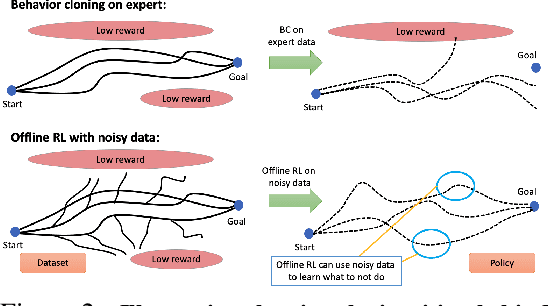
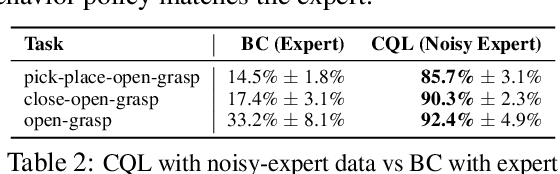
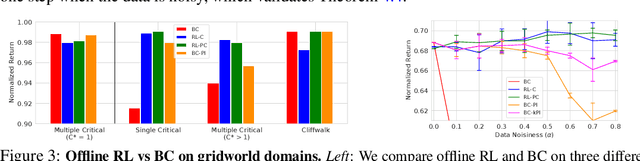
Offline reinforcement learning (RL) algorithms can acquire effective policies by utilizing previously collected experience, without any online interaction. It is widely understood that offline RL is able to extract good policies even from highly suboptimal data, a scenario where imitation learning finds suboptimal solutions that do not improve over the demonstrator that generated the dataset. However, another common use case for practitioners is to learn from data that resembles demonstrations. In this case, one can choose to apply offline RL, but can also use behavioral cloning (BC) algorithms, which mimic a subset of the dataset via supervised learning. Therefore, it seems natural to ask: when can an offline RL method outperform BC with an equal amount of expert data, even when BC is a natural choice? To answer this question, we characterize the properties of environments that allow offline RL methods to perform better than BC methods, even when only provided with expert data. Additionally, we show that policies trained on sufficiently noisy suboptimal data can attain better performance than even BC algorithms with expert data, especially on long-horizon problems. We validate our theoretical results via extensive experiments on both diagnostic and high-dimensional domains including robotic manipulation, maze navigation, and Atari games, with a variety of data distributions. We observe that, under specific but common conditions such as sparse rewards or noisy data sources, modern offline RL methods can significantly outperform BC.