 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Safety Margin Estimation for Safe Real-Time Replanning under Time-Varying Disturbance
Oct 07, 2021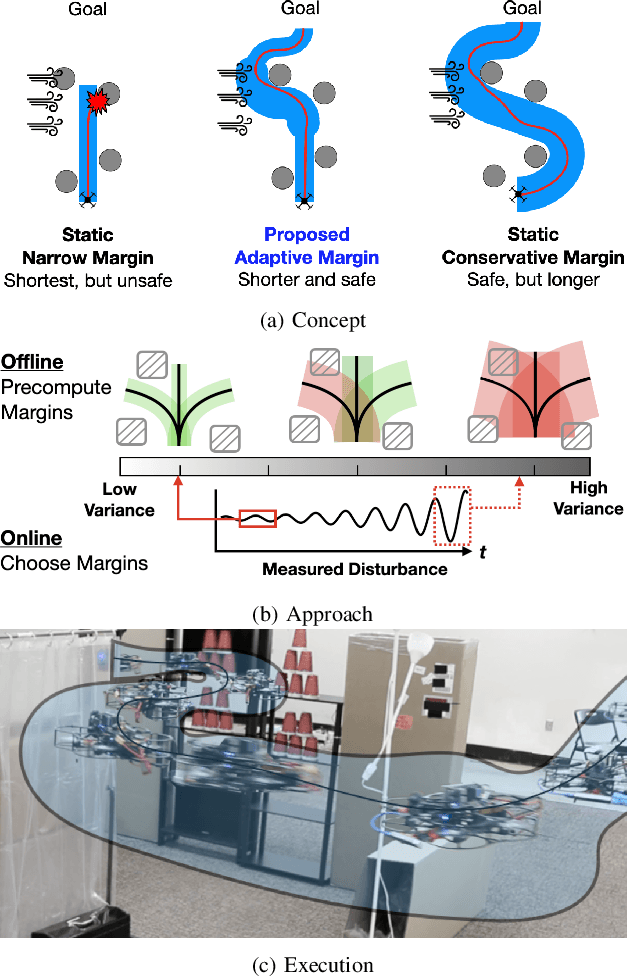
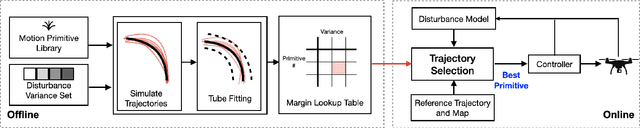
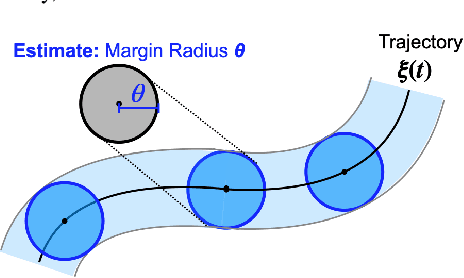
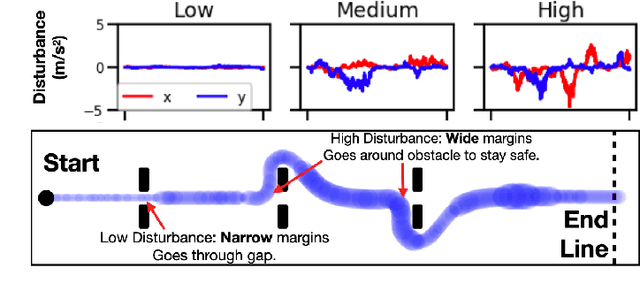
Safe navigation in real-time is challenging because engineers need to work with uncertain vehicle dynamics, variable external disturbances, and imperfect controllers. A common safety strategy is to inflate obstacles by hand-defined margins. However, arbitrary static margins often fail in more dynamic scenarios, and using worst-case assumptions is overly conservative for most settings where disturbances over time. In this work, we propose a middle ground: safety margins that adapt on-the-fly. In an offline phase, we use Monte Carlo simulations to pre-compute a library of safety margins for multiple levels of disturbance uncertainties. Then, at runtime, our system estimates the current disturbance level to query the associated safety margins that best trades off safety and performance. We validate our approach with extensive simulated and real-world flight tests. We show that our adaptive method significantly outperforms static margins, allowing the vehicle to operate up to 1.5 times faster than worst-case static margins while maintaining safety. Video: https://youtu.be/SHzKHSUjdUU
Predicting Like A Pilot: Dataset and Method to Predict Socially-Aware Aircraft Trajectories in Non-Towered Terminal Airspace
Sep 30, 2021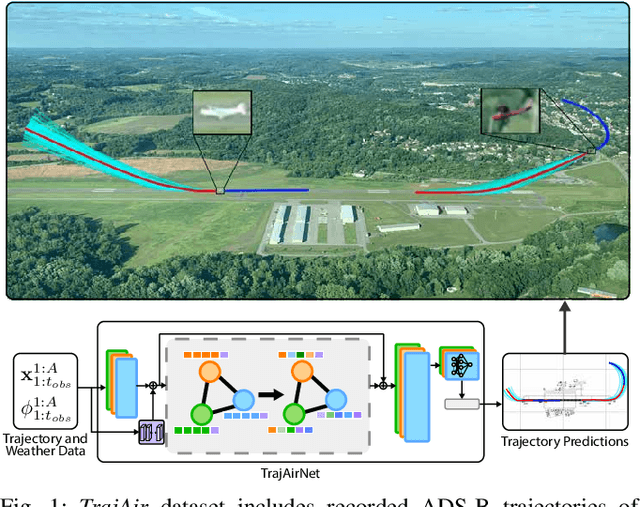
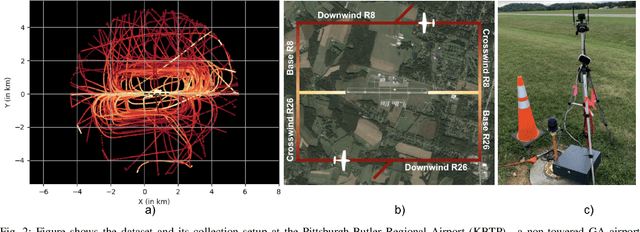
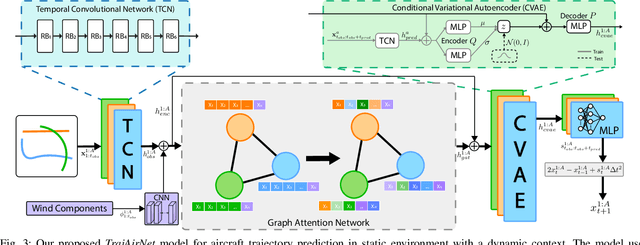

Pilots operating aircraft in un-towered airspace rely on their situational awareness and prior knowledge to predict the future trajectories of other agents. These predictions are conditioned on the past trajectories of other agents, agent-agent social interactions and environmental context such as airport location and weather. This paper provides a dataset, $\textit{TrajAir}$, that captures this behaviour in a non-towered terminal airspace around a regional airport. We also present a baseline socially-aware trajectory prediction algorithm, $\textit{TrajAirNet}$, that uses the dataset to predict the trajectories of all agents. The dataset is collected for 111 days over 8 months and contains ADS-B transponder data along with the corresponding METAR weather data. The data is processed to be used as a benchmark with other publicly available social navigation datasets. To the best of authors' knowledge, this is the first 3D social aerial navigation dataset thus introducing social navigation for autonomous aviation. $\textit{TrajAirNet}$ combines state-of-the-art modules in social navigation to provide predictions in a static environment with a dynamic context. Both the $\textit{TrajAir}$ dataset and $\textit{TrajAirNet}$ prediction algorithm are open-source. The dataset, codebase, and video are available at https://theairlab.org/trajair/, https://github.com/castacks/trajairnet, and https://youtu.be/elAQXrxB2gw respectively.
Targetless Extrinsic Calibration of Stereo Cameras, Thermal Cameras, and Laser Sensors in the Wild
Sep 28, 2021
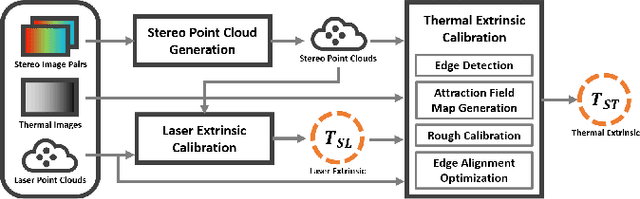


The fusion of multi-modal sensors has become increasingly popular in autonomous driving and intelligent robots since it can provide richer information than any single sensor, enhance reliability in complex environments. Multi-sensor extrinsic calibration is one of the key factors of sensor fusion. However, such calibration is difficult due to the variety of sensor modalities and the requirement of calibration targets and human labor. In this paper, we demonstrate a new targetless cross-modal calibration framework by focusing on the extrinsic transformations among stereo cameras, thermal cameras, and laser sensors. Specifically, the calibration between stereo and laser is conducted in 3D space by minimizing the registration error, while the thermal extrinsic to the other two sensors is estimated by optimizing the alignment of the edge features. Our method requires no dedicated targets and performs the multi-sensor calibration in a single shot without human interaction. Experimental results show that the calibration framework is accurate and applicable in general scenes.
Toward Efficient and Robust Multiple Camera Visual-inertial Odometry
Sep 24, 2021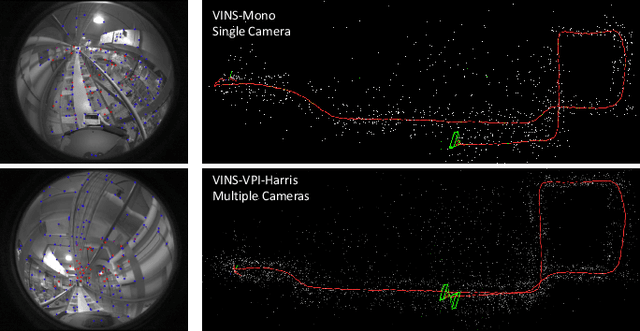
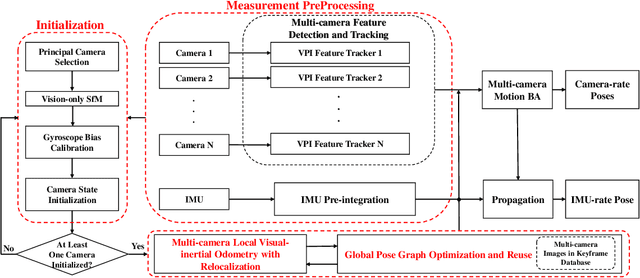
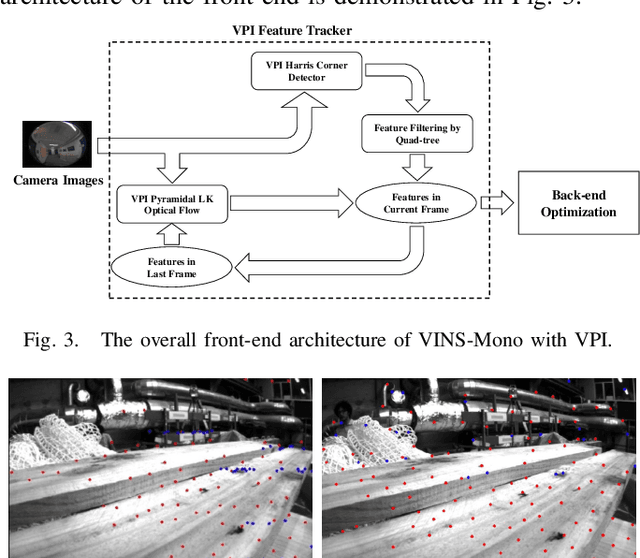
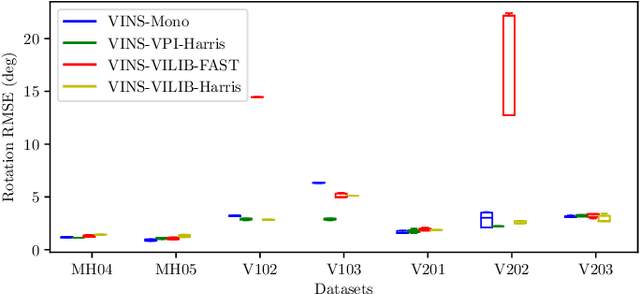
Efficiency and robustness are the essential criteria for the visual-inertial odometry (VIO) system. To process massive visual data, the high cost on CPU resources and computation latency limits VIO's possibility in integration with other applications. Recently, the powerful embedded GPUs have great potentials to improve the front-end image processing capability. Meanwhile, multi-camera systems can increase the visual constraints for back-end optimization. Inspired by these insights, we incorporate the GPU-enhanced algorithms in the field of VIO and thus propose a new front-end with NVIDIA Vision Programming Interface (VPI). This new front-end then enables multi-camera VIO feature association and provides more stable back-end pose optimization. Experiments with our new front-end on monocular datasets show the CPU resource occupation rate and computational latency are reduced by 40.4% and 50.6% without losing accuracy compared with the original VIO. The multi-camera system shows a higher VIO initialization success rate and better robustness overall state estimation.
AirDOS: Dynamic SLAM benefits from Articulated Objects
Sep 21, 2021
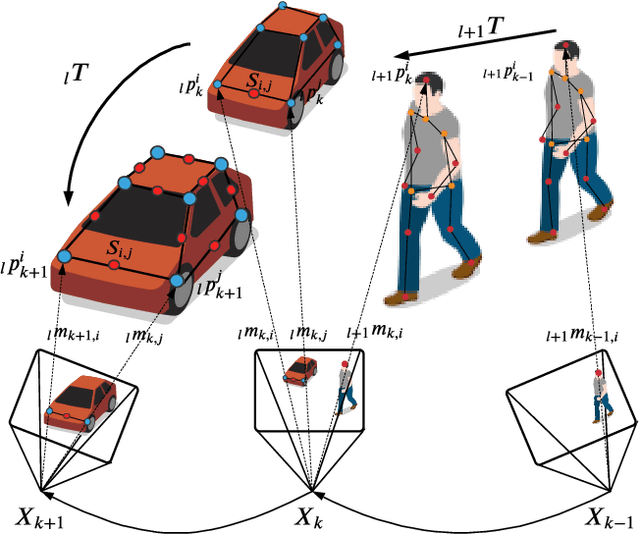
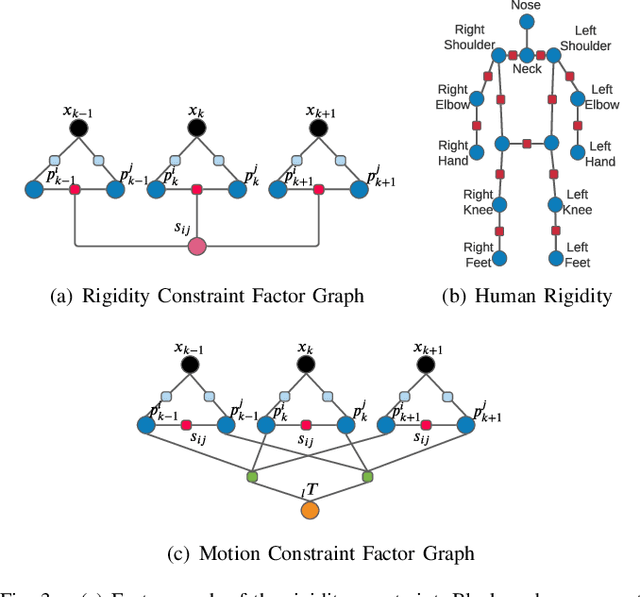
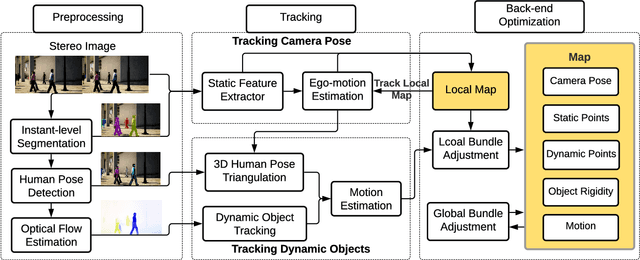
Dynamic Object-aware SLAM (DOS) exploits object-level information to enable robust motion estimation in dynamic environments. It has attracted increasing attention with the recent success of learning-based models. Existing methods mainly focus on identifying and excluding dynamic objects from the optimization. In this paper, we show that feature-based visual SLAM systems can also benefit from the presence of dynamic articulated objects by taking advantage of two observations: (1) The 3D structure of an articulated object remains consistent over time; (2) The points on the same object follow the same motion. In particular, we present AirDOS, a dynamic object-aware system that introduces rigidity and motion constraints to model articulated objects. By jointly optimizing the camera pose, object motion, and the object 3D structure, we can rectify the camera pose estimation, preventing tracking loss, and generate 4D spatio-temporal maps for both dynamic objects and static scenes. Experiments show that our algorithm improves the robustness of visual SLAM algorithms in challenging crowded urban environments. To the best of our knowledge, AirDOS is the first dynamic object-aware SLAM system demonstrating that camera pose estimation can be improved by incorporating dynamic articulated objects.
AirLoop: Lifelong Loop Closure Detection
Sep 18, 2021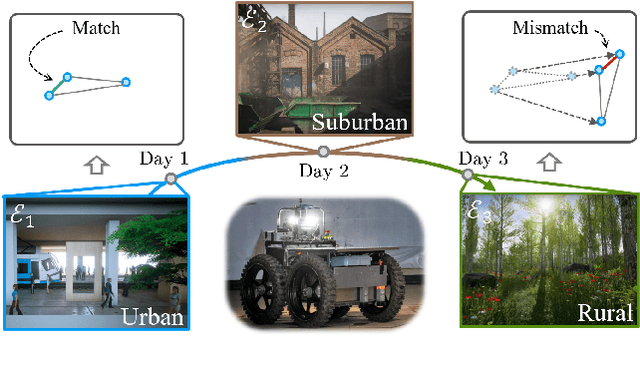
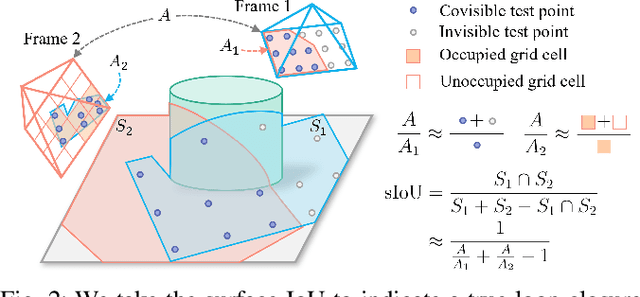

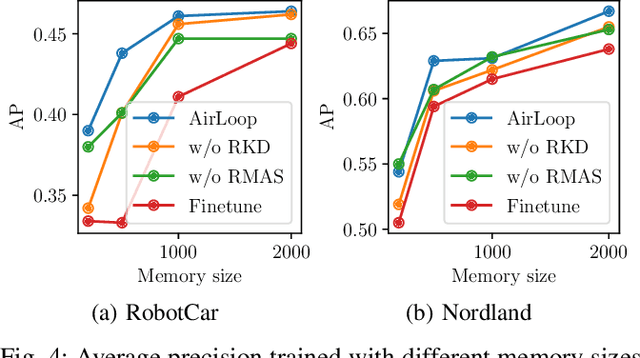
Loop closure detection is an important building block that ensures the accuracy and robustness of simultaneous localization and mapping (SLAM) systems. Due to their generalization ability, CNN-based approaches have received increasing attention. Although they normally benefit from training on datasets that are diverse and reflective of the environments, new environments often emerge after the model is deployed. It is therefore desirable to incorporate the data newly collected during operation for incremental learning. Nevertheless, simply finetuning the model on new data is infeasible since it may cause the model's performance on previously learned data to degrade over time, which is also known as the problem of catastrophic forgetting. In this paper, we present AirLoop, a method that leverages techniques from lifelong learning to minimize forgetting when training loop closure detection models incrementally. We experimentally demonstrate the effectiveness of AirLoop on TartanAir, Nordland, and RobotCar datasets. To the best of our knowledge, AirLoop is one of the first works to achieve lifelong learning of deep loop closure detectors.
Unified Representation of Geometric Primitives for Graph-SLAM Optimization Using Decomposed Quadrics
Aug 20, 2021
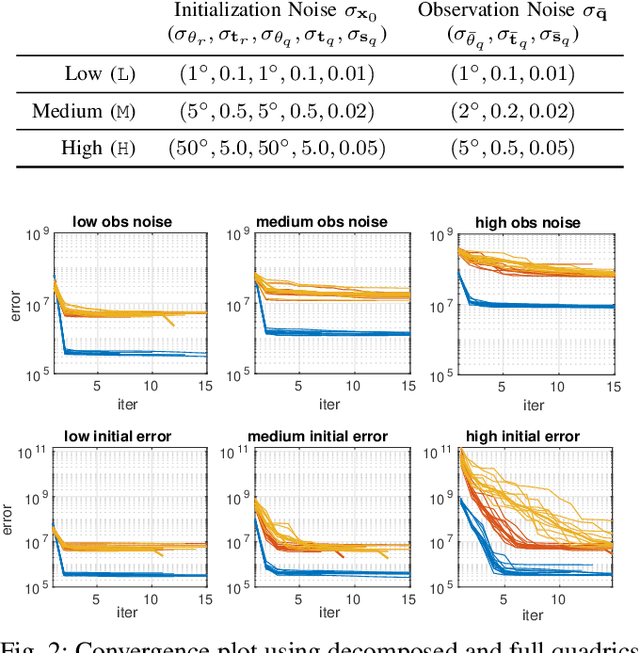

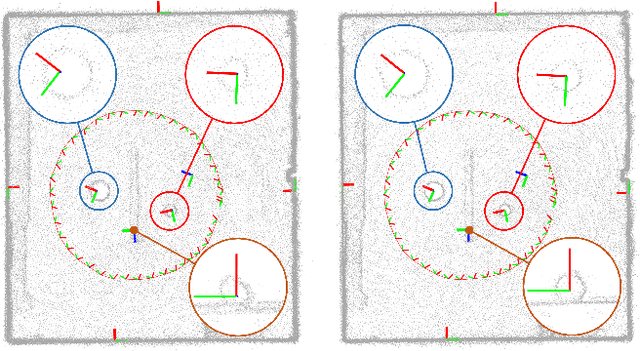
In Simultaneous Localization And Mapping (SLAM) problems, high-level landmarks have the potential to build compact and informative maps compared to traditional point-based landmarks. This work is focused on the parameterization problem of high-level geometric primitives that are most frequently used, including points, lines, planes, ellipsoids, cylinders, and cones. We first present a unified representation of those geometric primitives using \emph{quadrics} which yields a consistent and concise formulation. Then we further study a decomposed model of quadrics that discloses the symmetric and degenerated nature of quadrics. Based on the decomposition, we develop physically meaningful quadrics factors in the settings of the graph-SLAM problem. Finally, in simulation experiments, it is shown that the decomposed formulation has better efficiency and robustness to observation noises than baseline parameterizations. And in real-world experiments, the proposed back-end framework is demonstrated to be capable of building compact and regularized maps.
3D-SiamRPN: An End-to-End Learning Method for Real-Time 3D Single Object Tracking Using Raw Point Cloud
Aug 12, 2021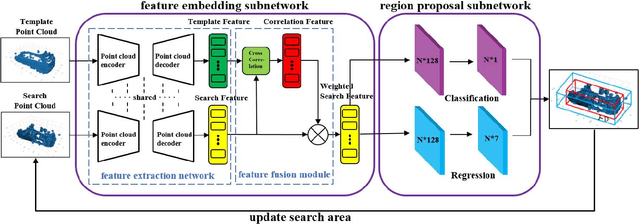


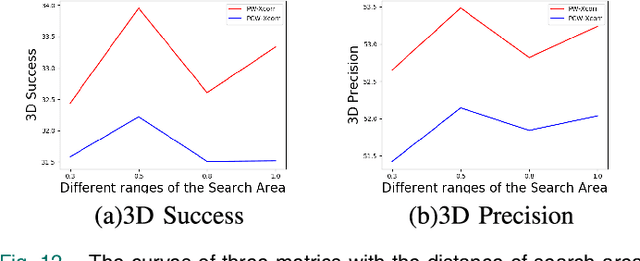
3D single object tracking is a key issue for autonomous following robot, where the robot should robustly track and accurately localize the target for efficient following. In this paper, we propose a 3D tracking method called 3D-SiamRPN Network to track a single target object by using raw 3D point cloud data. The proposed network consists of two subnetworks. The first subnetwork is feature embedding subnetwork which is used for point cloud feature extraction and fusion. In this subnetwork, we first use PointNet++ to extract features of point cloud from template and search branches. Then, to fuse the information of features in the two branches and obtain their similarity, we propose two cross correlation modules, named Pointcloud-wise and Point-wise respectively. The second subnetwork is region proposal network(RPN), which is used to get the final 3D bounding box of the target object based on the fusion feature from cross correlation modules. In this subnetwork, we utilize the regression and classification branches of a region proposal subnetwork to obtain proposals and scores, thus get the final 3D bounding box of the target object. Experimental results on KITTI dataset show that our method has a competitive performance in both Success and Precision compared to the state-of-the-art methods, and could run in real-time at 20.8 FPS. Additionally, experimental results on H3D dataset demonstrate that our method also has good generalization ability and could achieve good tracking performance in a new scene without re-training.
3D Human Reconstruction in the Wild with Collaborative Aerial Cameras
Aug 09, 2021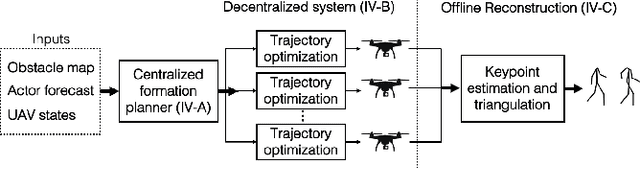
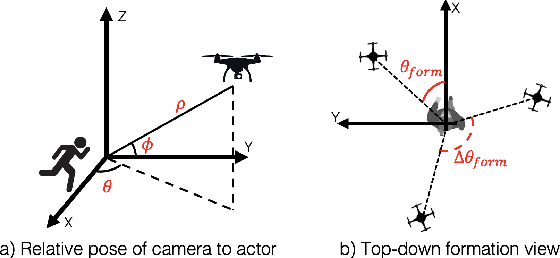
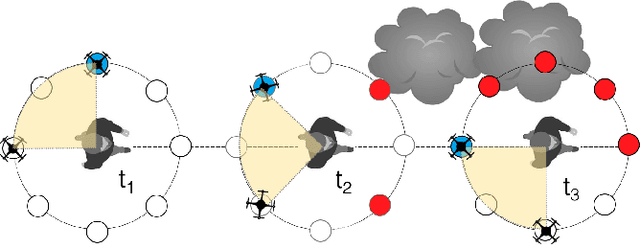
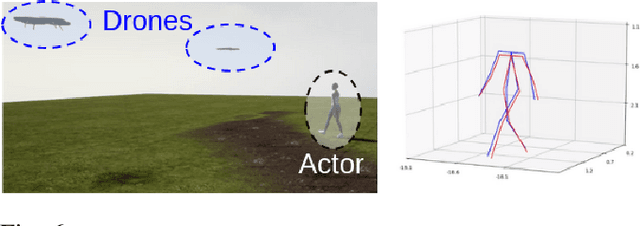
Aerial vehicles are revolutionizing applications that require capturing the 3D structure of dynamic targets in the wild, such as sports, medicine, and entertainment. The core challenges in developing a motion-capture system that operates in outdoors environments are: (1) 3D inference requires multiple simultaneous viewpoints of the target, (2) occlusion caused by obstacles is frequent when tracking moving targets, and (3) the camera and vehicle state estimation is noisy. We present a real-time aerial system for multi-camera control that can reconstruct human motions in natural environments without the use of special-purpose markers. We develop a multi-robot coordination scheme that maintains the optimal flight formation for target reconstruction quality amongst obstacles. We provide studies evaluating system performance in simulation, and validate real-world performance using two drones while a target performs activities such as jogging and playing soccer. Supplementary video: https://youtu.be/jxt91vx0cns
Carnegie Mellon Team Tartan: Mission-level Robustness with Rapidly Deployed Autonomous Aerial Vehicles in the MBZIRC 2020
Jul 03, 2021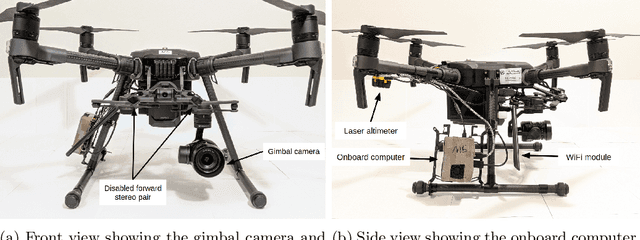

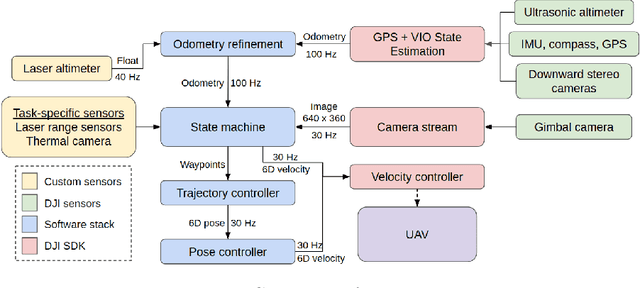
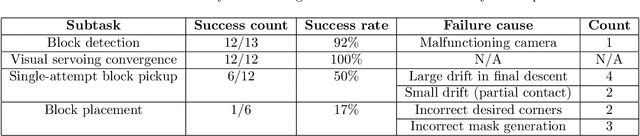
For robotics systems to be used in high risk, real-world situations, they have to be quickly deployable and robust to environmental changes, under-performing hardware, and mission subtask failures. Robots are often designed to consider a single sequence of mission events, with complex algorithms lowering individual subtask failure rates under some critical constraints. Our approach is to leverage common techniques in vision and control and encode robustness into mission structure through outcome monitoring and recovery strategies, aided by a system infrastructure that allows for quick mission deployments under tight time constraints and no central communication. We also detail lessons in rapid field robotics development and testing. Systems were developed and evaluated through real-robot experiments at an outdoor test site in Pittsburgh, Pennsylvania, USA, as well as in the 2020 Mohamed Bin Zayed International Robotics Challenge. All competition trials were completed in fully autonomous mode without RTK-GPS. Our system led to 4th place in Challenge 2 and 7th place in the Grand Challenge, and achievements like popping five balloons (Challenge 1), successfully picking and placing a block (Challenge 2), and dispensing the most water autonomously with a UAV of all teams onto an outdoor, real fire (Challenge 3).