 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
TaTa: A Multilingual Table-to-Text Dataset for African Languages
Oct 31, 2022



Existing data-to-text generation datasets are mostly limited to English. To address this lack of data, we create Table-to-Text in African languages (TaTa), the first large multilingual table-to-text dataset with a focus on African languages. We created TaTa by transcribing figures and accompanying text in bilingual reports by the Demographic and Health Surveys Program, followed by professional translation to make the dataset fully parallel. TaTa includes 8,700 examples in nine languages including four African languages (Hausa, Igbo, Swahili, and Yor\`ub\'a) and a zero-shot test language (Russian). We additionally release screenshots of the original figures for future research on multilingual multi-modal approaches. Through an in-depth human evaluation, we show that TaTa is challenging for current models and that less than half the outputs from an mT5-XXL-based model are understandable and attributable to the source data. We further demonstrate that existing metrics perform poorly for TaTa and introduce learned metrics that achieve a high correlation with human judgments. We release all data and annotations at https://github.com/google-research/url-nlp.
Language Models are Multilingual Chain-of-Thought Reasoners
Oct 06, 2022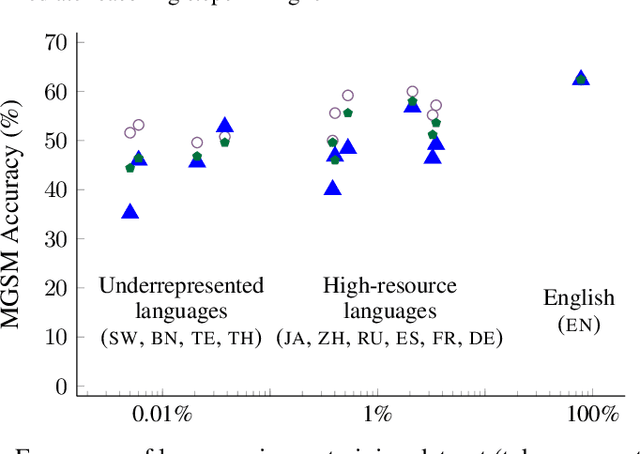


We evaluate the reasoning abilities of large language models in multilingual settings. We introduce the Multilingual Grade School Math (MGSM) benchmark, by manually translating 250 grade-school math problems from the GSM8K dataset (Cobbe et al., 2021) into ten typologically diverse languages. We find that the ability to solve MGSM problems via chain-of-thought prompting emerges with increasing model scale, and that models have strikingly strong multilingual reasoning abilities, even in underrepresented languages such as Bengali and Swahili. Finally, we show that the multilingual reasoning abilities of language models extend to other tasks such as commonsense reasoning and word-in-context semantic judgment. The MGSM benchmark is publicly available at https://github.com/google-research/url-nlp.
Square One Bias in NLP: Towards a Multi-Dimensional Exploration of the Research Manifold
Jun 20, 2022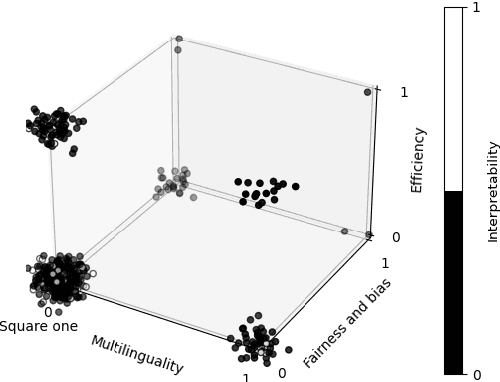
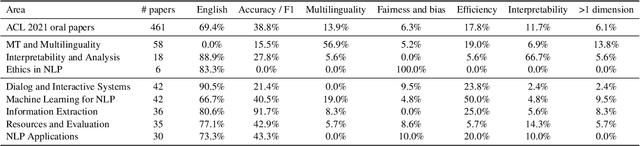
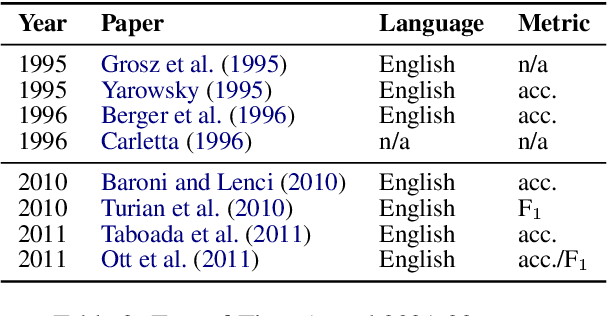

The prototypical NLP experiment trains a standard architecture on labeled English data and optimizes for accuracy, without accounting for other dimensions such as fairness, interpretability, or computational efficiency. We show through a manual classification of recent NLP research papers that this is indeed the case and refer to it as the square one experimental setup. We observe that NLP research often goes beyond the square one setup, e.g, focusing not only on accuracy, but also on fairness or interpretability, but typically only along a single dimension. Most work targeting multilinguality, for example, considers only accuracy; most work on fairness or interpretability considers only English; and so on. We show this through manual classification of recent NLP research papers and ACL Test-of-Time award recipients. Such one-dimensionality of most research means we are only exploring a fraction of the NLP research search space. We provide historical and recent examples of how the square one bias has led researchers to draw false conclusions or make unwise choices, point to promising yet unexplored directions on the research manifold, and make practical recommendations to enable more multi-dimensional research. We open-source the results of our annotations to enable further analysis at https://github.com/google-research/url-nlp
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022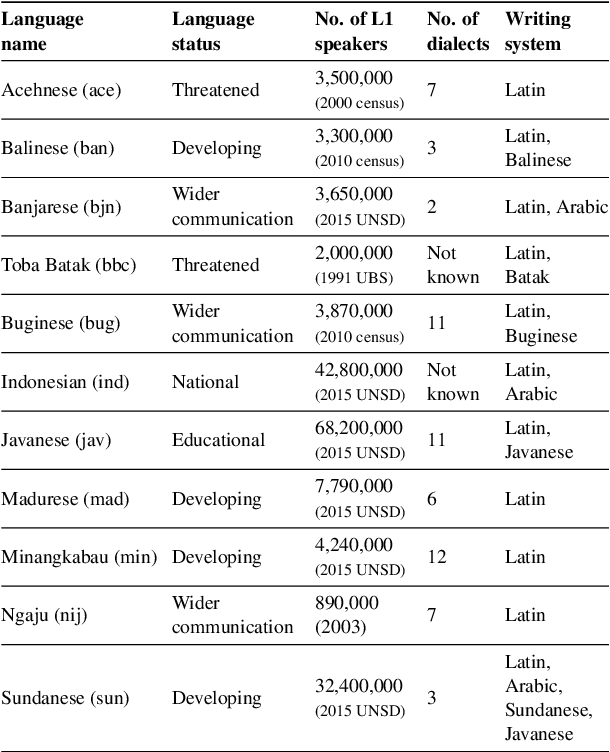
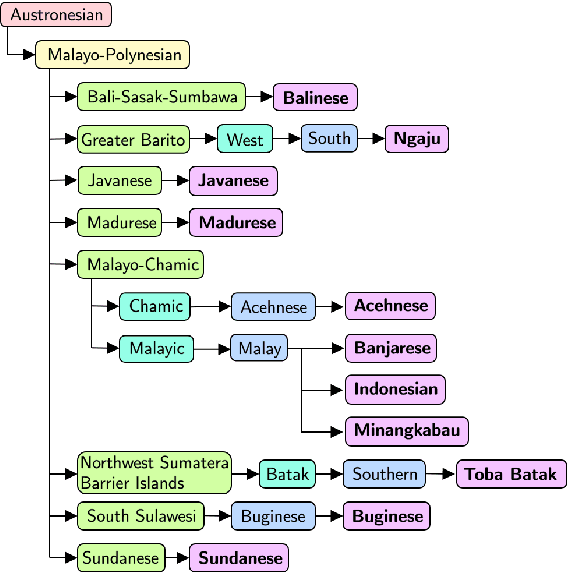
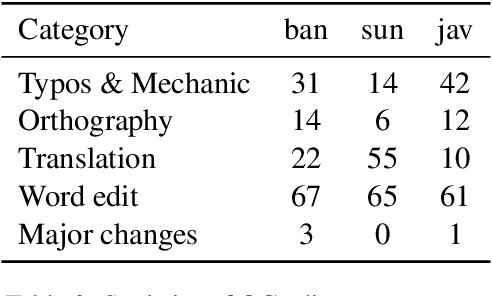
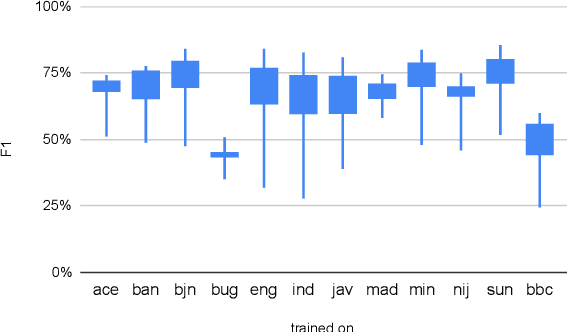
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
Evaluating Inclusivity, Equity, and Accessibility of NLP Technology: A Case Study for Indian Languages
May 25, 2022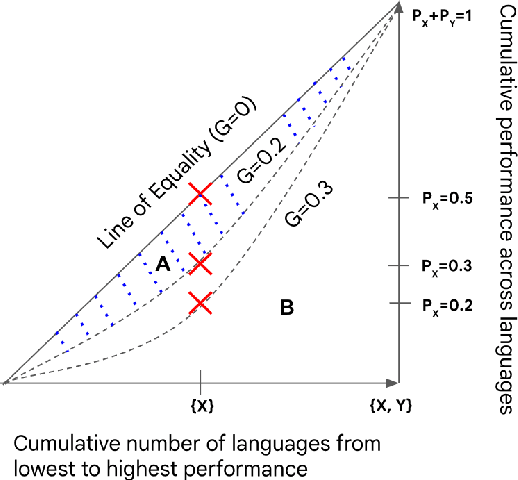

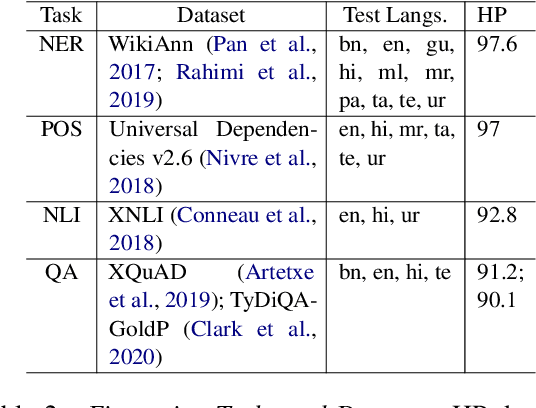
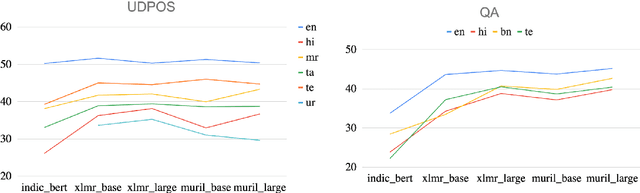
In order for NLP technology to be widely applicable and useful, it needs to be inclusive of users across the world's languages, equitable, i.e., not unduly biased towards any particular language, and accessible to users, particularly in low-resource settings where compute constraints are common. In this paper, we propose an evaluation paradigm that assesses NLP technologies across all three dimensions, hence quantifying the diversity of users they can serve. While inclusion and accessibility have received attention in recent literature, equity is currently unexplored. We propose to address this gap using the Gini coefficient, a well-established metric used for estimating societal wealth inequality. Using our paradigm, we highlight the distressed state of diversity of current technologies for Indian (IN) languages, motivated by their linguistic diversity and large, varied speaker population. To improve upon these metrics, we demonstrate the importance of region-specific choices in model building and dataset creation and also propose a novel approach to optimal resource allocation during fine-tuning. Finally, we discuss steps that must be taken to mitigate these biases and call upon the community to incorporate our evaluation paradigm when building linguistically diverse technologies.
Hyper-X: A Unified Hypernetwork for Multi-Task Multilingual Transfer
May 24, 2022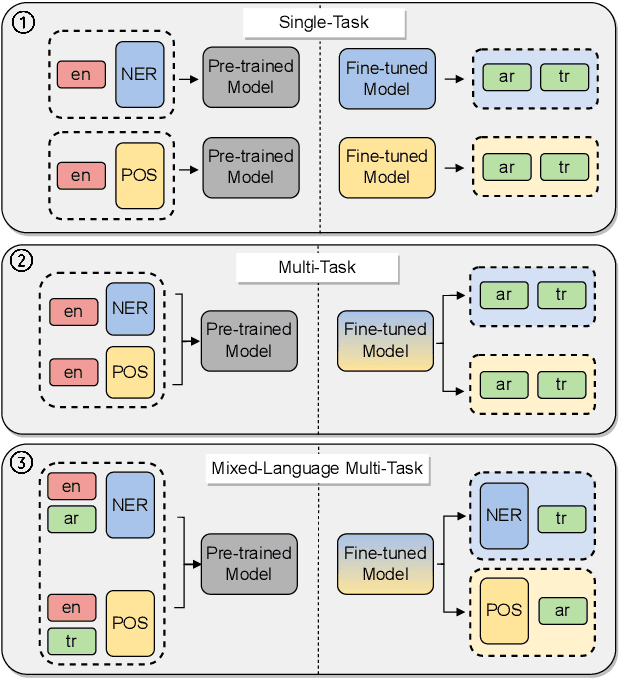

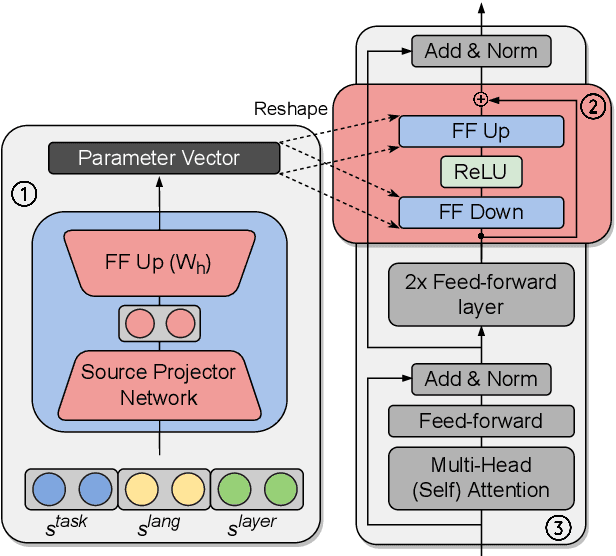
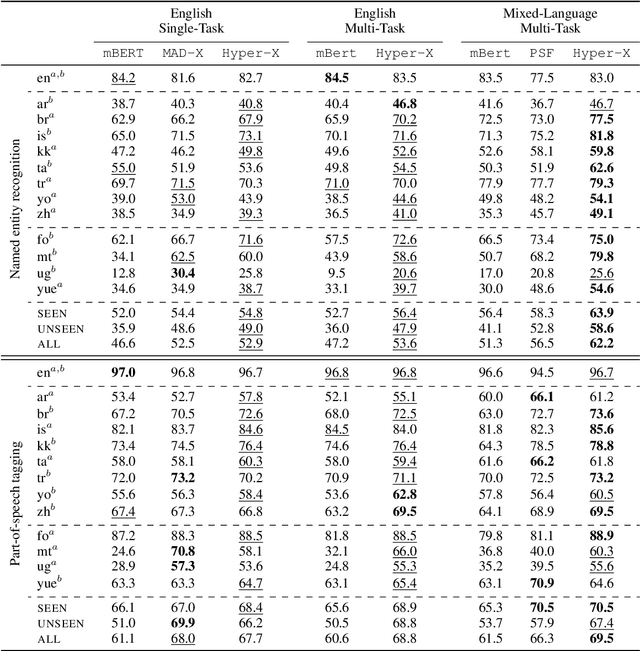
Massively multilingual models are promising for transfer learning across tasks and languages. However, existing methods are unable to fully leverage training data when it is available in different task-language combinations. To exploit such heterogeneous supervision we propose Hyper-X, a unified hypernetwork that generates weights for parameter-efficient adapter modules conditioned on both tasks and language embeddings. By learning to combine task and language-specific knowledge our model enables zero-shot transfer for unseen languages and task-language combinations. Our experiments on a diverse set of languages demonstrate that Hyper-X achieves the best gain when a mixture of multiple resources is available while performing on par with strong baselines in the standard scenario. Finally, Hyper-X consistently produces strong results in few-shot scenarios for new languages and tasks showing the effectiveness of our approach beyond zero-shot transfer.
XTREME-S: Evaluating Cross-lingual Speech Representations
Apr 13, 2022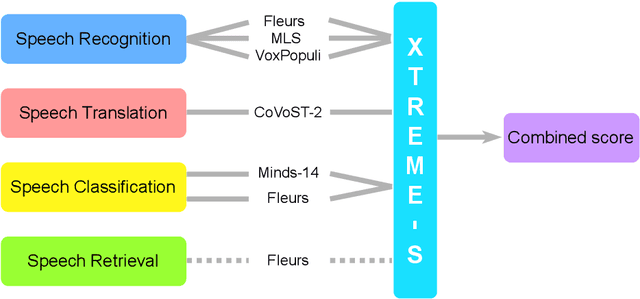
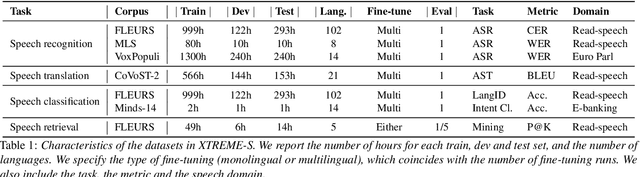
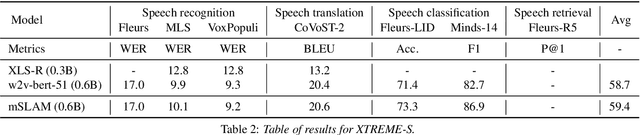
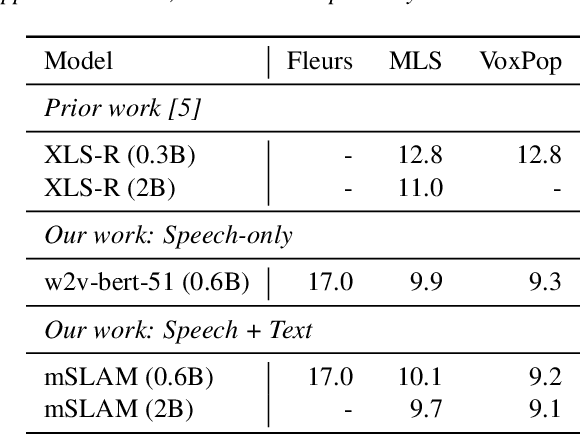
We introduce XTREME-S, a new benchmark to evaluate universal cross-lingual speech representations in many languages. XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval. Covering 102 languages from 10+ language families, 3 different domains and 4 task families, XTREME-S aims to simplify multilingual speech representation evaluation, as well as catalyze research in "universal" speech representation learning. This paper describes the new benchmark and establishes the first speech-only and speech-text baselines using XLS-R and mSLAM on all downstream tasks. We motivate the design choices and detail how to use the benchmark. Datasets and fine-tuning scripts are made easily accessible at https://hf.co/datasets/google/xtreme_s.
Expanding Pretrained Models to Thousands More Languages via Lexicon-based Adaptation
Apr 06, 2022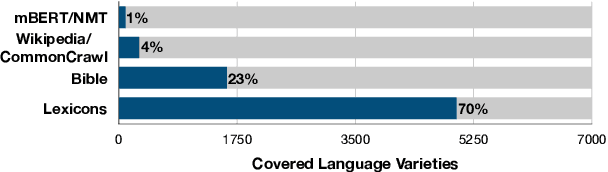

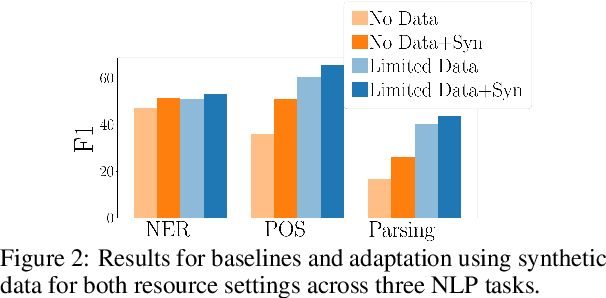
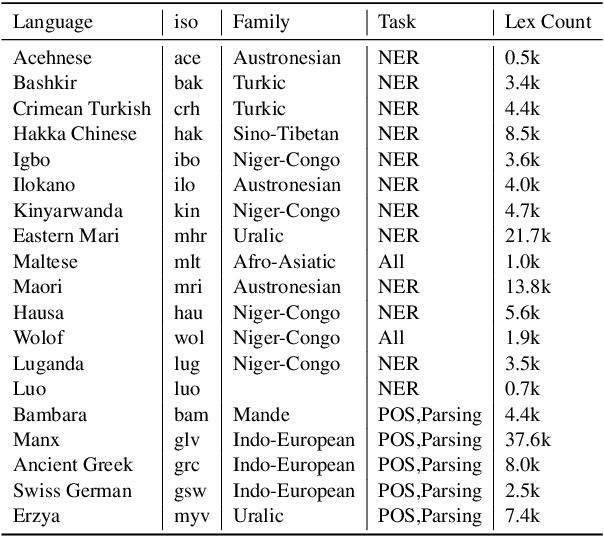
The performance of multilingual pretrained models is highly dependent on the availability of monolingual or parallel text present in a target language. Thus, the majority of the world's languages cannot benefit from recent progress in NLP as they have no or limited textual data. To expand possibilities of using NLP technology in these under-represented languages, we systematically study strategies that relax the reliance on conventional language resources through the use of bilingual lexicons, an alternative resource with much better language coverage. We analyze different strategies to synthesize textual or labeled data using lexicons, and how this data can be combined with monolingual or parallel text when available. For 19 under-represented languages across 3 tasks, our methods lead to consistent improvements of up to 5 and 15 points with and without extra monolingual text respectively. Overall, our study highlights how NLP methods can be adapted to thousands more languages that are under-served by current technology
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Mar 24, 2022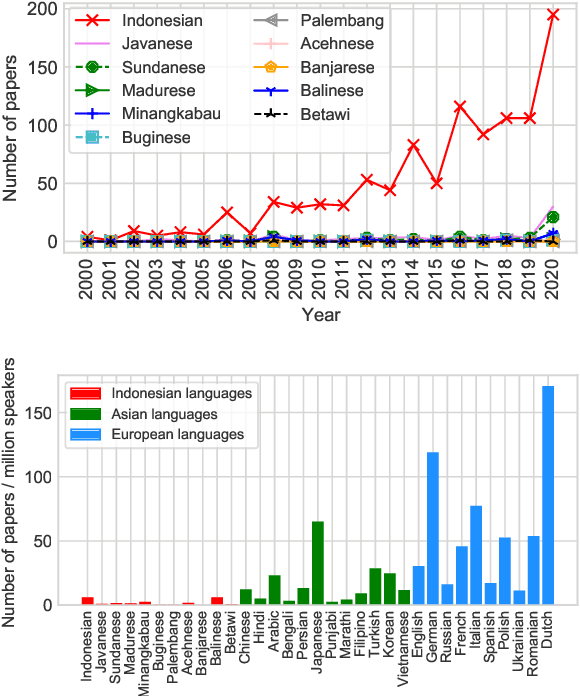
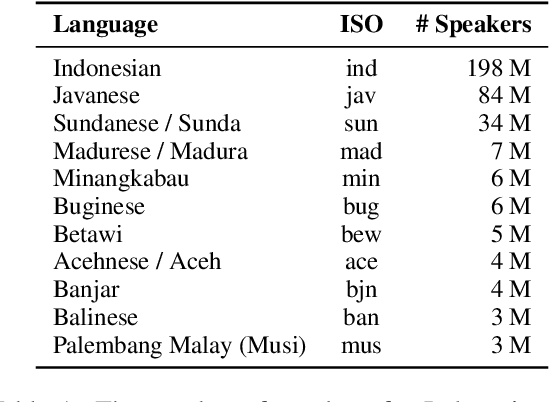
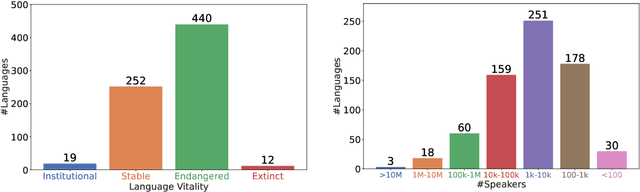

NLP research is impeded by a lack of resources and awareness of the challenges presented by underrepresented languages and dialects. Focusing on the languages spoken in Indonesia, the second most linguistically diverse and the fourth most populous nation of the world, we provide an overview of the current state of NLP research for Indonesia's 700+ languages. We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia but also other underrepresented languages.