 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaTa: A Multilingual Table-to-Text Dataset for African Languages
Oct 31, 2022



Existing data-to-text generation datasets are mostly limited to English. To address this lack of data, we create Table-to-Text in African languages (TaTa), the first large multilingual table-to-text dataset with a focus on African languages. We created TaTa by transcribing figures and accompanying text in bilingual reports by the Demographic and Health Surveys Program, followed by professional translation to make the dataset fully parallel. TaTa includes 8,700 examples in nine languages including four African languages (Hausa, Igbo, Swahili, and Yor\`ub\'a) and a zero-shot test language (Russian). We additionally release screenshots of the original figures for future research on multilingual multi-modal approaches. Through an in-depth human evaluation, we show that TaTa is challenging for current models and that less than half the outputs from an mT5-XXL-based model are understandable and attributable to the source data. We further demonstrate that existing metrics perform poorly for TaTa and introduce learned metrics that achieve a high correlation with human judgments. We release all data and annotations at https://github.com/google-research/url-nlp.
FRMT: A Benchmark for Few-Shot Region-Aware Machine Translation
Oct 01, 2022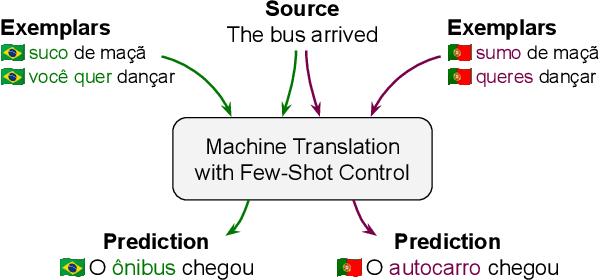
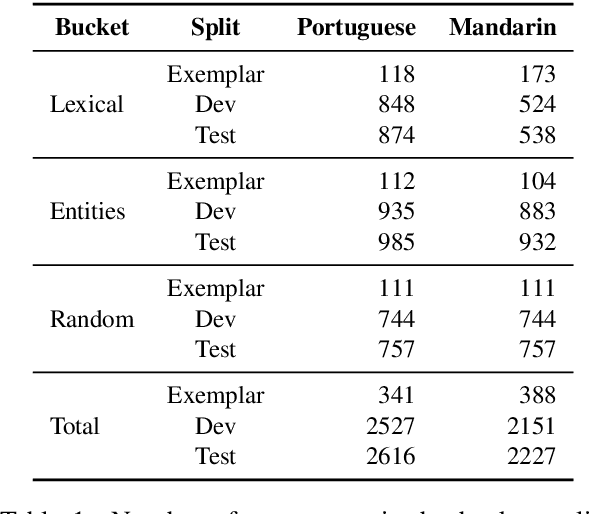

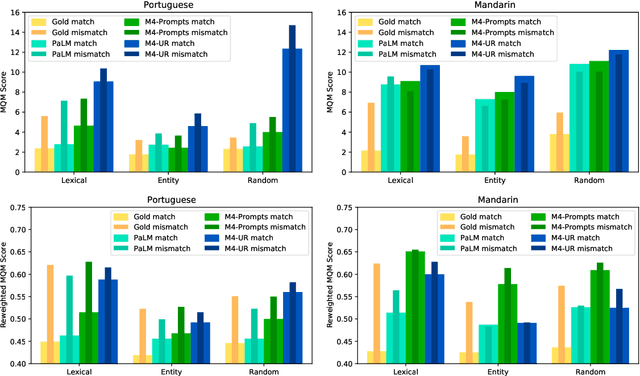
We present FRMT, a new dataset and evaluation benchmark for Few-shot Region-aware Machine Translation, a type of style-targeted translation. The dataset consists of professional translations from English into two regional variants each of Portuguese and Mandarin Chinese. Source documents are selected to enable detailed analysis of phenomena of interest, including lexically distinct terms and distractor terms. We explore automatic evaluation metrics for FRMT and validate their correlation with expert human evaluation across both region-matched and mismatched rating scenarios. Finally, we present a number of baseline models for this task, and offer guidelines for how researchers can train, evaluate, and compare their own models. Our dataset and evaluation code are publicly available: https://bit.ly/frmt-task
MOLEMAN: Mention-Only Linking of Entities with a Mention Annotation Network
Jun 02, 2021
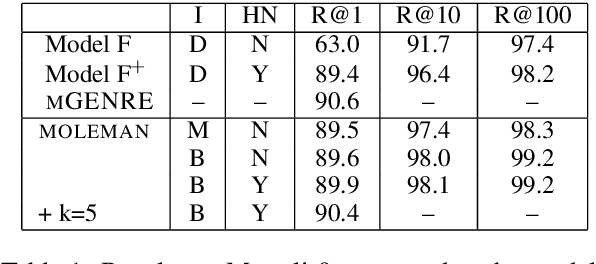
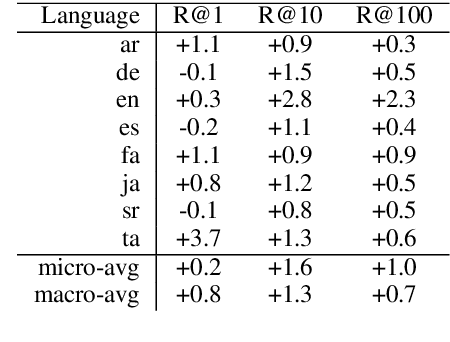
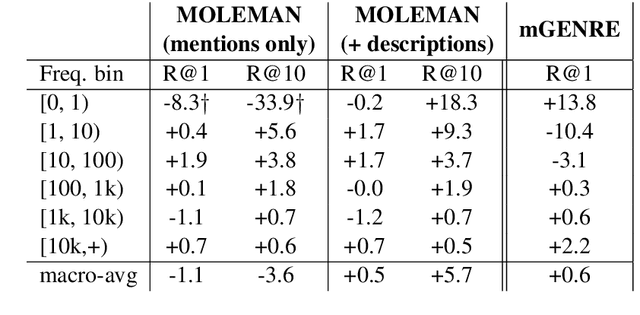
We present an instance-based nearest neighbor approach to entity linking. In contrast to most prior entity retrieval systems which represent each entity with a single vector, we build a contextualized mention-encoder that learns to place similar mentions of the same entity closer in vector space than mentions of different entities. This approach allows all mentions of an entity to serve as "class prototypes" as inference involves retrieving from the full set of labeled entity mentions in the training set and applying the nearest mention neighbor's entity label. Our model is trained on a large multilingual corpus of mention pairs derived from Wikipedia hyperlinks, and performs nearest neighbor inference on an index of 700 million mentions. It is simpler to train, gives more interpretable predictions, and outperforms all other systems on two multilingual entity linking benchmarks.
Entity Linking in 100 Languages
Nov 05, 2020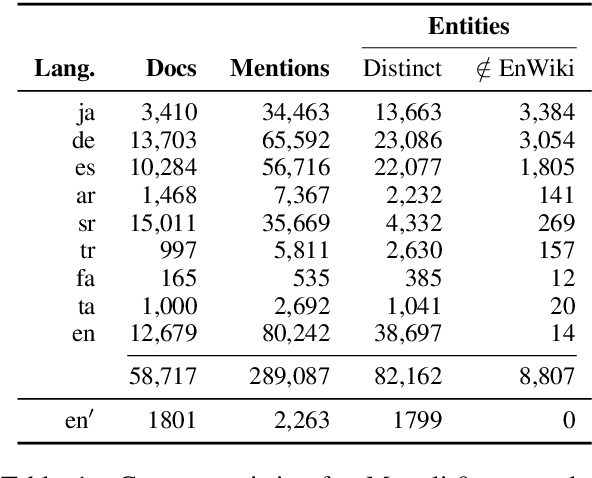
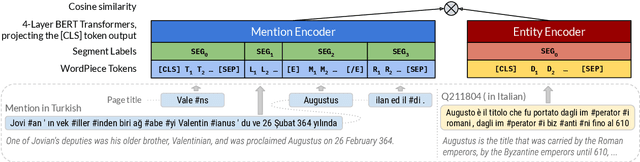
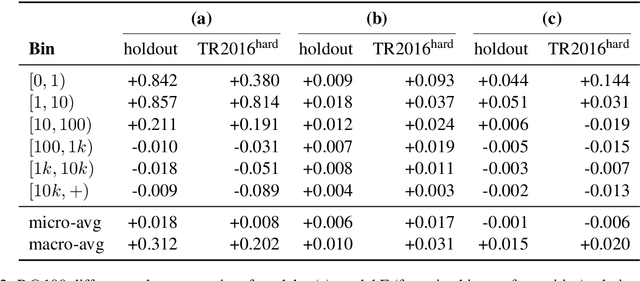
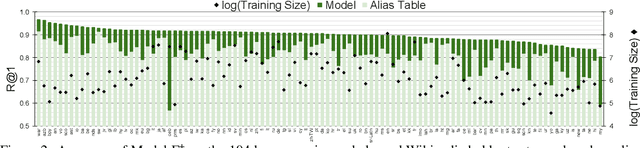
We propose a new formulation for multilingual entity linking, where language-specific mentions resolve to a language-agnostic Knowledge Base. We train a dual encoder in this new setting, building on prior work with improved feature representation, negative mining, and an auxiliary entity-pairing task, to obtain a single entity retrieval model that covers 100+ languages and 20 million entities. The model outperforms state-of-the-art results from a far more limited cross-lingual linking task. Rare entities and low-resource languages pose challenges at this large-scale, so we advocate for an increased focus on zero- and few-shot evaluation. To this end, we provide Mewsli-9, a large new multilingual dataset (http://goo.gle/mewsli-dataset) matched to our setting, and show how frequency-based analysis provided key insights for our model and training enhancements.
Asking without Telling: Exploring Latent Ontologies in Contextual Representations
Apr 29, 2020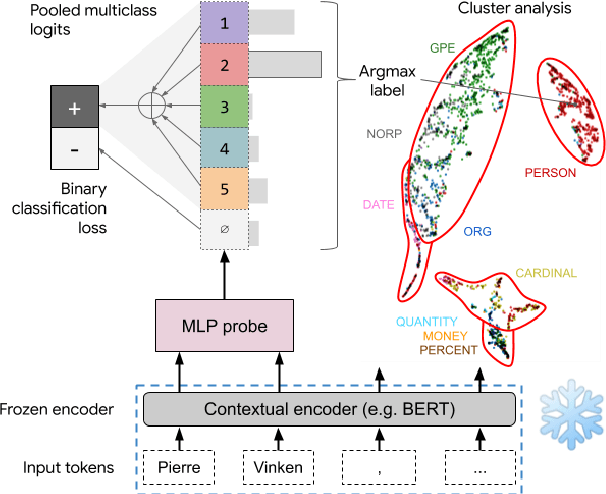
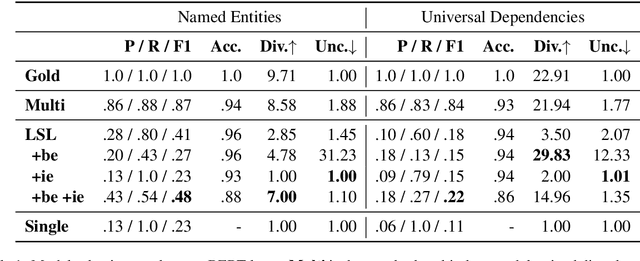
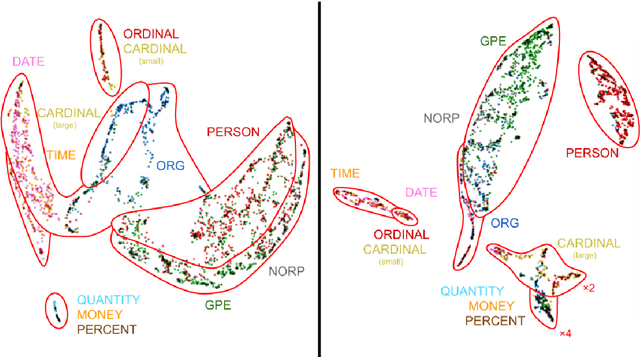
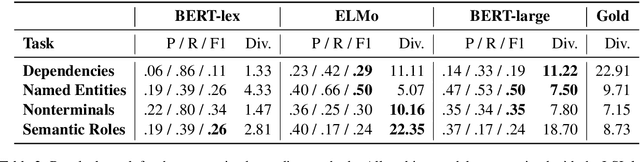
The success of pretrained contextual encoders, such as ELMo and BERT, has brought a great deal of interest in what these models learn: do they, without explicit supervision, learn to encode meaningful notions of linguistic structure? If so, how is this structure encoded? To investigate this, we introduce latent subclass learning (LSL): a modification to existing classifier-based probing methods that induces a latent categorization (or ontology) of the probe's inputs. Without access to fine-grained gold labels, LSL extracts emergent structure from input representations in an interpretable and quantifiable form. In experiments, we find strong evidence of familiar categories, such as a notion of personhood in ELMo, as well as novel ontological distinctions, such as a preference for fine-grained semantic roles on core arguments. Our results provide unique new evidence of emergent structure in pretrained encoders, including departures from existing annotations which are inaccessible to earlier methods.
Learning To Split and Rephrase From Wikipedia Edit History
Aug 28, 2018

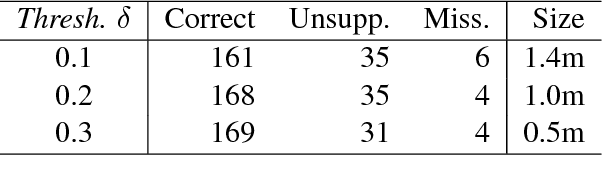
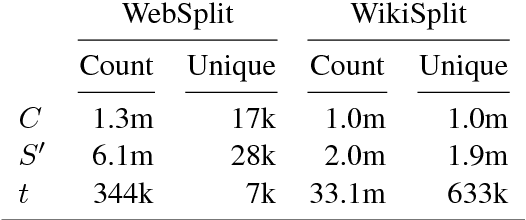
Split and rephrase is the task of breaking down a sentence into shorter ones that together convey the same meaning. We extract a rich new dataset for this task by mining Wikipedia's edit history: WikiSplit contains one million naturally occurring sentence rewrites, providing sixty times more distinct split examples and a ninety times larger vocabulary than the WebSplit corpus introduced by Narayan et al. (2017) as a benchmark for this task. Incorporating WikiSplit as training data produces a model with qualitatively better predictions that score 32 BLEU points above the prior best result on the WebSplit benchmark.
Natural Language Processing with Small Feed-Forward Networks
Aug 01, 2017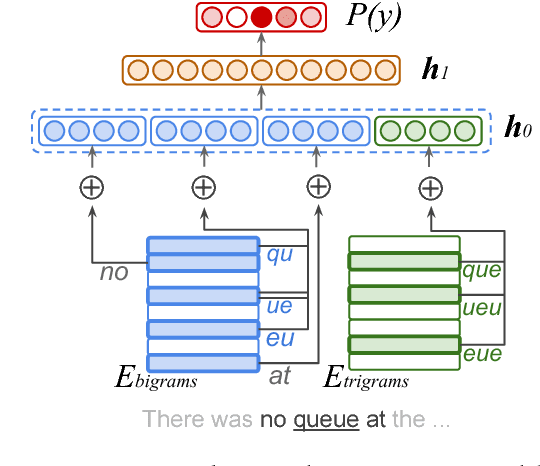
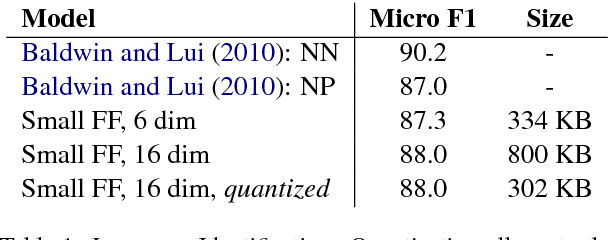
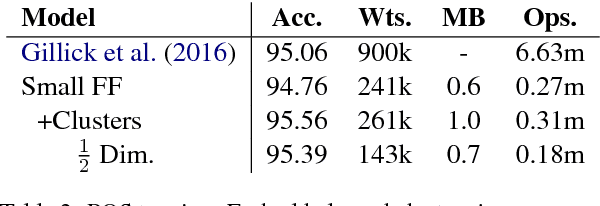
We show that small and shallow feed-forward neural networks can achieve near state-of-the-art results on a range of unstructured and structured language processing tasks while being considerably cheaper in memory and computational requirements than deep recurrent models. Motivated by resource-constrained environments like mobile phones, we showcase simple techniques for obtaining such small neural network models, and investigate different tradeoffs when deciding how to allocate a small memory budget.
Cross-Lingual Morphological Tagging for Low-Resource Languages
Jun 14, 2016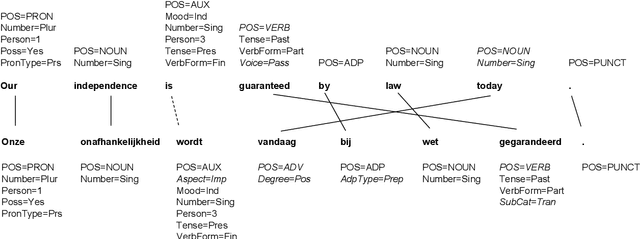
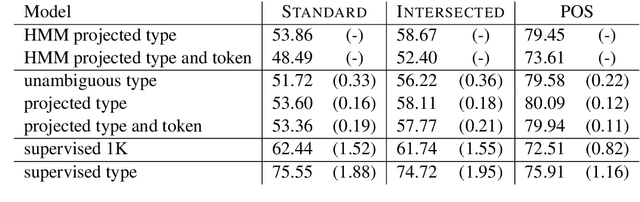
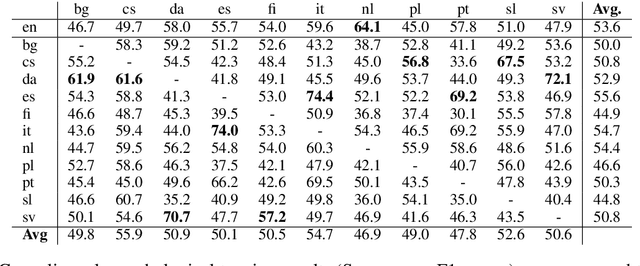
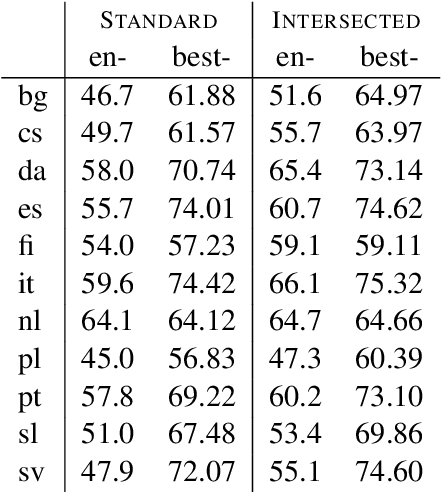
Morphologically rich languages often lack the annotated linguistic resources required to develop accurate natural language processing tools. We propose models suitable for training morphological taggers with rich tagsets for low-resource languages without using direct supervision. Our approach extends existing approaches of projecting part-of-speech tags across languages, using bitext to infer constraints on the possible tags for a given word type or token. We propose a tagging model using Wsabie, a discriminative embedding-based model with rank-based learning. In our evaluation on 11 languages, on average this model performs on par with a baseline weakly-supervised HMM, while being more scalable. Multilingual experiments show that the method performs best when projecting between related language pairs. Despite the inherently lossy projection, we show that the morphological tags predicted by our models improve the downstream performance of a parser by +0.6 LAS on average.
Probabilistic Modelling of Morphologically Rich Languages
Aug 18, 2015

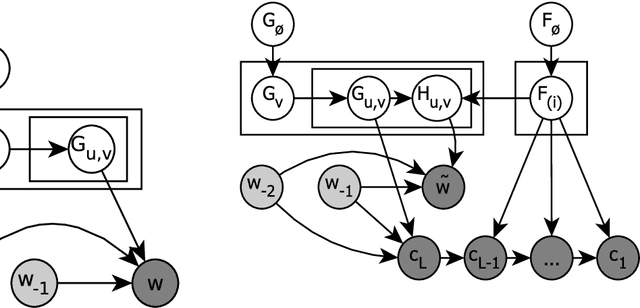
This thesis investigates how the sub-structure of words can be accounted for in probabilistic models of language. Such models play an important role in natural language processing tasks such as translation or speech recognition, but often rely on the simplistic assumption that words are opaque symbols. This assumption does not fit morphologically complex language well, where words can have rich internal structure and sub-word elements are shared across distinct word forms. Our approach is to encode basic notions of morphology into the assumptions of three different types of language models, with the intention that leveraging shared sub-word structure can improve model performance and help overcome data sparsity that arises from morphological processes. In the context of n-gram language modelling, we formulate a new Bayesian model that relies on the decomposition of compound words to attain better smoothing, and we develop a new distributed language model that learns vector representations of morphemes and leverages them to link together morphologically related words. In both cases, we show that accounting for word sub-structure improves the models' intrinsic performance and provides benefits when applied to other tasks, including machine translation. We then shift the focus beyond the modelling of word sequences and consider models that automatically learn what the sub-word elements of a given language are, given an unannotated list of words. We formulate a novel model that can learn discontiguous morphemes in addition to the more conventional contiguous morphemes that most previous models are limited to. This approach is demonstrated on Semitic languages, and we find that modelling discontiguous sub-word structures leads to improvements in the task of segmenting words into their contiguous morphemes.
Compositional Morphology for Word Representations and Language Modelling
May 16, 2014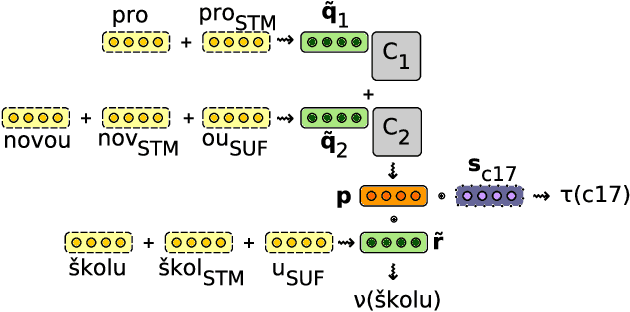
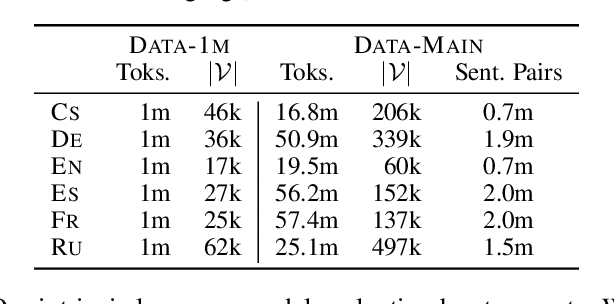
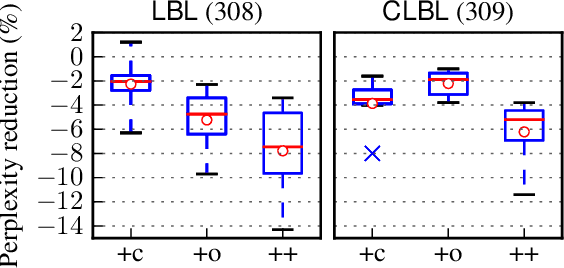
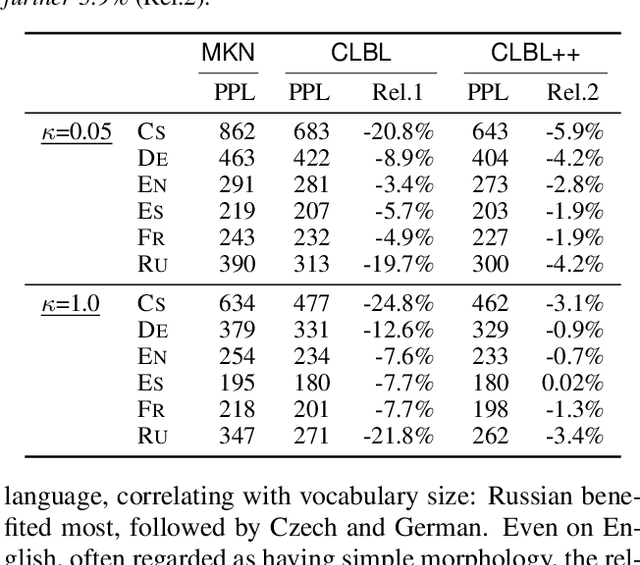
This paper presents a scalable method for integrating compositional morphological representations into a vector-based probabilistic language model. Our approach is evaluated in the context of log-bilinear language models, rendered suitably efficient for implementation inside a machine translation decoder by factoring the vocabulary. We perform both intrinsic and extrinsic evaluations, presenting results on a range of languages which demonstrate that our model learns morphological representations that both perform well on word similarity tasks and lead to substantial reductions in perplexity. When used for translation into morphologically rich languages with large vocabularies, our models obtain improvements of up to 1.2 BLEU points relative to a baseline system using back-off n-gram models.