 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Guided Image Completion with Image-level and Object-level Semantic Discriminators
Dec 13, 2022Structure-guided image completion aims to inpaint a local region of an image according to an input guidance map from users. While such a task enables many practical applications for interactive editing, existing methods often struggle to hallucinate realistic object instances in complex natural scenes. Such a limitation is partially due to the lack of semantic-level constraints inside the hole region as well as the lack of a mechanism to enforce realistic object generation. In this work, we propose a learning paradigm that consists of semantic discriminators and object-level discriminators for improving the generation of complex semantics and objects. Specifically, the semantic discriminators leverage pretrained visual features to improve the realism of the generated visual concepts. Moreover, the object-level discriminators take aligned instances as inputs to enforce the realism of individual objects. Our proposed scheme significantly improves the generation quality and achieves state-of-the-art results on various tasks, including segmentation-guided completion, edge-guided manipulation and panoptically-guided manipulation on Places2 datasets. Furthermore, our trained model is flexible and can support multiple editing use cases, such as object insertion, replacement, removal and standard inpainting. In particular, our trained model combined with a novel automatic image completion pipeline achieves state-of-the-art results on the standard inpainting task.
ObjectStitch: Generative Object Compositing
Dec 05, 2022Object compositing based on 2D images is a challenging problem since it typically involves multiple processing stages such as color harmonization, geometry correction and shadow generation to generate realistic results. Furthermore, annotating training data pairs for compositing requires substantial manual effort from professionals, and is hardly scalable. Thus, with the recent advances in generative models, in this work, we propose a self-supervised framework for object compositing by leveraging the power of conditional diffusion models. Our framework can hollistically address the object compositing task in a unified model, transforming the viewpoint, geometry, color and shadow of the generated object while requiring no manual labeling. To preserve the input object's characteristics, we introduce a content adaptor that helps to maintain categorical semantics and object appearance. A data augmentation method is further adopted to improve the fidelity of the generator. Our method outperforms relevant baselines in both realism and faithfulness of the synthesized result images in a user study on various real-world images.
GALA: Toward Geometry-and-Lighting-Aware Object Search for Compositing
Mar 31, 2022
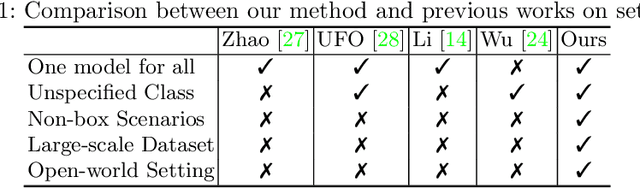

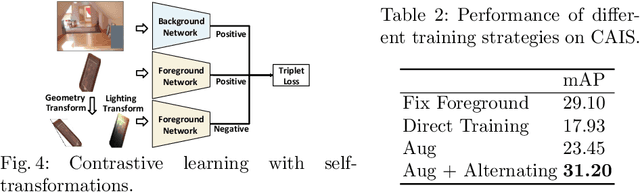
Compositing-aware object search aims to find the most compatible objects for compositing given a background image and a query bounding box. Previous works focus on learning compatibility between the foreground object and background, but fail to learn other important factors from large-scale data, i.e. geometry and lighting. To move a step further, this paper proposes GALA (Geometry-and-Lighting-Aware), a generic foreground object search method with discriminative modeling on geometry and lighting compatibility for open-world image compositing. Remarkably, it achieves state-of-the-art results on the CAIS dataset and generalizes well on large-scale open-world datasets, i.e. Pixabay and Open Images. In addition, our method can effectively handle non-box scenarios, where users only provide background images without any input bounding box. A web demo (see supplementary materials) is built to showcase applications of the proposed method for compositing-aware search and automatic location/scale prediction for the foreground object.
CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022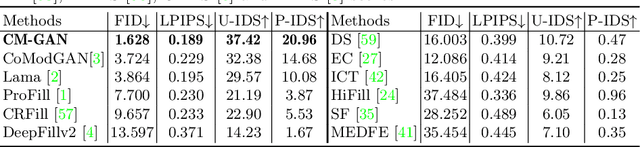
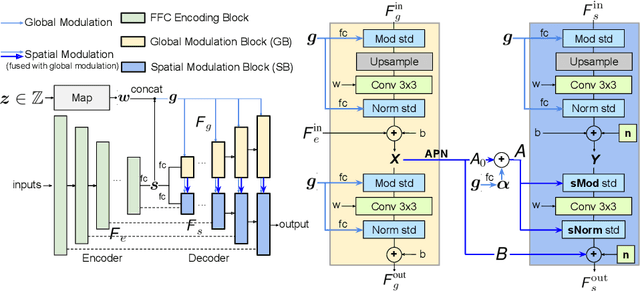
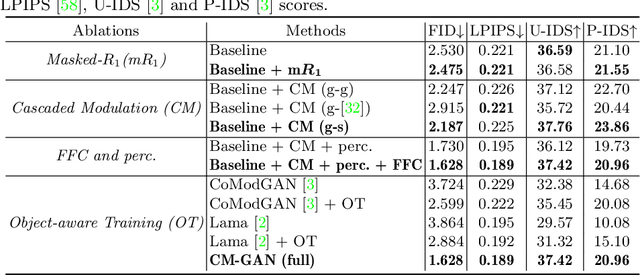

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.
Generalized Few-Shot Semantic Segmentation: All You Need is Fine-Tuning
Dec 21, 2021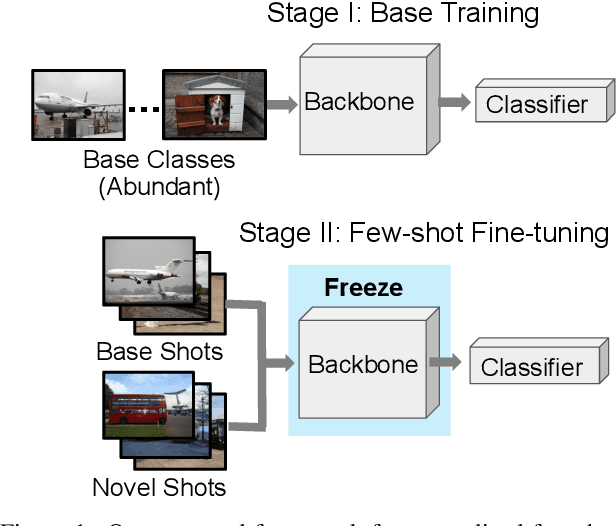
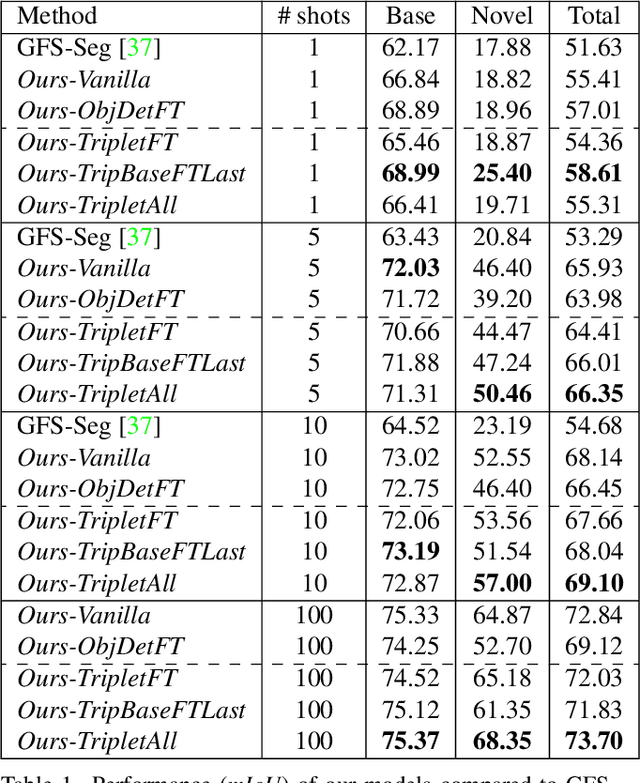
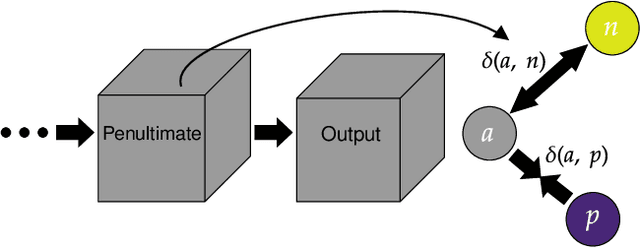
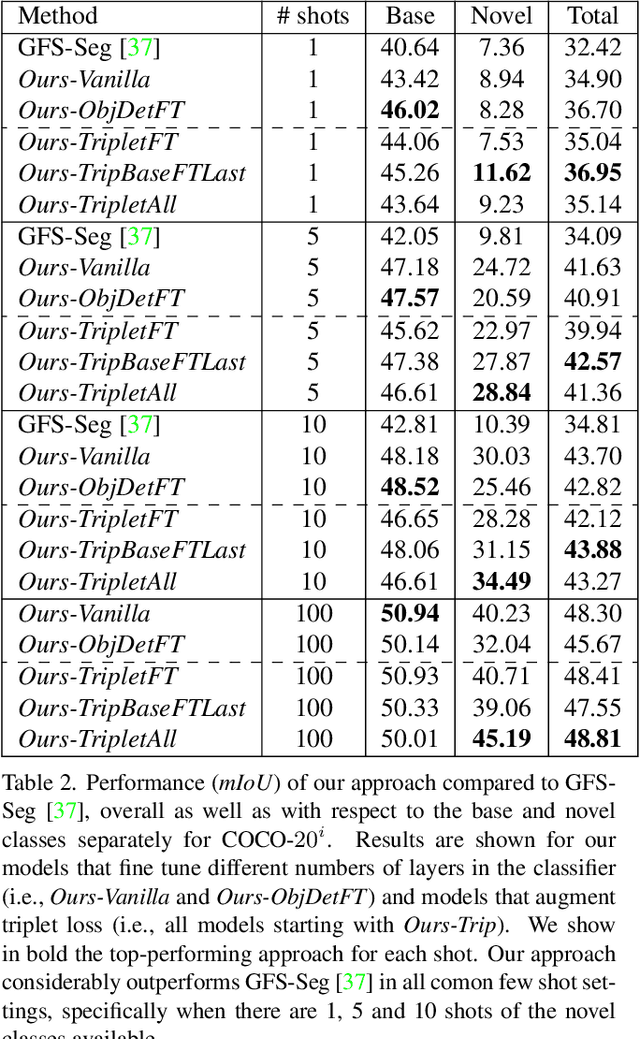
Generalized few-shot semantic segmentation was introduced to move beyond only evaluating few-shot segmentation models on novel classes to include testing their ability to remember base classes. While all approaches currently are based on meta-learning, they perform poorly and saturate in learning after observing only a few shots. We propose the first fine-tuning solution, and demonstrate that it addresses the saturation problem while achieving state-of-art results on two datasets, PASCAL-$5^i$ and COCO-$20^i$. We also show it outperforms existing methods whether fine-tuning multiple final layers or only the final layer. Finally, we present a triplet loss regularization that shows how to redistribute the balance of performance between novel and base categories so that there is a smaller gap between them.
Learning to Predict Visual Attributes in the Wild
Jun 17, 2021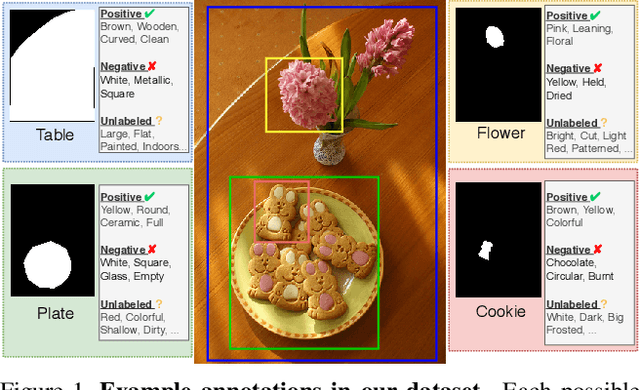

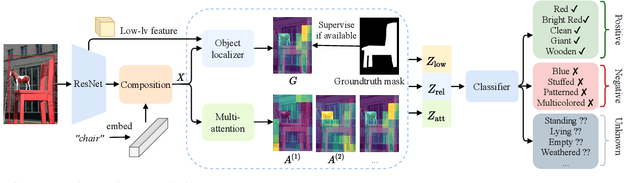
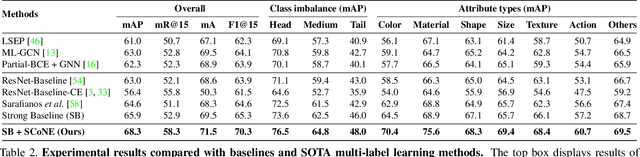
Visual attributes constitute a large portion of information contained in a scene. Objects can be described using a wide variety of attributes which portray their visual appearance (color, texture), geometry (shape, size, posture), and other intrinsic properties (state, action). Existing work is mostly limited to study of attribute prediction in specific domains. In this paper, we introduce a large-scale in-the-wild visual attribute prediction dataset consisting of over 927K attribute annotations for over 260K object instances. Formally, object attribute prediction is a multi-label classification problem where all attributes that apply to an object must be predicted. Our dataset poses significant challenges to existing methods due to large number of attributes, label sparsity, data imbalance, and object occlusion. To this end, we propose several techniques that systematically tackle these challenges, including a base model that utilizes both low- and high-level CNN features with multi-hop attention, reweighting and resampling techniques, a novel negative label expansion scheme, and a novel supervised attribute-aware contrastive learning algorithm. Using these techniques, we achieve near 3.7 mAP and 5.7 overall F1 points improvement over the current state of the art. Further details about the VAW dataset can be found at http://vawdataset.com/.
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
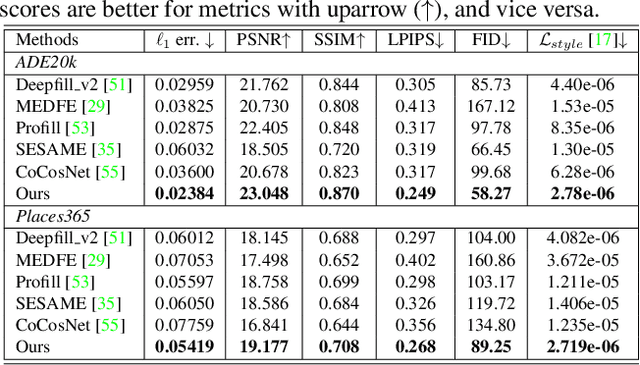
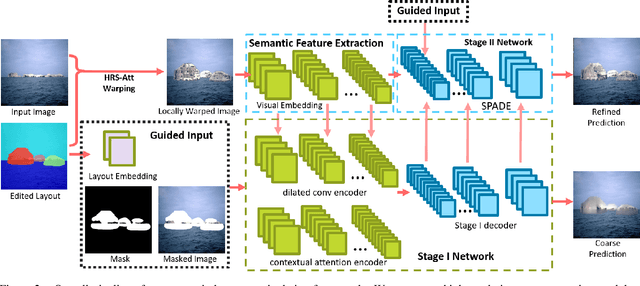
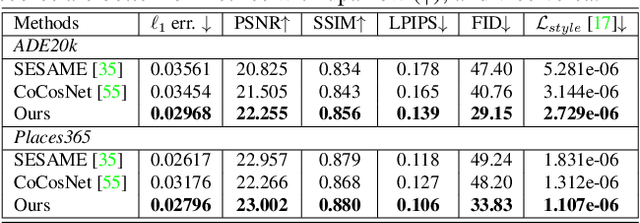
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
PhraseCut: Language-based Image Segmentation in the Wild
Aug 03, 2020



We consider the problem of segmenting image regions given a natural language phrase, and study it on a novel dataset of 77,262 images and 345,486 phrase-region pairs. Our dataset is collected on top of the Visual Genome dataset and uses the existing annotations to generate a challenging set of referring phrases for which the corresponding regions are manually annotated. Phrases in our dataset correspond to multiple regions and describe a large number of object and stuff categories as well as their attributes such as color, shape, parts, and relationships with other entities in the image. Our experiments show that the scale and diversity of concepts in our dataset poses significant challenges to the existing state-of-the-art. We systematically handle the long-tail nature of these concepts and present a modular approach to combine category, attribute, and relationship cues that outperforms existing approaches.
Objectness-Aware One-Shot Semantic Segmentation
Apr 06, 2020
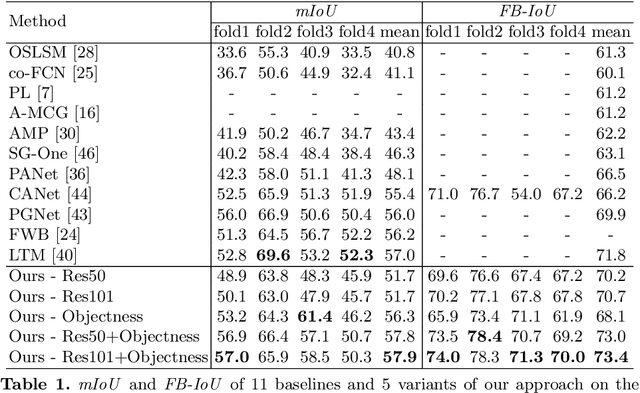
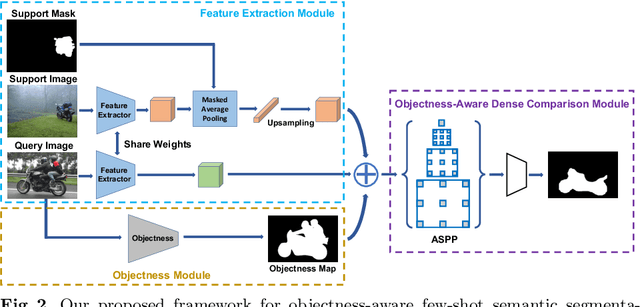

While deep convolutional neural networks have led to great progress in image semantic segmentation, they typically require collecting a large number of densely-annotated images for training. Moreover, once trained, the model can only make predictions in a pre-defined set of categories. Therefore, few-shot image semantic segmentation has been explored to learn to segment from only a few annotated examples. In this paper, we tackle the challenging one-shot semantic segmentation problem by taking advantage of objectness. In order to capture prior knowledge of object and background, we first train an objectness segmentation module which generalizes well to unseen categories. Then we use the objectness module to predict the objects present in the query image, and train an objectness-aware few-shot segmentation model that takes advantage of both the object information and limited annotations of the unseen category to perform segmentation in the query image. Our method achieves a mIoU score of 57.9% and 22.6% given only one annotated example of an unseen category in PASCAL-5i and COCO-20i, outperforming related baselines overall.
DeepStrip: High Resolution Boundary Refinement
Mar 25, 2020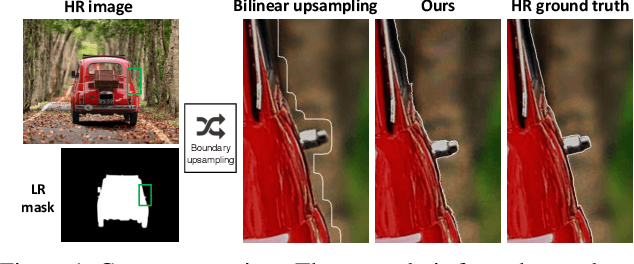
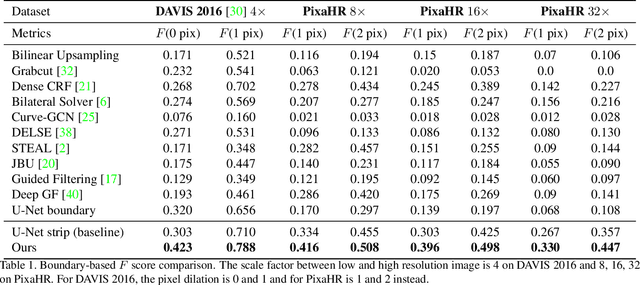
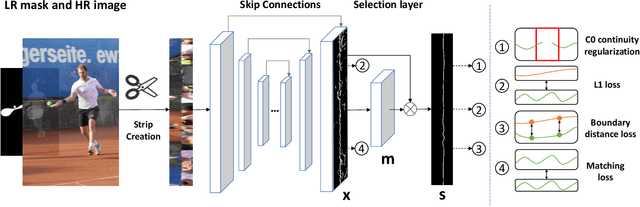
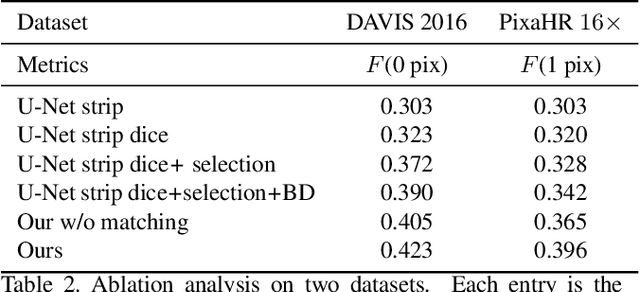
In this paper, we target refining the boundaries in high resolution images given low resolution masks. For memory and computation efficiency, we propose to convert the regions of interest into strip images and compute a boundary prediction in the strip domain. To detect the target boundary, we present a framework with two prediction layers. First, all potential boundaries are predicted as an initial prediction and then a selection layer is used to pick the target boundary and smooth the result. To encourage accurate prediction, a loss which measures the boundary distance in the strip domain is introduced. In addition, we enforce a matching consistency and C0 continuity regularization to the network to reduce false alarms. Extensive experiments on both public and a newly created high resolution dataset strongly validate our approach.