 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration vs Decision Making: Revisiting the Reliability Paradox in Unlearned Language Models
May 20, 2026Machine unlearning aims to remove the influence of specific training data from a model while preserving reliable behavior on the remaining data, making reliable prediction and uncertainty estimation essential for evaluation. Calibration is commonly used as a proxy for reliability in language models, but low calibration error does not necessarily imply reliable decision rules, as models may rely on spurious correlations while remaining well calibrated. We investigate this gap in generative language models using the multiple-choice question-answering evaluation protocol on the TOFU benchmark, measuring probabilistic reliability with calibration metrics (ECE, MCE, Brier) and decision-rule reliability via attribution-based shortcut detection with Integrated Gradients and Local Mutual Information. We find that fine-tuned models achieve low calibration error (ECE ~ 0.04) compared to pretrained models (ECE > 0.5), and models after unlearning retain similarly low calibration despite reduced accuracy on the forget split, while attribution analysis shows increased reliance on correlation-based tokens. These results demonstrate that good calibration can coexist with shortcut-based decision rules after unlearning, extending the reliability paradox to the machine unlearning setting.
TechING: Towards Real World Technical Image Understanding via VLMs
Jan 26, 2026Professionals working in technical domain typically hand-draw (on whiteboard, paper, etc.) technical diagrams (e.g., flowcharts, block diagrams, etc.) during discussions; however, if they want to edit these later, it needs to be drawn from scratch. Modern day VLMs have made tremendous progress in image understanding but they struggle when it comes to understanding technical diagrams. One way to overcome this problem is to fine-tune on real world hand-drawn images, but it is not practically possible to generate large number of such images. In this paper, we introduce a large synthetically generated corpus (reflective of real world images) for training VLMs and subsequently evaluate VLMs on a smaller corpus of hand-drawn images (with the help of humans). We introduce several new self-supervision tasks for training and perform extensive experiments with various baseline models and fine-tune Llama 3.2 11B-instruct model on synthetic images on these tasks to obtain LLama-VL-TUG, which significantly improves the ROUGE-L performance of Llama 3.2 11B-instruct by 2.14x and achieves the best all-round performance across all baseline models. On real-world images, human evaluation reveals that we achieve minimum compilation errors across all baselines in 7 out of 8 diagram types and improve the average F1 score of Llama 3.2 11B-instruct by 6.97x.
MM-Telco: Benchmarks and Multimodal Large Language Models for Telecom Applications
Nov 17, 2025Large Language Models (LLMs) have emerged as powerful tools for automating complex reasoning and decision-making tasks. In telecommunications, they hold the potential to transform network optimization, automate troubleshooting, enhance customer support, and ensure regulatory compliance. However, their deployment in telecom is hindered by domain-specific challenges that demand specialized adaptation. To overcome these challenges and to accelerate the adaptation of LLMs for telecom, we propose MM-Telco, a comprehensive suite of multimodal benchmarks and models tailored for the telecom domain. The benchmark introduces various tasks (both text based and image based) that address various practical real-life use cases such as network operations, network management, improving documentation quality, and retrieval of relevant text and images. Further, we perform baseline experiments with various LLMs and VLMs. The models fine-tuned on our dataset exhibit a significant boost in performance. Our experiments also help analyze the weak areas in the working of current state-of-art multimodal LLMs, thus guiding towards further development and research.
EtiCor++: Towards Understanding Etiquettical Bias in LLMs
Jun 10, 2025In recent years, researchers have started analyzing the cultural sensitivity of LLMs. In this respect, Etiquettes have been an active area of research. Etiquettes are region-specific and are an essential part of the culture of a region; hence, it is imperative to make LLMs sensitive to etiquettes. However, there needs to be more resources in evaluating LLMs for their understanding and bias with regard to etiquettes. In this resource paper, we introduce EtiCor++, a corpus of etiquettes worldwide. We introduce different tasks for evaluating LLMs for knowledge about etiquettes across various regions. Further, we introduce various metrics for measuring bias in LLMs. Extensive experimentation with LLMs shows inherent bias towards certain regions.
CoMuMDR: Code-mixed Multi-modal Multi-domain corpus for Discourse paRsing in conversations
Jun 10, 2025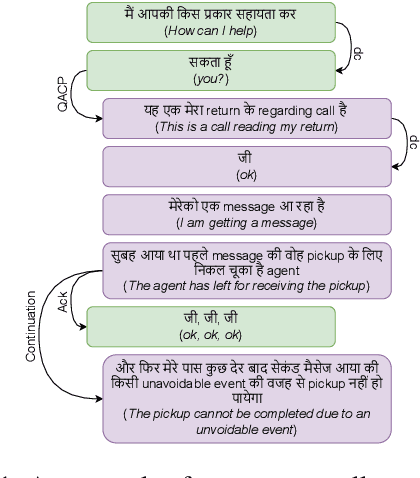



Discourse parsing is an important task useful for NLU applications such as summarization, machine comprehension, and emotion recognition. The current discourse parsing datasets based on conversations consists of written English dialogues restricted to a single domain. In this resource paper, we introduce CoMuMDR: Code-mixed Multi-modal Multi-domain corpus for Discourse paRsing in conversations. The corpus (code-mixed in Hindi and English) has both audio and transcribed text and is annotated with nine discourse relations. We experiment with various SoTA baseline models; the poor performance of SoTA models highlights the challenges of multi-domain code-mixed corpus, pointing towards the need for developing better models for such realistic settings.
LoRMA: Low-Rank Multiplicative Adaptation for LLMs
Jun 09, 2025Large Language Models have shown remarkable capabilities in the NLP domain. Their effectiveness can mainly be attributed to their ability to adapt to an array of downstream tasks. However, generally, full fine-tuning is a computationally expensive job. To mitigate this, many techniques have been developed that prime efficiency, a prominent one being Low-Rank Adaptation (LoRA). However, LoRA and its variants employ re-parametrized additive updates. In this paper, we propose Low-Rank Multiplicative Adaptation (LoRMA), which shifts the paradigm of additive updates to a richer space of matrix multiplicative transformations. We tackle challenges such as computational complexity and rank bottleneck of matrix multiplication by effectively re-ordering operations and introducing rank inflation strategies. We conduct extensive experiments to demonstrate the effectiveness of our approach in terms of various evaluation metrics.
Towards Quantifying Commonsense Reasoning with Mechanistic Insights
Apr 14, 2025Commonsense reasoning deals with the implicit knowledge that is well understood by humans and typically acquired via interactions with the world. In recent times, commonsense reasoning and understanding of various LLMs have been evaluated using text-based tasks. In this work, we argue that a proxy of this understanding can be maintained as a graphical structure that can further help to perform a rigorous evaluation of commonsense reasoning abilities about various real-world activities. We create an annotation scheme for capturing this implicit knowledge in the form of a graphical structure for 37 daily human activities. We find that the created resource can be used to frame an enormous number of commonsense queries (~ 10^{17}), facilitating rigorous evaluation of commonsense reasoning in LLMs. Moreover, recently, the remarkable performance of LLMs has raised questions about whether these models are truly capable of reasoning in the wild and, in general, how reasoning occurs inside these models. In this resource paper, we bridge this gap by proposing design mechanisms that facilitate research in a similar direction. Our findings suggest that the reasoning components are localized in LLMs that play a prominent role in decision-making when prompted with a commonsense query.
COLD: Causal reasOning in cLosed Daily activities
Nov 29, 2024



Large Language Models (LLMs) have shown state-of-the-art performance in a variety of tasks, including arithmetic and reasoning; however, to gauge the intellectual capabilities of LLMs, causal reasoning has become a reliable proxy for validating a general understanding of the mechanics and intricacies of the world similar to humans. Previous works in natural language processing (NLP) have either focused on open-ended causal reasoning via causal commonsense reasoning (CCR) or framed a symbolic representation-based question answering for theoretically backed-up analysis via a causal inference engine. The former adds an advantage of real-world grounding but lacks theoretically backed-up analysis/validation, whereas the latter is far from real-world grounding. In this work, we bridge this gap by proposing the COLD (Causal reasOning in cLosed Daily activities) framework, which is built upon human understanding of daily real-world activities to reason about the causal nature of events. We show that the proposed framework facilitates the creation of enormous causal queries (~ 9 million) and comes close to the mini-turing test, simulating causal reasoning to evaluate the understanding of a daily real-world task. We evaluate multiple LLMs on the created causal queries and find that causal reasoning is challenging even for activities trivial to humans. We further explore (the causal reasoning abilities of LLMs) using the backdoor criterion to determine the causal strength between events.
Towards Robust Evaluation of Unlearning in LLMs via Data Transformations
Nov 23, 2024



Large Language Models (LLMs) have shown to be a great success in a wide range of applications ranging from regular NLP-based use cases to AI agents. LLMs have been trained on a vast corpus of texts from various sources; despite the best efforts during the data pre-processing stage while training the LLMs, they may pick some undesirable information such as personally identifiable information (PII). Consequently, in recent times research in the area of Machine Unlearning (MUL) has become active, the main idea is to force LLMs to forget (unlearn) certain information (e.g., PII) without suffering from performance loss on regular tasks. In this work, we examine the robustness of the existing MUL techniques for their ability to enable leakage-proof forgetting in LLMs. In particular, we examine the effect of data transformation on forgetting, i.e., is an unlearned LLM able to recall forgotten information if there is a change in the format of the input? Our findings on the TOFU dataset highlight the necessity of using diverse data formats to quantify unlearning in LLMs more reliably.
Generation and De-Identification of Indian Clinical Discharge Summaries using LLMs
Jul 08, 2024



The consequences of a healthcare data breach can be devastating for the patients, providers, and payers. The average financial impact of a data breach in recent months has been estimated to be close to USD 10 million. This is especially significant for healthcare organizations in India that are managing rapid digitization while still establishing data governance procedures that align with the letter and spirit of the law. Computer-based systems for de-identification of personal information are vulnerable to data drift, often rendering them ineffective in cross-institution settings. Therefore, a rigorous assessment of existing de-identification against local health datasets is imperative to support the safe adoption of digital health initiatives in India. Using a small set of de-identified patient discharge summaries provided by an Indian healthcare institution, in this paper, we report the nominal performance of de-identification algorithms (based on language models) trained on publicly available non-Indian datasets, pointing towards a lack of cross-institutional generalization. Similarly, experimentation with off-the-shelf de-identification systems reveals potential risks associated with the approach. To overcome data scarcity, we explore generating synthetic clinical reports (using publicly available and Indian summaries) by performing in-context learning over Large Language Models (LLMs). Our experiments demonstrate the use of generated reports as an effective strategy for creating high-performing de-identification systems with good generalization capabilities.