 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of LLM-as-Judge: Why Inter-LLM Consensus Is Not Human Alignment
Jun 02, 2026LMs-as-judges are now standard, yet judges agree strongly with one another while agreeing only weakly with humans. We test whether this reflects shared signal or shared bias by measuring four geometric quantities on the standard LLM-as-judge stack across four community-built Indic datasets, eight Indic languages, and 41 LLM judges: score spread, effective rank, principal angle to the human subspace, and stacked correlations among judges and humans, all with bootstrap confidence intervals. On subjective rubrics, judges use less than half the human score range ($σ_J / σ_H \approx 0.3$--$0.5$). Their evaluation axis is nearly orthogonal to the human one and noticeably further from humans than humans are from each other ($87^\circ$--$89^\circ$ versus $78^\circ$--$81^\circ$). Inter-LLM agreement exceeds LLM--human agreement ($r_{LL} \approx 0.35$ versus $r_{LH} \approx 0.27$--$0.32$). On a rubric with a verifiable factual answer, the same diagnostics fall back into the human range (axis $58.5^\circ$; $r_{LH} = 0.519$). Fine-tuning and preference optimization recover spread ($0.32 \rightarrow 1.08$) but barely move the axis (still $87^\circ$--$88^\circ$). Only post-hoc calibration on a small human-anchored set improves all four community-health rubrics together, placing a calibrated 24B Indic judge ($r = 0.184$) ahead of GPT-5.5 ($r = 0.123$), yet still short of human reliability (human-human $r = 0.474$ on the verifiable rubric). We argue that inter-LLM agreement should be considered evidence of human alignment only when a direct geometric check on the judge's score subspace passes; otherwise, the consensus reflects agreement within a collapsed subspace.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
KAHANI: Culturally-Nuanced Visual Storytelling Pipeline for Non-Western Cultures
Oct 28, 2024



Large Language Models (LLMs) and Text-To-Image (T2I) models have demonstrated the ability to generate compelling text and visual stories. However, their outputs are predominantly aligned with the sensibilities of the Global North, often resulting in an outsider's gaze on other cultures. As a result, non-Western communities have to put extra effort into generating culturally specific stories. To address this challenge, we developed a visual storytelling pipeline called KAHANI that generates culturally grounded visual stories for non-Western cultures. Our pipeline leverages off-the-shelf models GPT-4 Turbo and Stable Diffusion XL (SDXL). By using Chain of Thought (CoT) and T2I prompting techniques, we capture the cultural context from user's prompt and generate vivid descriptions of the characters and scene compositions. To evaluate the effectiveness of KAHANI, we conducted a comparative user study with ChatGPT-4 (with DALL-E3) in which participants from different regions of India compared the cultural relevance of stories generated by the two tools. Results from the qualitative and quantitative analysis performed on the user study showed that KAHANI was able to capture and incorporate more Culturally Specific Items (CSIs) compared to ChatGPT-4. In terms of both its cultural competence and visual story generation quality, our pipeline outperformed ChatGPT-4 in 27 out of the 36 comparisons.
On the Interchangeability of Positional Embeddings in Multilingual Neural Machine Translation Models
Aug 21, 2024Standard Neural Machine Translation (NMT) models have traditionally been trained with Sinusoidal Positional Embeddings (PEs), which are inadequate for capturing long-range dependencies and are inefficient for long-context or document-level translation. In contrast, state-of-the-art large language models (LLMs) employ relative PEs, demonstrating superior length generalization. This work explores the potential for efficiently switching the Positional Embeddings of pre-trained NMT models from absolute sinusoidal PEs to relative approaches such as RoPE and ALiBi. Our findings reveal that sinusoidal PEs can be effectively replaced with RoPE and ALiBi with negligible or no performance loss, achieved by fine-tuning on a small fraction of high-quality data. Additionally, models trained without Positional Embeddings (NoPE) are not a viable solution for Encoder-Decoder architectures, as they consistently under-perform compared to models utilizing any form of Positional Embedding. Furthermore, even a model trained from scratch with these relative PEs slightly under-performs a fine-tuned model, underscoring the efficiency and validity of our hypothesis.
Cultural Conditioning or Placebo? On the Effectiveness of Socio-Demographic Prompting
Jun 17, 2024



Socio-demographic prompting is a commonly employed approach to study cultural biases in LLMs as well as for aligning models to certain cultures. In this paper, we systematically probe four LLMs (Llama 3, Mistral v0.2, GPT-3.5 Turbo and GPT-4) with prompts that are conditioned on culturally sensitive and non-sensitive cues, on datasets that are supposed to be culturally sensitive (EtiCor and CALI) or neutral (MMLU and ETHICS). We observe that all models except GPT-4 show significant variations in their responses on both kinds of datasets for both kinds of prompts, casting doubt on the robustness of the culturally-conditioned prompting as a method for eliciting cultural bias in models or as an alignment strategy. The work also calls rethinking the control experiment design to tease apart the cultural conditioning of responses from "placebo effect", i.e., random perturbations of model responses due to arbitrary tokens in the prompt.
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Jun 01, 2024



The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings.
Bridging the Gap: Dynamic Learning Strategies for Improving Multilingual Performance in LLMs
May 28, 2024Large language models (LLMs) are at the forefront of transforming numerous domains globally. However, their inclusivity and effectiveness remain limited for non-Latin scripts and low-resource languages. This paper tackles the imperative challenge of enhancing the multilingual performance of LLMs without extensive training or fine-tuning. Through systematic investigation and evaluation of diverse languages using popular question-answering (QA) datasets, we present novel techniques that unlock the true potential of LLMs in a polyglot landscape. Our approach encompasses three key strategies that yield significant improvements in multilingual proficiency. First, by meticulously optimizing prompts tailored for polyglot LLMs, we unlock their latent capabilities, resulting in substantial performance boosts across languages. Second, we introduce a new hybrid approach that synergizes LLM Retrieval Augmented Generation (RAG) with multilingual embeddings and achieves improved multilingual task performance. Finally, we introduce a novel learning approach that dynamically selects the optimal prompt strategy, LLM model, and embedding model per query at run-time. This dynamic adaptation maximizes the efficacy of LLMs across languages, outperforming best static and random strategies. Additionally, our approach adapts configurations in both offline and online settings, and can seamlessly adapt to new languages and datasets, leading to substantial advancements in multilingual understanding and generation across diverse languages.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024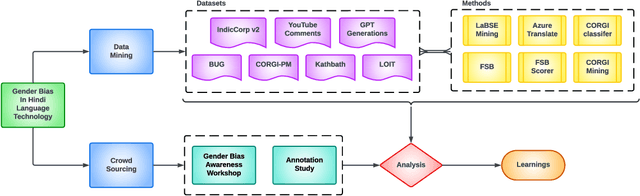

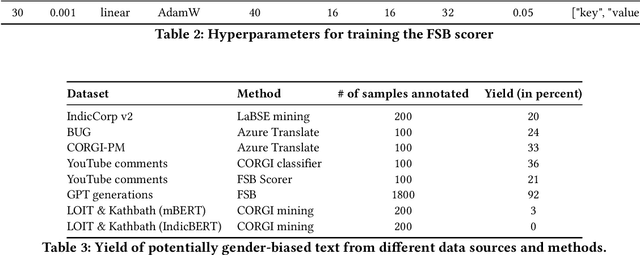
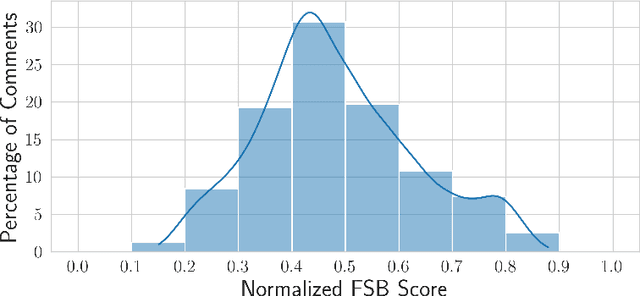
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
METAL: Towards Multilingual Meta-Evaluation
Apr 02, 2024



With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
MunTTS: A Text-to-Speech System for Mundari
Jan 28, 2024



We present MunTTS, an end-to-end text-to-speech (TTS) system specifically for Mundari, a low-resource Indian language of the Austo-Asiatic family. Our work addresses the gap in linguistic technology for underrepresented languages by collecting and processing data to build a speech synthesis system. We begin our study by gathering a substantial dataset of Mundari text and speech and train end-to-end speech models. We also delve into the methods used for training our models, ensuring they are efficient and effective despite the data constraints. We evaluate our system with native speakers and objective metrics, demonstrating its potential as a tool for preserving and promoting the Mundari language in the digital age.