 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Generation for Assessing Early Literacy Reading Comprehension
Jul 30, 2025

Assessment of reading comprehension through content-based interactions plays an important role in the reading acquisition process. In this paper, we propose a novel approach for generating comprehension questions geared to K-2 English learners. Our method ensures complete coverage of the underlying material and adaptation to the learner's specific proficiencies, and can generate a large diversity of question types at various difficulty levels to ensure a thorough evaluation. We evaluate the performance of various language models in this framework using the FairytaleQA dataset as the source material. Eventually, the proposed approach has the potential to become an important part of autonomous AI-driven English instructors.
PIPA: A Unified Evaluation Protocol for Diagnosing Interactive Planning Agents
May 02, 2025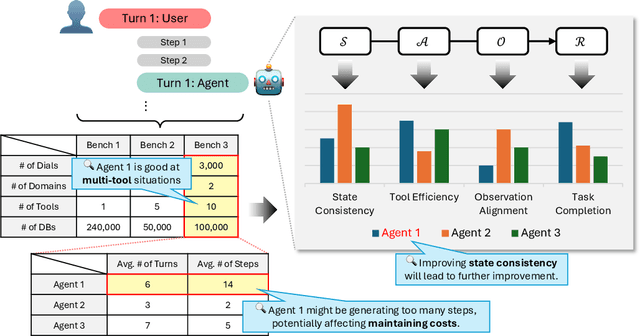

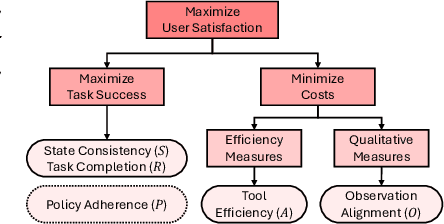

The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose PIPA, a unified evaluation protocol that conceptualizes the behavioral process of interactive task planning agents within a partially observable Markov Decision Process (POMDP) paradigm. The proposed protocol offers a comprehensive assessment of agent performance through a set of atomic evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.
Spark: A System for Scientifically Creative Idea Generation
Apr 25, 2025


Recently, large language models (LLMs) have shown promising abilities to generate novel research ideas in science, a direction which coincides with many foundational principles in computational creativity (CC). In light of these developments, we present an idea generation system named Spark that couples retrieval-augmented idea generation using LLMs with a reviewer model named Judge trained on 600K scientific reviews from OpenReview. Our work is both a system demonstration and intended to inspire other CC researchers to explore grounding the generation and evaluation of scientific ideas within foundational CC principles. To this end, we release the annotated dataset used to train Judge, inviting other researchers to explore the use of LLMs for idea generation and creative evaluations.
YourBench: Easy Custom Evaluation Sets for Everyone
Apr 02, 2025



Evaluating large language models (LLMs) effectively remains a critical bottleneck, as traditional static benchmarks suffer from saturation and contamination, while human evaluations are costly and slow. This hinders timely or domain-specific assessment, crucial for real-world applications. We introduce YourBench, a novel, open-source framework that addresses these limitations by enabling dynamic, automated generation of reliable, up-to-date, and domain-tailored benchmarks cheaply and without manual annotation, directly from user-provided documents. We demonstrate its efficacy by replicating 7 diverse MMLU subsets using minimal source text, achieving this for under 15 USD in total inference costs while perfectly preserving the relative model performance rankings (Spearman Rho = 1) observed on the original benchmark. To ensure that YourBench generates data grounded in provided input instead of relying on posterior parametric knowledge in models, we also introduce Tempora-0325, a novel dataset of over 7K diverse documents, published exclusively after March 2025. Our comprehensive analysis spans 26 SoTA models from 7 major families across varying scales (3-671B parameters) to validate the quality of generated evaluations through rigorous algorithmic checks (e.g., citation grounding) and human assessments. We release the YourBench library, the Tempora-0325 dataset, 150k+ question answer pairs based on Tempora and all evaluation and inference traces to facilitate reproducible research and empower the community to generate bespoke benchmarks on demand, fostering more relevant and trustworthy LLM evaluation.
Democratizing LLMs: An Exploration of Cost-Performance Trade-offs in Self-Refined Open-Source Models
Oct 22, 2023



The dominance of proprietary LLMs has led to restricted access and raised information privacy concerns. High-performing open-source alternatives are crucial for information-sensitive and high-volume applications but often lag behind in performance. To address this gap, we propose (1) A untargeted variant of iterative self-critique and self-refinement devoid of external influence. (2) A novel ranking metric - Performance, Refinement, and Inference Cost Score (PeRFICS) - to find the optimal model for a given task considering refined performance and cost. Our experiments show that SoTA open source models of varying sizes from 7B - 65B, on average, improve 8.2% from their baseline performance. Strikingly, even models with extremely small memory footprints, such as Vicuna-7B, show a 11.74% improvement overall and up to a 25.39% improvement in high-creativity, open ended tasks on the Vicuna benchmark. Vicuna-13B takes it a step further and outperforms ChatGPT post-refinement. This work has profound implications for resource-constrained and information-sensitive environments seeking to leverage LLMs without incurring prohibitive costs, compromising on performance and privacy. The domain-agnostic self-refinement process coupled with our novel ranking metric facilitates informed decision-making in model selection, thereby reducing costs and democratizing access to high-performing language models, as evidenced by case studies.