 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRain Removal from Light Field Images with 4D Convolution and Multi-scale Gaussian Process
Aug 16, 2022



Existing deraining methods mainly focus on a single input image. With just a single input image, it is extremely difficult to accurately detect rain streaks, remove rain streaks, and restore rain-free images. Compared with a single 2D image, a light field image (LFI) embeds abundant 3D structure and texture information of the target scene by recording the direction and position of each incident ray via a plenoptic camera, which has emerged as a popular device in the computer vision and graphics research communities. In this paper, we propose a novel network, 4D-MGP-SRRNet, for rain streak removal from an LFI. Our method takes as input all sub-views of a rainy LFI. In order to make full use of the LFI, we adopt 4D convolutional layers to build the proposed rain steak removal network to simultaneously process all sub-views of the LFI. In the proposed network, the rain detection model, MGPDNet, with a novel Multi-scale Self-guided Gaussian Process (MSGP) module is proposed to detect rain streaks from all sub-views of the input LFI. Semi-supervised learning is introduced to accurately detect rain streaks by training on both virtual-world rainy LFIs and real-world rainy LFIs at multiple scales via calculating pseudo ground truth for real-world rain streaks. All sub-views subtracting the predicted rain streaks are then fed into a 4D residual model to estimate depth maps. Finally, all sub-views concatenated with the corresponding rain streaks and fog maps converted from the estimated depth maps are fed into a rainy LFI restoring model that is based on the adversarial recurrent neural network to progressively eliminate rain streaks and recover the rain-free LFI. Extensive quantitative and qualitative evaluations conducted on both synthetic LFIs and real-world LFIs demonstrate the effectiveness of our proposed method.
Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jul 28, 2022
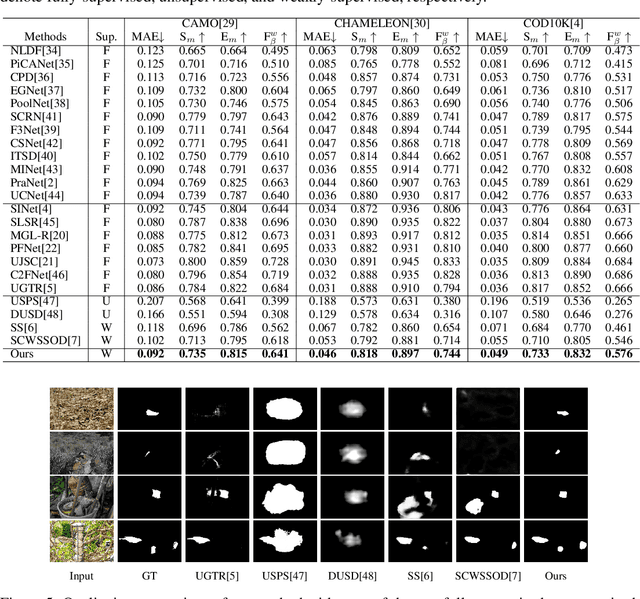
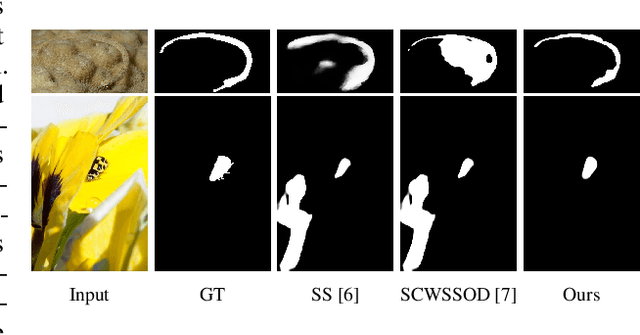
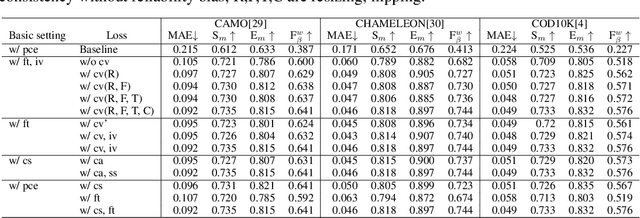
Existing camouflaged object detection (COD) methods rely heavily on large-scale datasets with pixel-wise annotations. However, due to the ambiguous boundary, it is very time-consuming and labor-intensive to annotate camouflage objects pixel-wisely (which takes ~ 60 minutes per image). In this paper, we propose the first weakly-supervised camouflaged object detection (COD) method, using scribble annotations as supervision. To achieve this, we first construct a scribble-based camouflaged object dataset with 4,040 images and corresponding scribble annotations. It is worth noting that annotating the scribbles used in our dataset takes only ~ 10 seconds per image, which is 360 times faster than per-pixel annotations. However, the network directly using scribble annotations for supervision will fail to localize the boundary of camouflaged objects and tend to have inconsistent predictions since scribble annotations only describe the primary structure of objects without details. To tackle this problem, we propose a novel consistency loss composed of two parts: a reliable cross-view loss to attain reliable consistency over different images, and a soft inside-view loss to maintain consistency inside a single prediction map. Besides, we observe that humans use semantic information to segment regions near boundaries of camouflaged objects. Therefore, we design a feature-guided loss, which includes visual features directly extracted from images and semantically significant features captured by models. Moreover, we propose a novel network that detects camouflaged objects by scribble learning on structural information and semantic relations. Experimental results show that our model outperforms relevant state-of-the-art methods on three COD benchmarks with an average improvement of 11.0% on MAE, 3.2% on S-measure, 2.5% on E-measure and 4.4% on weighted F-measure.
Symmetry-Aware Transformer-based Mirror Detection
Jul 13, 2022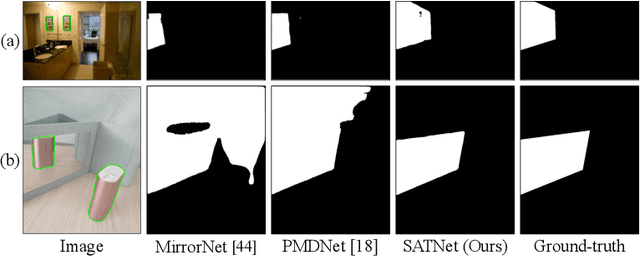
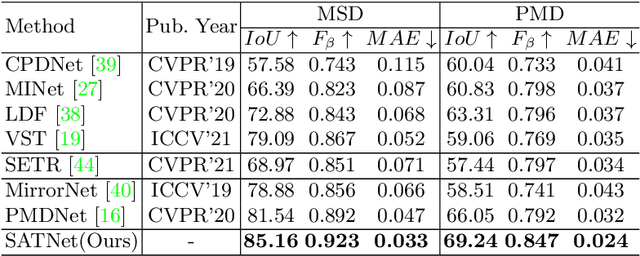
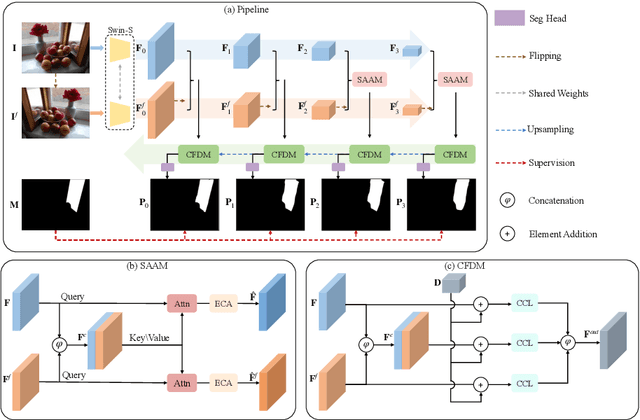
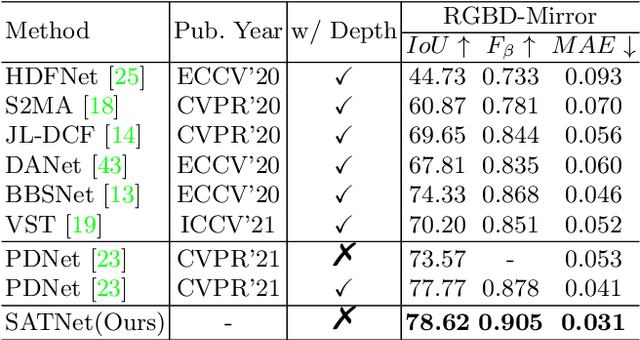
Mirror detection aims to identify the mirror regions in the given input image. Existing works mainly focus on integrating the semantic features and structural features to mine the similarity and discontinuity between mirror and non-mirror regions, or introducing depth information to help analyze the existence of mirrors. In this work, we observe that a real object typically forms a loose symmetry relationship with its corresponding reflection in the mirror, which is beneficial in distinguishing mirrors from real objects. Based on this observation, we propose a dual-path Symmetry-Aware Transformer-based mirror detection Network (SATNet), which includes two novel modules: Symmetry-Aware Attention Module (SAAM) and Contrast and Fusion Decoder Module (CFDM). Specifically, we first introduce the transformer backbone to model global information aggregation in images, extracting multi-scale features in two paths. We then feed the high-level dual-path features to SAAMs to capture the symmetry relations. Finally, we fuse the dual-path features and refine our prediction maps progressively with CFDMs to obtain the final mirror mask. Experimental results show that SATNet outperforms both RGB and RGB-D mirror detection methods on all available mirror detection datasets.
Harmonizer: Learning to Perform White-Box Image and Video Harmonization
Jul 04, 2022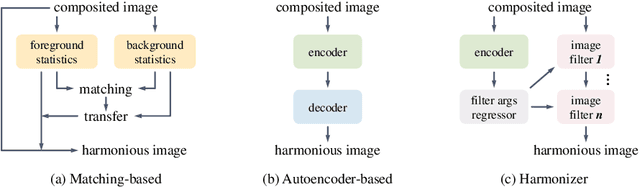
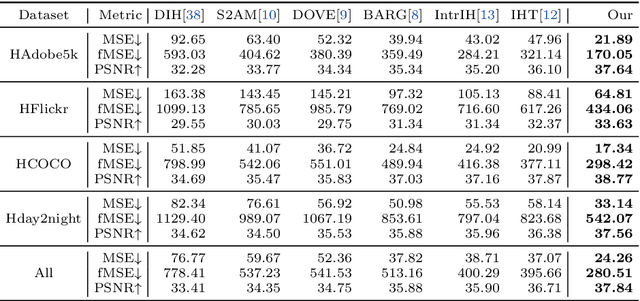
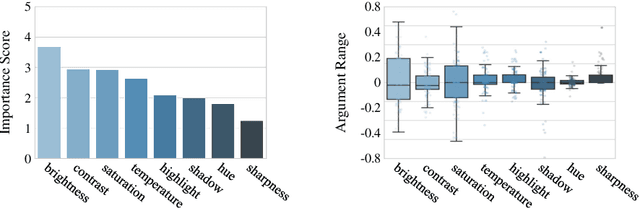
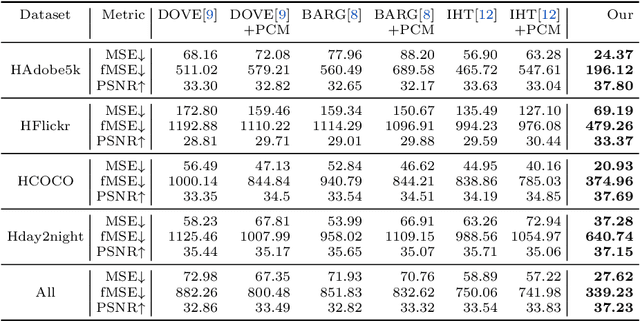
Recent works on image harmonization solve the problem as a pixel-wise image translation task via large autoencoders. They have unsatisfactory performances and slow inference speeds when dealing with high-resolution images. In this work, we observe that adjusting the input arguments of basic image filters, e.g., brightness and contrast, is sufficient for humans to produce realistic images from the composite ones. Hence, we frame image harmonization as an image-level regression problem to learn the arguments of the filters that humans use for the task. We present a Harmonizer framework for image harmonization. Unlike prior methods that are based on black-box autoencoders, Harmonizer contains a neural network for filter argument prediction and several white-box filters (based on the predicted arguments) for image harmonization. We also introduce a cascade regressor and a dynamic loss strategy for Harmonizer to learn filter arguments more stably and precisely. Since our network only outputs image-level arguments and the filters we used are efficient, Harmonizer is much lighter and faster than existing methods. Comprehensive experiments demonstrate that Harmonizer surpasses existing methods notably, especially with high-resolution inputs. Finally, we apply Harmonizer to video harmonization, which achieves consistent results across frames and 56 fps at 1080P resolution. Code and models are available at: https://github.com/ZHKKKe/Harmonizer.
Depth-aware Glass Surface Detection with Cross-modal Context Mining
Jun 22, 2022
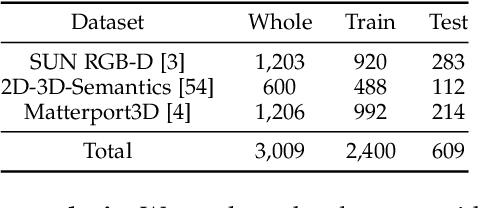

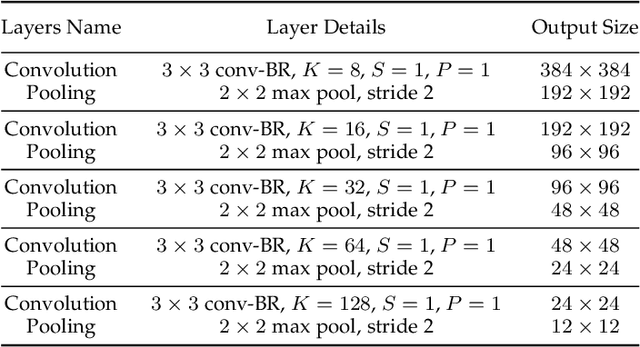
Glass surfaces are becoming increasingly ubiquitous as modern buildings tend to use a lot of glass panels. This however poses substantial challenges on the operations of autonomous systems such as robots, self-driving cars and drones, as the glass panels can become transparent obstacles to the navigation.Existing works attempt to exploit various cues, including glass boundary context or reflections, as a prior. However, they are all based on input RGB images.We observe that the transmission of 3D depth sensor light through glass surfaces often produces blank regions in the depth maps, which can offer additional insights to complement the RGB image features for glass surface detection. In this paper, we propose a novel framework for glass surface detection by incorporating RGB-D information, with two novel modules: (1) a cross-modal context mining (CCM) module to adaptively learn individual and mutual context features from RGB and depth information, and (2) a depth-missing aware attention (DAA) module to explicitly exploit spatial locations where missing depths occur to help detect the presence of glass surfaces. In addition, we propose a large-scale RGB-D glass surface detection dataset, called \textit{RGB-D GSD}, for RGB-D glass surface detection. Our dataset comprises 3,009 real-world RGB-D glass surface images with precise annotations. Extensive experimental results show that our proposed model outperforms state-of-the-art methods.
Rethinking Video Salient Object Ranking
Mar 31, 2022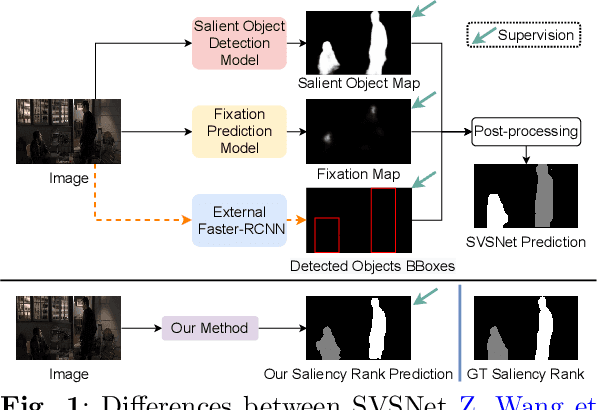


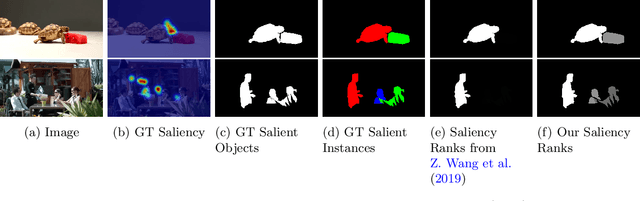
Salient Object Ranking (SOR) involves ranking the degree of saliency of multiple salient objects in an input image. Most recently, a method is proposed for ranking salient objects in an input video based on a predicted fixation map. It relies solely on the density of the fixations within the salient objects to infer their saliency ranks, which is incompatible with human perception of saliency ranking. In this work, we propose to explicitly learn the spatial and temporal relations between different salient objects to produce the saliency ranks. To this end, we propose an end-to-end method for video salient object ranking (VSOR), with two novel modules: an intra-frame adaptive relation (IAR) module to learn the spatial relation among the salient objects in the same frame locally and globally, and an inter-frame dynamic relation (IDR) module to model the temporal relation of saliency across different frames. In addition, to address the limited video types (just sports and movies) and scene diversity in the existing VSOR dataset, we propose a new dataset that covers different video types and diverse scenes on a large scale. Experimental results demonstrate that our method outperforms state-of-the-art methods in relevant fields. We will make the source code and our proposed dataset available.
Bi-directional Object-context Prioritization Learning for Saliency Ranking
Mar 22, 2022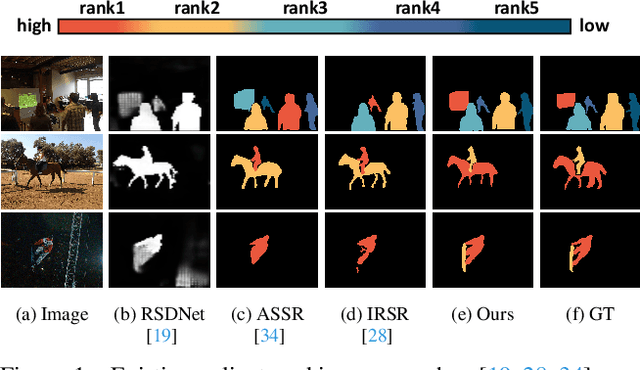
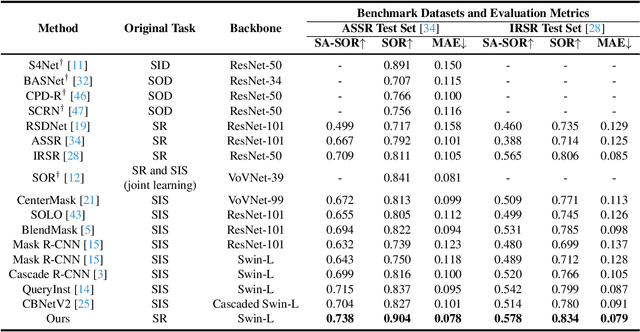

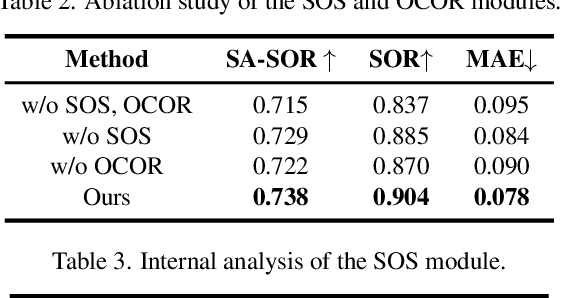
The saliency ranking task is recently proposed to study the visual behavior that humans would typically shift their attention over different objects of a scene based on their degrees of saliency. Existing approaches focus on learning either object-object or object-scene relations. Such a strategy follows the idea of object-based attention in Psychology, but it tends to favor those objects with strong semantics (e.g., humans), resulting in unrealistic saliency ranking. We observe that spatial attention works concurrently with object-based attention in the human visual recognition system. During the recognition process, the human spatial attention mechanism would move, engage, and disengage from region to region (i.e., context to context). This inspires us to model the region-level interactions, in addition to the object-level reasoning, for saliency ranking. To this end, we propose a novel bi-directional method to unify spatial attention and object-based attention for saliency ranking. Our model includes two novel modules: (1) a selective object saliency (SOS) module that models objectbased attention via inferring the semantic representation of the salient object, and (2) an object-context-object relation (OCOR) module that allocates saliency ranks to objects by jointly modeling the object-context and context-object interactions of the salient objects. Extensive experiments show that our approach outperforms existing state-of-theart methods. Our code and pretrained model are available at https://github.com/GrassBro/OCOR.
Total Scale: Face-to-Body Detail Reconstruction from Sparse RGBD Sensors
Dec 03, 2021
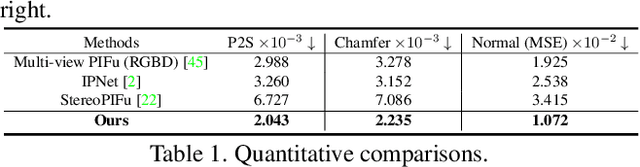
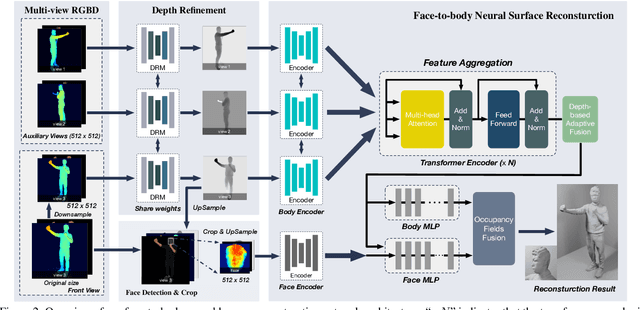
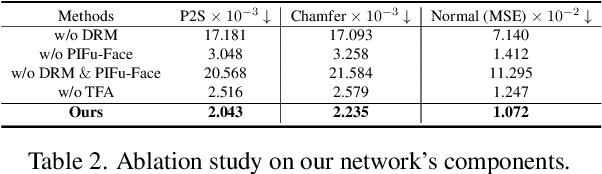
While the 3D human reconstruction methods using Pixel-aligned implicit function (PIFu) develop fast, we observe that the quality of reconstructed details is still not satisfactory. Flat facial surfaces frequently occur in the PIFu-based reconstruction results. To this end, we propose a two-scale PIFu representation to enhance the quality of the reconstructed facial details. Specifically, we utilize two MLPs to separately represent the PIFus for the face and human body. An MLP dedicated to the reconstruction of 3D faces can increase the network capacity and reduce the difficulty of the reconstruction of facial details as in the previous one-scale PIFu representation. To remedy the topology error, we leverage 3 RGBD sensors to capture multiview RGBD data as the input to the network, a sparse, lightweight capture setting. Since the depth noise severely influences the reconstruction results, we design a depth refinement module to reduce the noise of the raw depths under the guidance of the input RGB images. We also propose an adaptive fusion scheme to fuse the predicted occupancy field of the body and face to eliminate the discontinuity artifact at their boundaries. Experiments demonstrate the effectiveness of our approach in reconstructing vivid facial details and deforming body shapes, and verify its superiority over state-of-the-art methods.
Learning to Detect Instance-level Salient Objects Using Complementary Image Labels
Nov 19, 2021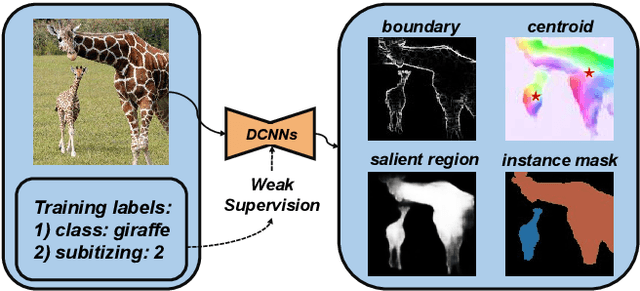
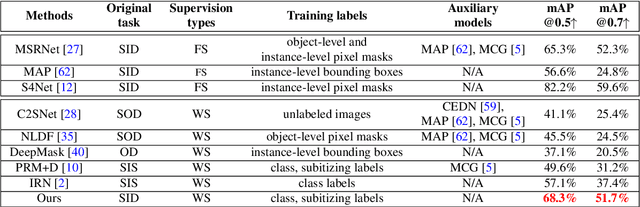
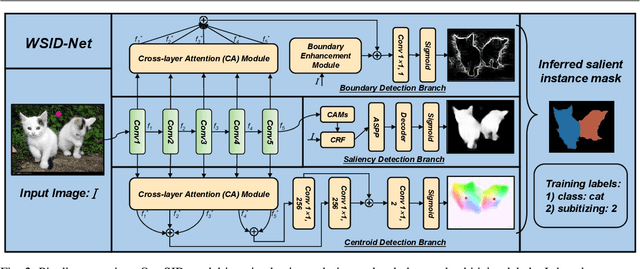
Existing salient instance detection (SID) methods typically learn from pixel-level annotated datasets. In this paper, we present the first weakly-supervised approach to the SID problem. Although weak supervision has been considered in general saliency detection, it is mainly based on using class labels for object localization. However, it is non-trivial to use only class labels to learn instance-aware saliency information, as salient instances with high semantic affinities may not be easily separated by the labels. As the subitizing information provides an instant judgement on the number of salient items, it is naturally related to detecting salient instances and may help separate instances of the same class while grouping different parts of the same instance. Inspired by this observation, we propose to use class and subitizing labels as weak supervision for the SID problem. We propose a novel weakly-supervised network with three branches: a Saliency Detection Branch leveraging class consistency information to locate candidate objects; a Boundary Detection Branch exploiting class discrepancy information to delineate object boundaries; and a Centroid Detection Branch using subitizing information to detect salient instance centroids. This complementary information is then fused to produce a salient instance map. To facilitate the learning process, we further propose a progressive training scheme to reduce label noise and the corresponding noise learned by the model, via reciprocating the model with progressive salient instance prediction and model refreshing. Our extensive evaluations show that the proposed method plays favorably against carefully designed baseline methods adapted from related tasks.
MODNet-V: Improving Portrait Video Matting via Background Restoration
Sep 24, 2021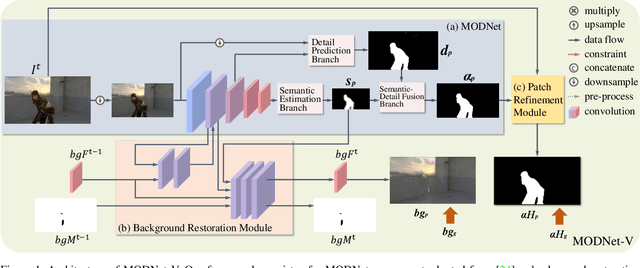

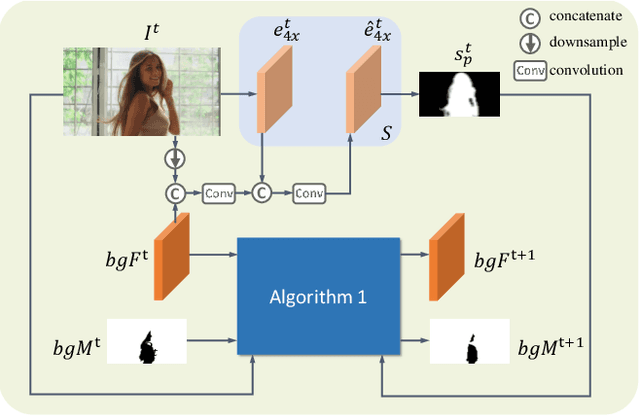
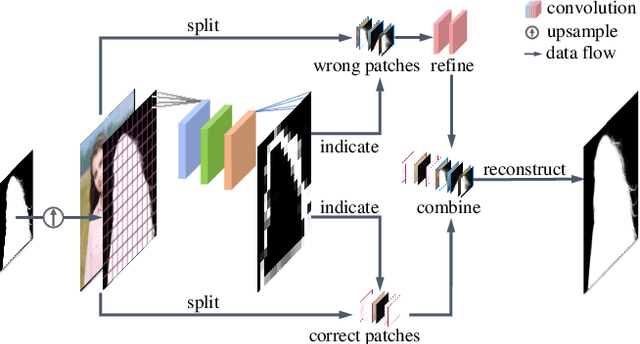
To address the challenging portrait video matting problem more precisely, existing works typically apply some matting priors that require additional user efforts to obtain, such as annotated trimaps or background images. In this work, we observe that instead of asking the user to explicitly provide a background image, we may recover it from the input video itself. To this end, we first propose a novel background restoration module (BRM) to recover the background image dynamically from the input video. BRM is extremely lightweight and can be easily integrated into existing matting models. By combining BRM with a recent image matting model, MODNet, we then present MODNet-V for portrait video matting. Benefited from the strong background prior provided by BRM, MODNet-V has only 1/3 of the parameters of MODNet but achieves comparable or even better performances. Our design allows MODNet-V to be trained in an end-to-end manner on a single NVIDIA 3090 GPU. Finally, we introduce a new patch refinement module (PRM) to adapt MODNet-V for high-resolution videos while keeping MODNet-V lightweight and fast.