 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: A Unified Agentic Harness for MLLMs
Jun 02, 2026Despite rapid progress, multimodal large language models (MLLMs) still fail on tasks that humans solve effortlessly, such as navigating a grid maze from a screenshot or selecting the correct puzzle piece. Rather than retraining the model, we ask a complementary question: how much capability can be elicited from a frozen MLLM purely by improving the execution scaffold around it? We introduce MUSE, a multimodal unified structured execution harness that wraps any off-the-shelf MLLM with composable modules for task representation, visual processing, perception tool use, structured parsing, deterministic verification, and verifier-guided repair, without any model retraining. We evaluate MUSE across diverse benchmarks spanning visual spatial planning, visual perception, multimodal reasoning, and fine-grained visual discrimination, using multiple state-of-the-art MLLMs. MUSE delivers consistent gains over the bare model in all settings, with the largest jumps on challenging instances. Further analysis reveals that many MLLM failures arise from harness-level shortcomings rather than fundamental model deficits, and can be addressed through verifier-guided repair without touching the model. These findings highlight the agentic multimodal harness as a critical yet underexplored design dimension, offering an orthogonal avenue for improving MLLMs beyond model-centric optimization.
Hierarchical Visual Agent: Managing Contexts in Joint Image-Text Space for Advanced Chart Reasoning
May 05, 2026Advanced chart question answering requires both precise perception of small visual elements and multi-step reasoning across several subplots. While existing MLLMs are strong at understanding single plots, they often struggle with multi-step reasoning across multiple subplots. We propose HierVA, a hierarchical visual agent framework for chart reasoning that iteratively constructs and updates a working context in a joint image--text space. A high-level manager generates plans and maintains a compact context containing only key information, while specialized workers perform reasoning, gather evidence, and return results. In particular, the agent maintains separate visual and textual contexts, using a zoom-in tool to restrict the visual context. Experiments on the CharXiv reasoning subset demonstrate consistent improvements over strong multimodal baselines, and ablation studies verify that hierarchical architecture, scoped visual context, and distilled context contribute complementary gains.
Visual Reasoning through Tool-supervised Reinforcement Learning
Apr 21, 2026In this paper, we investigate the problem of how to effectively master tool-use to solve complex visual reasoning tasks for Multimodal Large Language Models. To achieve that, we propose a novel Tool-supervised Reinforcement Learning (ToolsRL) framework, with direct tool supervision for more effective tool-use learning. We focus on a series of simple, native, and interpretable visual tools, including zoom-in, rotate, flip, and draw point/line, whose tool supervision is easy to collect. A reinforcement learning curriculum is developed, where the first stage is solely optimized by a set of well motivated tool-specific rewards, and the second stage is trained with the accuracy targeted rewards while allowing calling tools. In this way, tool calling capability is mastered before using tools to complete visual reasoning tasks, avoiding the potential optimization conflict among those heterogeneous tasks. Our experiments have shown that the tool-supervised curriculum training is efficient and ToolsRL can achieve strong tool-use capabilities for complex visual reasoning tasks.
Beyond Referring Expressions: Scenario Comprehension Visual Grounding
Apr 02, 2026Existing visual grounding benchmarks primarily evaluate alignment between image regions and literal referring expressions, where models can often succeed by matching a prominent named category. We explore a complementary and more challenging setting of scenario-based visual grounding, where the target must be inferred from roles, intentions, and relational context rather than explicit naming. We introduce Referring Scenario Comprehension (RSC), a benchmark designed for this setting. The queries in this benchmark are paragraph-length texts that describe object roles, user goals, and contextual cues, including deliberate references to distractor objects that often require deep understanding to resolve. Each instance is annotated with interpretable difficulty tags for uniqueness, clutter, size, overlap, and position which expose distinct failure modes and support fine-grained analysis. RSC contains approximately 31k training examples, 4k in-domain test examples, and a 3k out-of-distribution split with unseen object categories. We further propose ScenGround, a curriculum reasoning method serving as a reference point for this setting, combining supervised warm-starting with difficulty-aware reinforcement learning. Experiments show that scenario-based queries expose systematic failures in current models that standard benchmarks do not reveal, and that curriculum training improves performance on challenging slices and transfers to standard benchmarks.
Ref-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
Feb 27, 2026Referring Expression Comprehension (REC) links language to region level visual perception. Standard benchmarks (RefCOCO, RefCOCO+, RefCOCOg) have progressed rapidly with multimodal LLMs but remain weak tests of visual reasoning and grounding: (i) many expressions are very short, leaving little reasoning demand; (ii) images often contain few distractors, making the target easy to find; and (iii) redundant descriptors enable shortcut solutions that bypass genuine text understanding and visual reasoning. We introduce Ref-Adv, a modern REC benchmark that suppresses shortcuts by pairing linguistically nontrivial expressions with only the information necessary to uniquely identify the target. The dataset contains referring expressions on real images, curated with hard distractors and annotated with reasoning facets including negation. We conduct comprehensive ablations (word order perturbations and descriptor deletion sufficiency) to show that solving Ref-Adv requires reasoning beyond simple cues, and we evaluate a broad suite of contemporary multimodal LLMs on Ref-Adv. Despite strong results on RefCOCO, RefCOCO+, and RefCOCOg, models drop markedly on Ref-Adv, revealing reliance on shortcuts and gaps in visual reasoning and grounding. We provide an in depth failure analysis and aim for Ref-Adv to guide future work on visual reasoning and grounding in MLLMs.
Fine-T2I: An Open, Large-Scale, and Diverse Dataset for High-Quality T2I Fine-Tuning
Feb 10, 2026High-quality and open datasets remain a major bottleneck for text-to-image (T2I) fine-tuning. Despite rapid progress in model architectures and training pipelines, most publicly available fine-tuning datasets suffer from low resolution, poor text-image alignment, or limited diversity, resulting in a clear performance gap between open research models and enterprise-grade models. In this work, we present Fine-T2I, a large-scale, high-quality, and fully open dataset for T2I fine-tuning. Fine-T2I spans 10 task combinations, 32 prompt categories, 11 visual styles, and 5 prompt templates, and combines synthetic images generated by strong modern models with carefully curated real images from professional photographers. All samples are rigorously filtered for text-image alignment, visual fidelity, and prompt quality, with over 95% of initial candidates removed. The final dataset contains over 6 million text-image pairs, around 2 TB on disk, approaching the scale of pretraining datasets while maintaining fine-tuning-level quality. Across a diverse set of pretrained diffusion and autoregressive models, fine-tuning on Fine-T2I consistently improves both generation quality and instruction adherence, as validated by human evaluation, visual comparison, and automatic metrics. We release Fine-T2I under an open license to help close the data gap in T2I fine-tuning in the open community.
Boosting Large Language Models with Mask Fine-Tuning
Mar 27, 2025The model is usually kept integral in the mainstream large language model (LLM) fine-tuning protocols. No works have questioned whether maintaining the integrity of the model is indispensable for performance. In this work, we introduce Mask Fine-Tuning (MFT), a brand-new LLM fine-tuning paradigm to show that properly breaking the integrity of the model can surprisingly lead to improved performance. Specifically, MFT learns a set of binary masks supervised by the typical LLM fine-tuning objective. Extensive experiments show that MFT gains a consistent performance boost across various domains and backbones (e.g., 1.95%/1.88% average gain in coding with LLaMA2-7B/3.1-8B). Detailed procedures are provided to study the proposed MFT from different hyperparameter perspectives for better insight. In particular, MFT naturally updates the current LLM training protocol by deploying it on a complete well-trained model. This study extends the functionality of mask learning from its conventional network pruning context for model compression to a more general scope.
Preserving Tumor Volumes for Unsupervised Medical Image Registration
Sep 18, 2023



Medical image registration is a critical task that estimates the spatial correspondence between pairs of images. However, current traditional and deep-learning-based methods rely on similarity measures to generate a deforming field, which often results in disproportionate volume changes in dissimilar regions, especially in tumor regions. These changes can significantly alter the tumor size and underlying anatomy, which limits the practical use of image registration in clinical diagnosis. To address this issue, we have formulated image registration with tumors as a constraint problem that preserves tumor volumes while maximizing image similarity in other normal regions. Our proposed strategy involves a two-stage process. In the first stage, we use similarity-based registration to identify potential tumor regions by their volume change, generating a soft tumor mask accordingly. In the second stage, we propose a volume-preserving registration with a novel adaptive volume-preserving loss that penalizes the change in size adaptively based on the masks calculated from the previous stage. Our approach balances image similarity and volume preservation in different regions, i.e., normal and tumor regions, by using soft tumor masks to adjust the imposition of volume-preserving loss on each one. This ensures that the tumor volume is preserved during the registration process. We have evaluated our strategy on various datasets and network architectures, demonstrating that our method successfully preserves the tumor volume while achieving comparable registration results with state-of-the-art methods. Our codes is available at: \url{https://dddraxxx.github.io/Volume-Preserving-Registration/}.
Weakly-Supervised 3D Medical Image Segmentation using Geometric Prior and Contrastive Similarity
Feb 04, 2023Medical image segmentation is almost the most important pre-processing procedure in computer-aided diagnosis but is also a very challenging task due to the complex shapes of segments and various artifacts caused by medical imaging, (i.e., low-contrast tissues, and non-homogenous textures). In this paper, we propose a simple yet effective segmentation framework that incorporates the geometric prior and contrastive similarity into the weakly-supervised segmentation framework in a loss-based fashion. The proposed geometric prior built on point cloud provides meticulous geometry to the weakly-supervised segmentation proposal, which serves as better supervision than the inherent property of the bounding-box annotation (i.e., height and width). Furthermore, we propose contrastive similarity to encourage organ pixels to gather around in the contrastive embedding space, which helps better distinguish low-contrast tissues. The proposed contrastive embedding space can make up for the poor representation of the conventionally-used gray space. Extensive experiments are conducted to verify the effectiveness and the robustness of the proposed weakly-supervised segmentation framework. The proposed framework is superior to state-of-the-art weakly-supervised methods on the following publicly accessible datasets: LiTS 2017 Challenge, KiTS 2021 Challenge, and LPBA40. We also dissect our method and evaluate the performance of each component.
Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jul 28, 2022
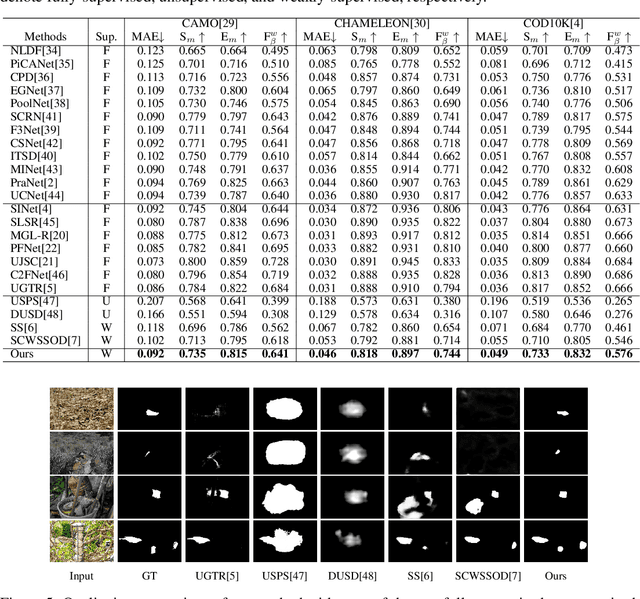
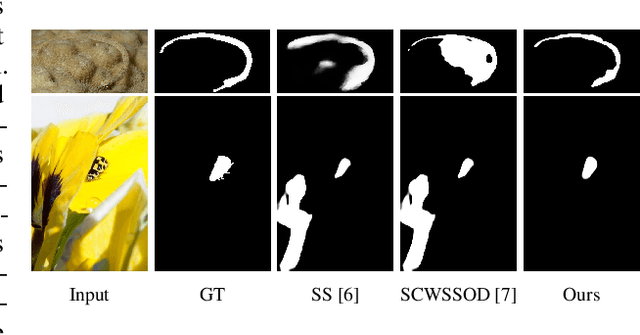
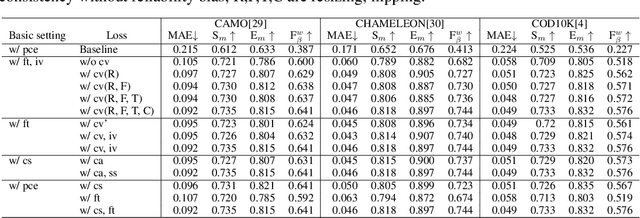
Existing camouflaged object detection (COD) methods rely heavily on large-scale datasets with pixel-wise annotations. However, due to the ambiguous boundary, it is very time-consuming and labor-intensive to annotate camouflage objects pixel-wisely (which takes ~ 60 minutes per image). In this paper, we propose the first weakly-supervised camouflaged object detection (COD) method, using scribble annotations as supervision. To achieve this, we first construct a scribble-based camouflaged object dataset with 4,040 images and corresponding scribble annotations. It is worth noting that annotating the scribbles used in our dataset takes only ~ 10 seconds per image, which is 360 times faster than per-pixel annotations. However, the network directly using scribble annotations for supervision will fail to localize the boundary of camouflaged objects and tend to have inconsistent predictions since scribble annotations only describe the primary structure of objects without details. To tackle this problem, we propose a novel consistency loss composed of two parts: a reliable cross-view loss to attain reliable consistency over different images, and a soft inside-view loss to maintain consistency inside a single prediction map. Besides, we observe that humans use semantic information to segment regions near boundaries of camouflaged objects. Therefore, we design a feature-guided loss, which includes visual features directly extracted from images and semantically significant features captured by models. Moreover, we propose a novel network that detects camouflaged objects by scribble learning on structural information and semantic relations. Experimental results show that our model outperforms relevant state-of-the-art methods on three COD benchmarks with an average improvement of 11.0% on MAE, 3.2% on S-measure, 2.5% on E-measure and 4.4% on weighted F-measure.