 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTServe: Efficient Serving for Generative Recommendation Models with Hierarchical Caches
Apr 24, 2026Generative recommendation (GR) offers superior modeling capabilities but suffers from prohibitive inference costs due to the repeated encoding of long user histories. While cross-request Key-Value (KV) cache reuse presents a significant optimization opportunity, the massive scale of individual user states creates a storage explosion that far exceeds physical GPU limits. We propose MTServe, a hierarchical cache management system that virtualizes GPU memory by leveraging host RAM as a scalable backup store. To bridge the I/O gap between tiers, MTServe introduces a suite of system-level optimizations, including a hybrid storage layout, an asynchronous data transfer pipeline, and a locality-driven replacement policy. On both public and production datasets, MTServe delivers up to 3.1* speedup while maintaining near-perfect hit ratios (>98.5%).
Pi-GPS: Enhancing Geometry Problem Solving by Unleashing the Power of Diagrammatic Information
Mar 07, 2025



Geometry problem solving has garnered increasing attention due to its potential applications in intelligent education field. Inspired by the observation that text often introduces ambiguities that diagrams can clarify, this paper presents Pi-GPS, a novel framework that unleashes the power of diagrammatic information to resolve textual ambiguities, an aspect largely overlooked in prior research. Specifically, we design a micro module comprising a rectifier and verifier: the rectifier employs MLLMs to disambiguate text based on the diagrammatic context, while the verifier ensures the rectified output adherence to geometric rules, mitigating model hallucinations. Additionally, we explore the impact of LLMs in theorem predictor based on the disambiguated formal language. Empirical results demonstrate that Pi-GPS surpasses state-of-the-art models, achieving a nearly 10\% improvement on Geometry3K over prior neural-symbolic approaches. We hope this work highlights the significance of resolving textual ambiguity in multimodal mathematical reasoning, a crucial factor limiting performance.
Spatial Semantic Recurrent Mining for Referring Image Segmentation
May 15, 2024Referring Image Segmentation (RIS) consistently requires language and appearance semantics to more understand each other. The need becomes acute especially under hard situations. To achieve, existing works tend to resort to various trans-representing mechanisms to directly feed forward language semantic along main RGB branch, which however will result in referent distribution weakly-mined in space and non-referent semantic contaminated along channel. In this paper, we propose Spatial Semantic Recurrent Mining (S\textsuperscript{2}RM) to achieve high-quality cross-modality fusion. It follows a working strategy of trilogy: distributing language feature, spatial semantic recurrent coparsing, and parsed-semantic balancing. During fusion, S\textsuperscript{2}RM will first generate a constraint-weak yet distribution-aware language feature, then bundle features of each row and column from rotated features of one modality context to recurrently correlate relevant semantic contained in feature from other modality context, and finally resort to self-distilled weights to weigh on the contributions of different parsed semantics. Via coparsing, S\textsuperscript{2}RM transports information from the near and remote slice layers of generator context to the current slice layer of parsed context, capable of better modeling global relationship bidirectional and structured. Besides, we also propose a Cross-scale Abstract Semantic Guided Decoder (CASG) to emphasize the foreground of the referent, finally integrating different grained features at a comparatively low cost. Extensive experimental results on four current challenging datasets show that our proposed method performs favorably against other state-of-the-art algorithms.
MODNet-V: Improving Portrait Video Matting via Background Restoration
Sep 24, 2021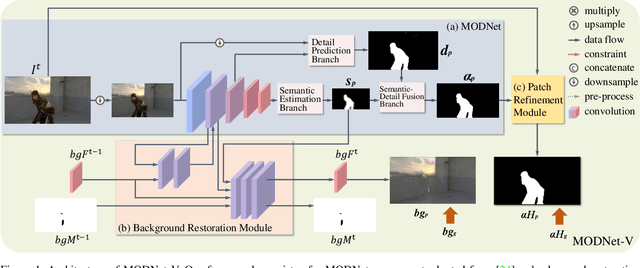

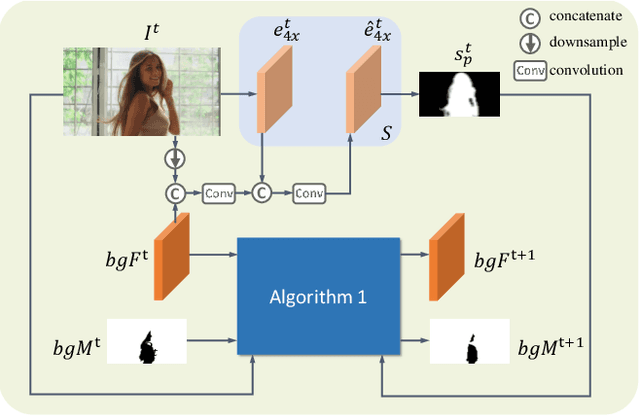
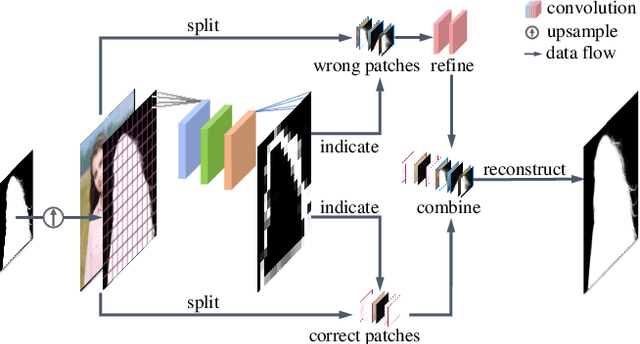
To address the challenging portrait video matting problem more precisely, existing works typically apply some matting priors that require additional user efforts to obtain, such as annotated trimaps or background images. In this work, we observe that instead of asking the user to explicitly provide a background image, we may recover it from the input video itself. To this end, we first propose a novel background restoration module (BRM) to recover the background image dynamically from the input video. BRM is extremely lightweight and can be easily integrated into existing matting models. By combining BRM with a recent image matting model, MODNet, we then present MODNet-V for portrait video matting. Benefited from the strong background prior provided by BRM, MODNet-V has only 1/3 of the parameters of MODNet but achieves comparable or even better performances. Our design allows MODNet-V to be trained in an end-to-end manner on a single NVIDIA 3090 GPU. Finally, we introduce a new patch refinement module (PRM) to adapt MODNet-V for high-resolution videos while keeping MODNet-V lightweight and fast.
RIDnet: Radiologist-Inspired Deep Neural Network for Low-dose CT Denoising
May 15, 2021
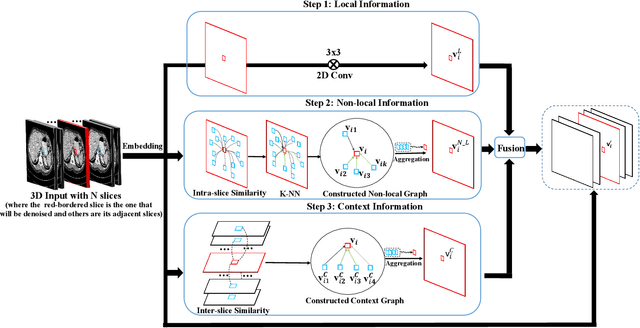

Being low-level radiation exposure and less harmful to health, low-dose computed tomography (LDCT) has been widely adopted in the early screening of lung cancer and COVID-19. LDCT images inevitably suffer from the degradation problem caused by complex noises. It was reported that, compared with commercial iterative reconstruction methods, deep learning (DL)-based LDCT denoising methods using convolutional neural network (CNN) achieved competitive performance. Most existing DL-based methods focus on the local information extracted by CNN, while ignoring both explicit non-local and context information (which are leveraged by radiologists). To address this issue, we propose a novel deep learning model named radiologist-inspired deep denoising network (RIDnet) to imitate the workflow of a radiologist reading LDCT images. Concretely, the proposed model explicitly integrates all the local, non-local and context information rather than local information only. Our radiologist-inspired model is potentially favoured by radiologists as a familiar workflow. A double-blind reader study on a public clinical dataset shows that, compared with state-of-the-art methods, our proposed model achieves the most impressive performance in terms of the structural fidelity, the noise suppression and the overall score. As a physicians-inspired model, RIDnet gives a new research roadmap that takes into account the behavior of physicians when designing decision support tools for assisting clinical diagnosis. Models and code are available at https://github.com/tonyckc/RIDnet_demo.
Lesion-Inspired Denoising Network: Connecting Medical Image Denoising and Lesion Detection
Apr 18, 2021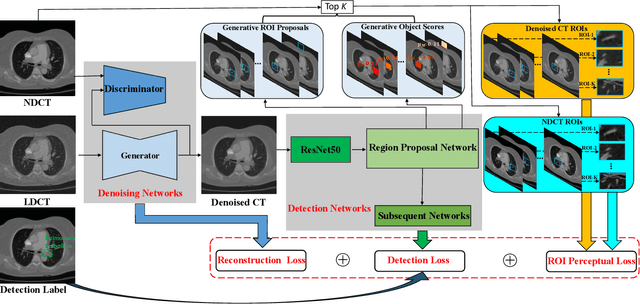
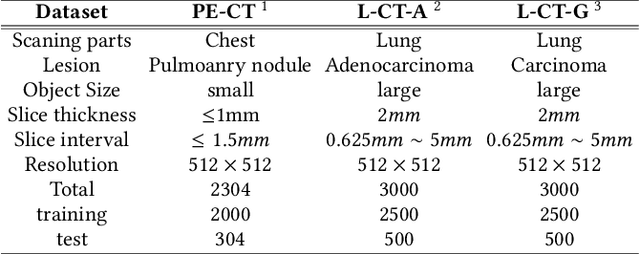

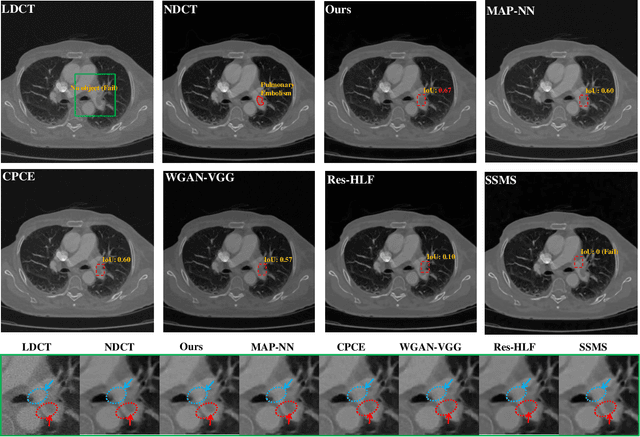
Deep learning has achieved notable performance in the denoising task of low-quality medical images and the detection task of lesions, respectively. However, existing low-quality medical image denoising approaches are disconnected from the detection task of lesions. Intuitively, the quality of denoised images will influence the lesion detection accuracy that in turn can be used to affect the denoising performance. To this end, we propose a play-and-plug medical image denoising framework, namely Lesion-Inspired Denoising Network (LIDnet), to collaboratively improve both denoising performance and detection accuracy of denoised medical images. Specifically, we propose to insert the feedback of downstream detection task into existing denoising framework by jointly learning a multi-loss objective. Instead of using perceptual loss calculated on the entire feature map, a novel region-of-interest (ROI) perceptual loss induced by the lesion detection task is proposed to further connect these two tasks. To achieve better optimization for overall framework, we propose a customized collaborative training strategy for LIDnet. On consideration of clinical usability and imaging characteristics, three low-dose CT images datasets are used to evaluate the effectiveness of the proposed LIDnet. Experiments show that, by equipping with LIDnet, both of the denoising and lesion detection performance of baseline methods can be significantly improved.