 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Adversarial Networks: Protecting Information against Adversarial Attacks
Oct 07, 2020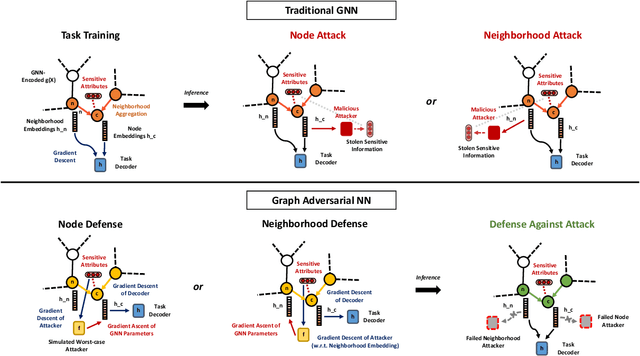
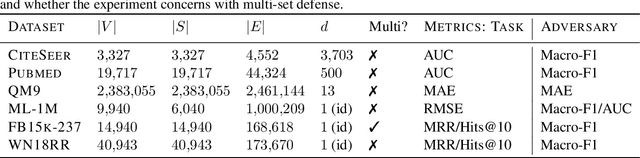
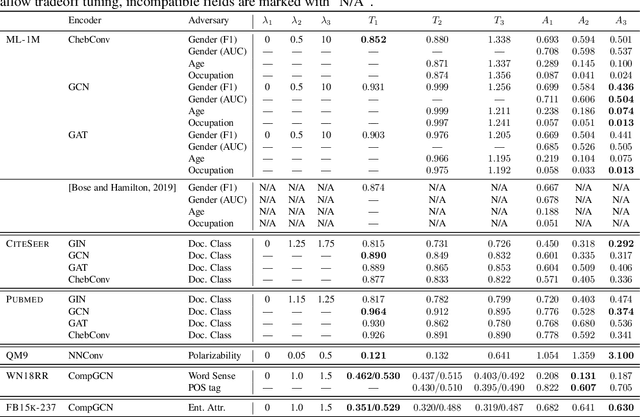
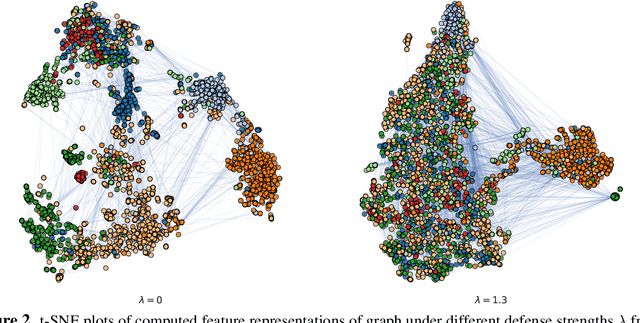
We study the problem of protecting information when learning with graph-structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering a small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders. Our code is available at https://github.com/liaopeiyuan/GAL.
Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function
Sep 08, 2020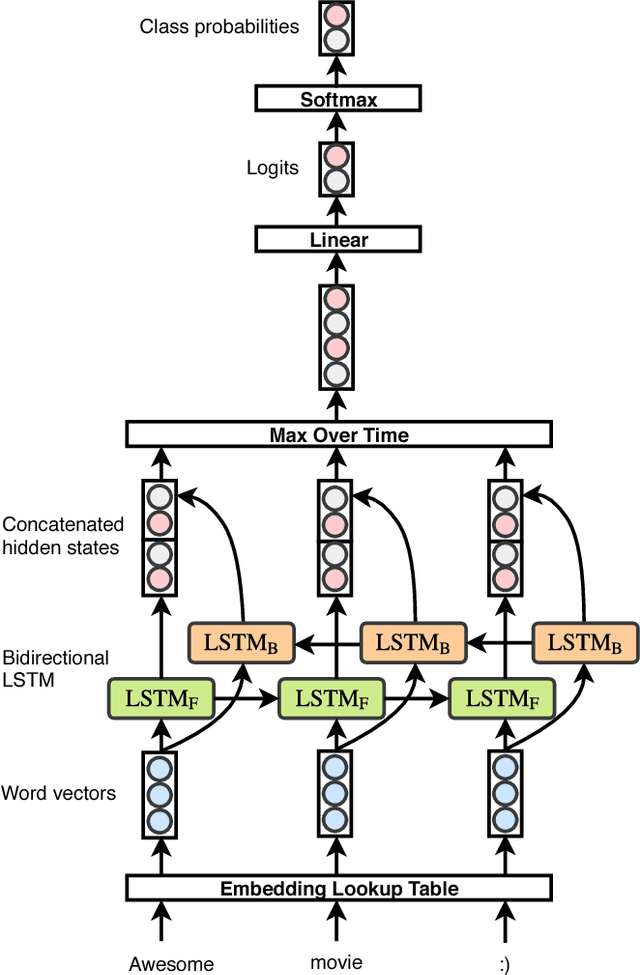
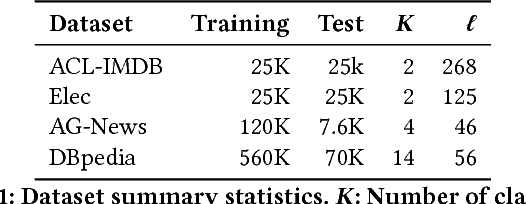
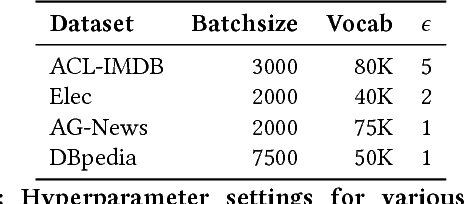
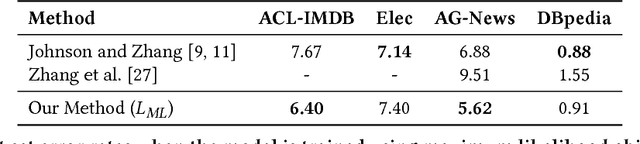
In this paper, we study bidirectional LSTM network for the task of text classification using both supervised and semi-supervised approaches. Several prior works have suggested that either complex pretraining schemes using unsupervised methods such as language modeling (Dai and Le 2015; Miyato, Dai, and Goodfellow 2016) or complicated models (Johnson and Zhang 2017) are necessary to achieve a high classification accuracy. However, we develop a training strategy that allows even a simple BiLSTM model, when trained with cross-entropy loss, to achieve competitive results compared with more complex approaches. Furthermore, in addition to cross-entropy loss, by using a combination of entropy minimization, adversarial, and virtual adversarial losses for both labeled and unlabeled data, we report state-of-the-art results for text classification task on several benchmark datasets. In particular, on the ACL-IMDB sentiment analysis and AG-News topic classification datasets, our method outperforms current approaches by a substantial margin. We also show the generality of the mixed objective function by improving the performance on relation extraction task.
Few-Shot Learning with Intra-Class Knowledge Transfer
Aug 22, 2020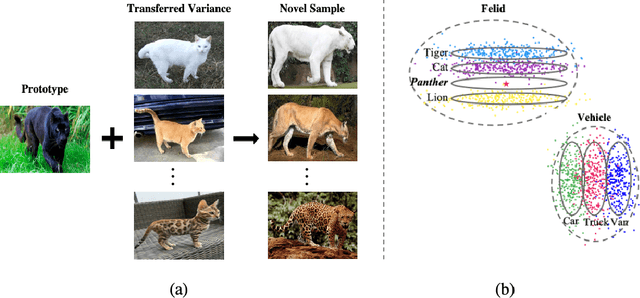
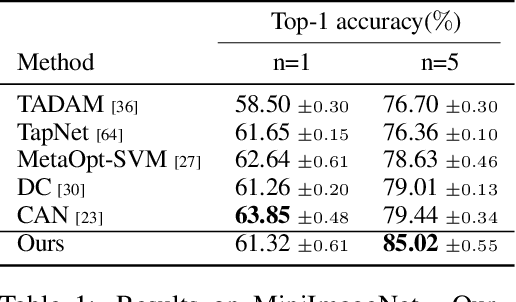
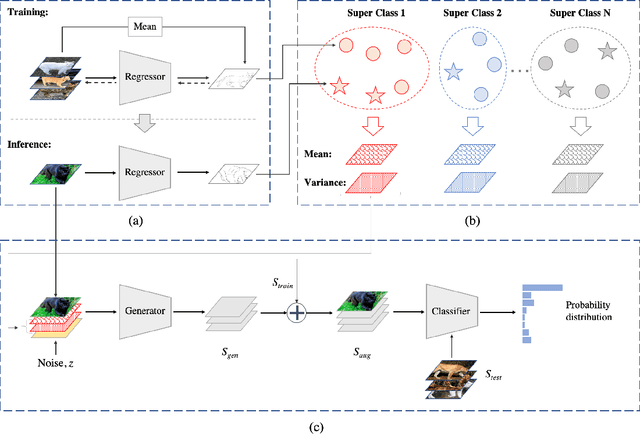
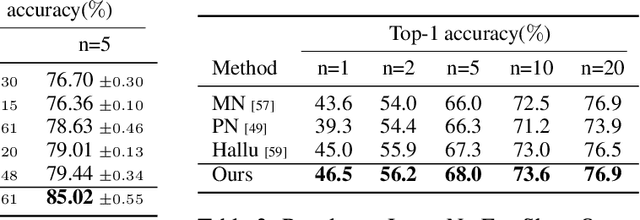
We consider the few-shot classification task with an unbalanced dataset, in which some classes have sufficient training samples while other classes only have limited training samples. Recent works have proposed to solve this task by augmenting the training data of the few-shot classes using generative models with the few-shot training samples as the seeds. However, due to the limited number of the few-shot seeds, the generated samples usually have small diversity, making it difficult to train a discriminative classifier for the few-shot classes. To enrich the diversity of the generated samples, we propose to leverage the intra-class knowledge from the neighbor many-shot classes with the intuition that neighbor classes share similar statistical information. Such intra-class information is obtained with a two-step mechanism. First, a regressor trained only on the many-shot classes is used to evaluate the few-shot class means from only a few samples. Second, superclasses are clustered, and the statistical mean and feature variance of each superclass are used as transferable knowledge inherited by the children few-shot classes. Such knowledge is then used by a generator to augment the sparse training data to help the downstream classification tasks. Extensive experiments show that our method achieves state-of-the-art across different datasets and $n$-shot settings.
Towards Debiasing Sentence Representations
Jul 16, 2020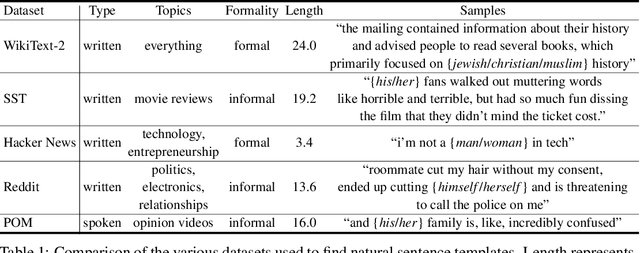
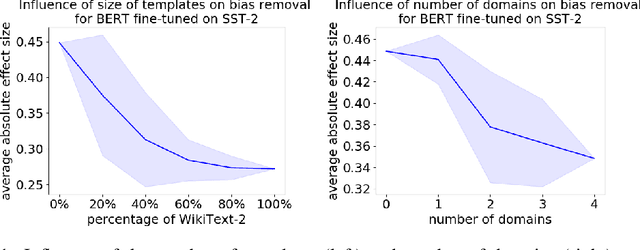

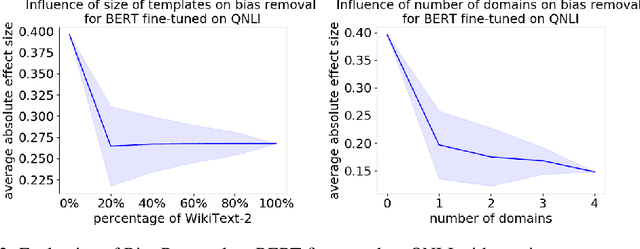
As natural language processing methods are increasingly deployed in real-world scenarios such as healthcare, legal systems, and social science, it becomes necessary to recognize the role they potentially play in shaping social biases and stereotypes. Previous work has revealed the presence of social biases in widely used word embeddings involving gender, race, religion, and other social constructs. While some methods were proposed to debias these word-level embeddings, there is a need to perform debiasing at the sentence-level given the recent shift towards new contextualized sentence representations such as ELMo and BERT. In this paper, we investigate the presence of social biases in sentence-level representations and propose a new method, Sent-Debias, to reduce these biases. We show that Sent-Debias is effective in removing biases, and at the same time, preserves performance on sentence-level downstream tasks such as sentiment analysis, linguistic acceptability, and natural language understanding. We hope that our work will inspire future research on characterizing and removing social biases from widely adopted sentence representations for fairer NLP.
Object Goal Navigation using Goal-Oriented Semantic Exploration
Jul 02, 2020
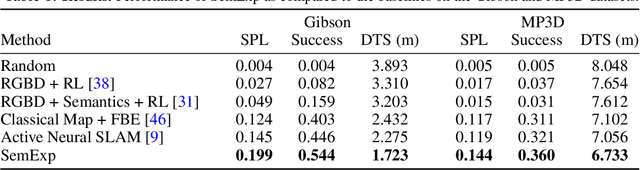
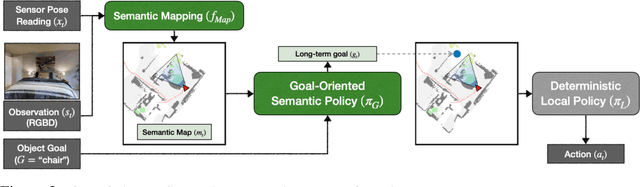

This work studies the problem of object goal navigation which involves navigating to an instance of the given object category in unseen environments. End-to-end learning-based navigation methods struggle at this task as they are ineffective at exploration and long-term planning. We propose a modular system called, `Goal-Oriented Semantic Exploration' which builds an episodic semantic map and uses it to explore the environment efficiently based on the goal object category. Empirical results in visually realistic simulation environments show that the proposed model outperforms a wide range of baselines including end-to-end learning-based methods as well as modular map-based methods and led to the winning entry of the CVPR-2020 Habitat ObjectNav Challenge. Ablation analysis indicates that the proposed model learns semantic priors of the relative arrangement of objects in a scene, and uses them to explore efficiently. Domain-agnostic module design allow us to transfer our model to a mobile robot platform and achieve similar performance for object goal navigation in the real-world.
Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers
Jun 24, 2020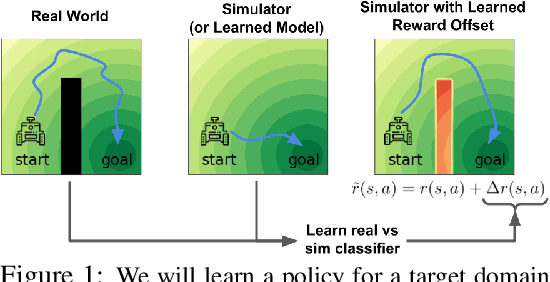
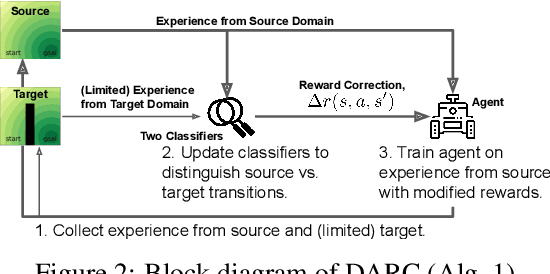
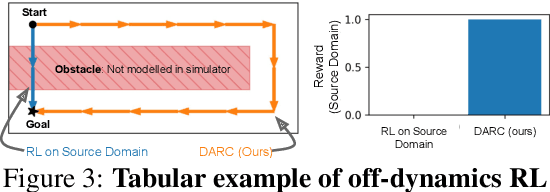
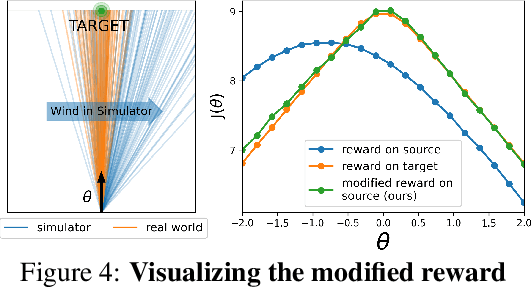
We propose a simple, practical, and intuitive approach for domain adaptation in reinforcement learning. Our approach stems from the idea that the agent's experience in the source domain should look similar to its experience in the target domain. Building off of a probabilistic view of RL, we formally show that we can achieve this goal by compensating for the difference in dynamics by modifying the reward function. This modified reward function is simple to estimate by learning auxiliary classifiers that distinguish source-domain transitions from target-domain transitions. Intuitively, the modified reward function penalizes the agent for visiting states and taking actions in the source domain which are not possible in the target domain. Said another way, the agent is penalized for transitions that would indicate that the agent is interacting with the source domain, rather than the target domain. Our approach is applicable to domains with continuous states and actions and does not require learning an explicit model of the dynamics. On discrete and continuous control tasks, we illustrate the mechanics of our approach and demonstrate its scalability to high-dimensional tasks.
On Reward-Free Reinforcement Learning with Linear Function Approximation
Jun 19, 2020
Reward-free reinforcement learning (RL) is a framework which is suitable for both the batch RL setting and the setting where there are many reward functions of interest. During the exploration phase, an agent collects samples without using a pre-specified reward function. After the exploration phase, a reward function is given, and the agent uses samples collected during the exploration phase to compute a near-optimal policy. Jin et al. [2020] showed that in the tabular setting, the agent only needs to collect polynomial number of samples (in terms of the number states, the number of actions, and the planning horizon) for reward-free RL. However, in practice, the number of states and actions can be large, and thus function approximation schemes are required for generalization. In this work, we give both positive and negative results for reward-free RL with linear function approximation. We give an algorithm for reward-free RL in the linear Markov decision process setting where both the transition and the reward admit linear representations. The sample complexity of our algorithm is polynomial in the feature dimension and the planning horizon, and is completely independent of the number of states and actions. We further give an exponential lower bound for reward-free RL in the setting where only the optimal $Q$-function admits a linear representation. Our results imply several interesting exponential separations on the sample complexity of reward-free RL.
Reinforcement Learning with General Value Function Approximation: Provably Efficient Approach via Bounded Eluder Dimension
Jun 19, 2020Value function approximation has demonstrated phenomenal empirical success in reinforcement learning (RL). Nevertheless, despite a handful of recent progress on developing theory for RL with linear function approximation, the understanding of general function approximation schemes largely remains missing. In this paper, we establish a provably efficient RL algorithm with general value function approximation. We show that if the value functions admit an approximation with a function class $\mathcal{F}$, our algorithm achieves a regret bound of $\widetilde{O}(\mathrm{poly}(dH)\sqrt{T})$ where $d$ is a complexity measure of $\mathcal{F}$ that depends on the eluder dimension [Russo and Van Roy, 2013] and log-covering numbers, $H$ is the planning horizon, and $T$ is the number interactions with the environment. Our theory generalizes recent progress on RL with linear value function approximation and does not make explicit assumptions on the model of the environment. Moreover, our algorithm is model-free and provides a framework to justify the effectiveness of algorithms used in practice.
Feature Robust Optimal Transport for High-dimensional Data
Jun 16, 2020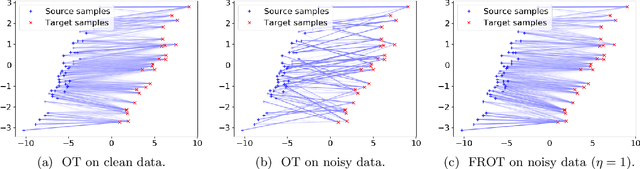

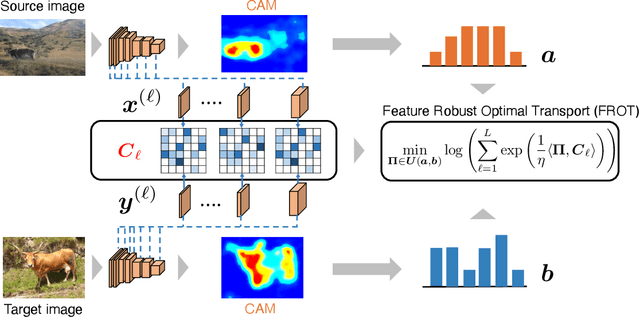
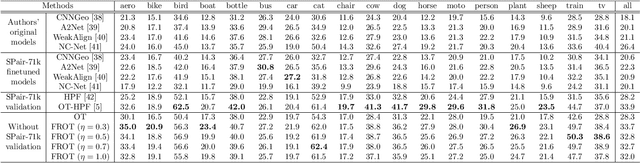
Optimal transport is a machine learning problem with applications including distribution comparison, feature selection, and generative adversarial networks. In this paper, we propose feature robust optimal transport (FROT) for high-dimensional data, which jointly solves feature selection and OT problems. Specifically, we formulate the FROT problem as a min--max optimization problem. Then, we propose a convex formulation of FROT and solve it with the Frank--Wolfe-based optimization algorithm, where the sub-problem can be efficiently solved using the Sinkhorn algorithm. A key advantage of FROT is that important features can be analytically determined by simply solving the convex optimization problem. Furthermore, we propose using the FROT algorithm for the layer selection problem in deep neural networks for semantic correspondence. By conducting synthetic and benchmark experiments, we demonstrate that the proposed method can determine important features. Additionally, we show that the FROT algorithm achieves a state-of-the-art performance in real-world semantic correspondence datasets.
Neural Methods for Point-wise Dependency Estimation
Jun 11, 2020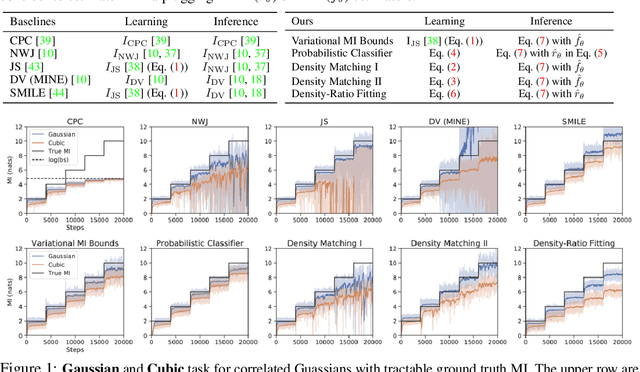
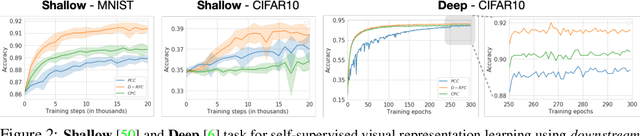
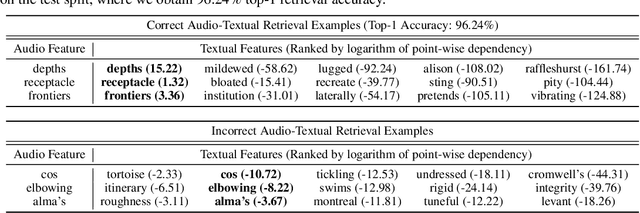
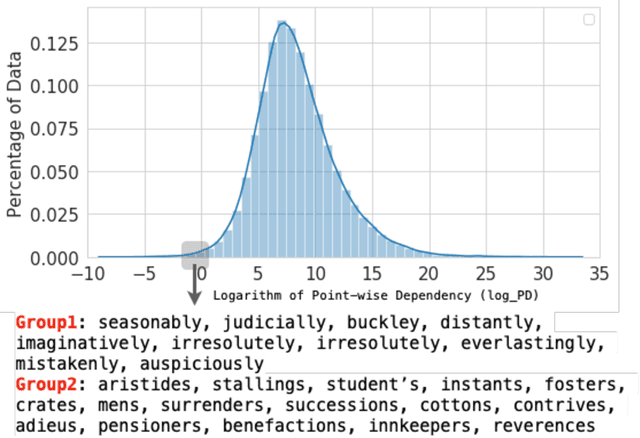
Since its inception, the neural estimation of mutual information (MI) has demonstrated the empirical success of modeling expected dependency between high-dimensional random variables. However, MI is an aggregate statistic and cannot be used to measure point-wise dependency between different events. In this work, instead of estimating the expected dependency, we focus on estimating point-wise dependency (PD), which quantitatively measures how likely two outcomes co-occur. We show that we can naturally obtain PD when we are optimizing MI neural variational bounds. However, optimizing these bounds is challenging due to its large variance in practice. To address this issue, we develop two methods (free of optimizing MI variational bounds): Probabilistic Classifier and Density-Ratio Fitting. We demonstrate the effectiveness of our approaches in 1) MI estimation, 2) self-supervised representation learning, and 3) cross-modal retrieval task.