 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Speeds of Learning: A Representation-Readout Decomposition of Grokking and Double Descent
May 28, 2026Training loss and accuracy are the standard signals used to monitor generalization during deep neural network training. Two well-documented phenomena complicate this picture: in grokking, train loss falls rapidly while test performance improves abruptly only after a long delay; in epoch-wise double descent, train loss decreases monotonically while test loss or error rises and falls. Existing accounts are often task-specific, and a task-agnostic analysis framework for diagnosing and explaining these phenomena across realistic tasks and architectures is missing. We address this challenge by analyzing two competing processes that underlie learning dynamics: representation learning in the encoder and readout calibration in the final classifier. Using tools from representational geometry, neural tangent kernels, and linear probing, we show that both processes are active throughout training, with the fluctuations of their relative speed giving rise to seemingly anomalous generalization dynamics. Applying the representation-readout decomposition to grokking across a wide range of tasks and architectures, we find that the readout is train-biased before grokking onset, and representation learning is gradual but not absent, contrary to the lazy-to-rich account. The framework further provides diagnostic signatures distinguishing spurious from genuine generalization: in a previously reported MNIST grokking example and an epoch-wise double descent example, apparent delayed or non-monotone generalization is shown to arise from representation degradation and readout misalignment induced by non-standard training recipes. Together, these results establish the representation-readout decomposition as a top-down framework for understanding learning dynamics and revealing underlying algorithms for interpretability research.
Diagnosing Generalization Failures from Representational Geometry Markers
Mar 02, 2026Generalization, the ability to perform well beyond the training context, is a hallmark of biological and artificial intelligence, yet anticipating unseen failures remains a central challenge. Conventional approaches often take a ``bottom-up'' mechanistic route by reverse-engineering interpretable features or circuits to build explanatory models. While insightful, these methods often struggle to provide the high-level, predictive signals for anticipating failure in real-world deployment. Here, we propose using a ``top-down'' approach to studying generalization failures inspired by medical biomarkers: identifying system-level measurements that serve as robust indicators of a model's future performance. Rather than mapping out detailed internal mechanisms, we systematically design and test network markers to probe structure, function links, identify prognostic indicators, and validate predictions in real-world settings. In image classification, we find that task-relevant geometric properties of in-distribution (ID) object manifolds consistently forecast poor out-of-distribution (OOD) generalization. In particular, reductions in two geometric measures, effective manifold dimensionality and utility, predict weaker OOD performance across diverse architectures, optimizers, and datasets. We apply this finding to transfer learning with ImageNet-pretrained models. We consistently find that the same geometric patterns predict OOD transfer performance more reliably than ID accuracy. This work demonstrates that representational geometry can expose hidden vulnerabilities, offering more robust guidance for model selection and AI interpretability.
What You See is What You Get: Distributional Generalization for Algorithm Design in Deep Learning
Apr 07, 2022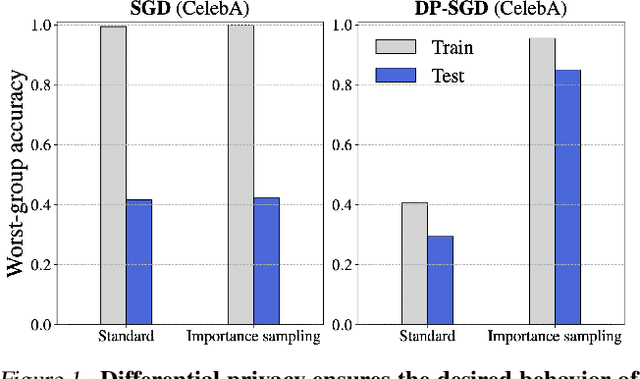
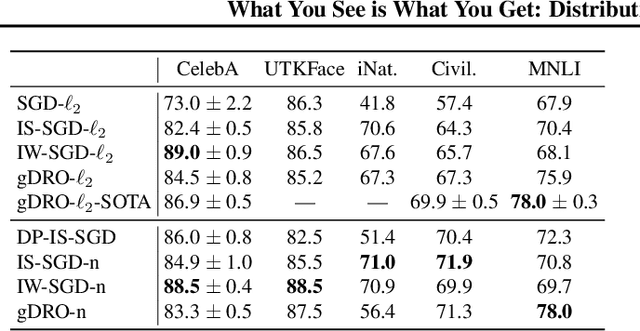
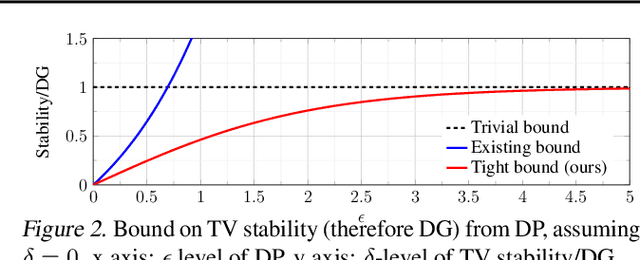
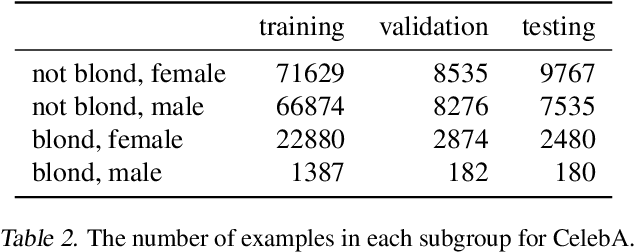
We investigate and leverage a connection between Differential Privacy (DP) and the recently proposed notion of Distributional Generalization (DG). Applying this connection, we introduce new conceptual tools for designing deep-learning methods that bypass "pathologies" of standard stochastic gradient descent (SGD). First, we prove that differentially private methods satisfy a "What You See Is What You Get (WYSIWYG)" generalization guarantee: whatever a model does on its train data is almost exactly what it will do at test time. This guarantee is formally captured by distributional generalization. WYSIWYG enables principled algorithm design in deep learning by reducing $\textit{generalization}$ concerns to $\textit{optimization}$ ones: in order to mitigate unwanted behavior at test time, it is provably sufficient to mitigate this behavior on the train data. This is notably false for standard (non-DP) methods, hence this observation has applications even when privacy is not required. For example, importance sampling is known to fail for standard SGD, but we show that it has exactly the intended effect for DP-trained models. Thus, with DP-SGD, unlike with SGD, we can influence test-time behavior by making principled train-time interventions. We use these insights to construct simple algorithms which match or outperform SOTA in several distributional robustness applications, and to significantly improve the privacy vs. disparate impact trade-off of DP-SGD. Finally, we also improve on known theoretical bounds relating differential privacy, stability, and distributional generalization.
Understanding Rare Spurious Correlations in Neural Networks
Feb 10, 2022
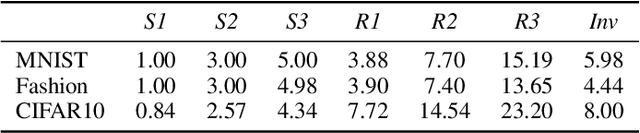
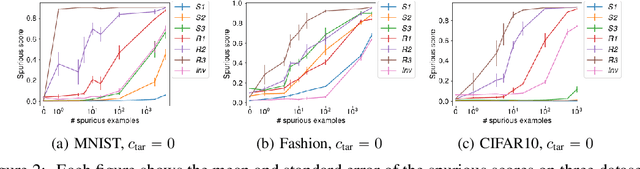
Neural networks are known to use spurious correlations for classification; for example, they commonly use background information to classify objects. But how many examples does it take for a network to pick up these correlations? This is the question that we empirically investigate in this work. We introduce spurious patterns correlated with a specific class to a few examples and find that it takes only a handful of such examples for the network to pick up on the spurious correlation. Through extensive experiments, we show that (1) spurious patterns with a larger $\ell_2$ norm are learnt to correlate with the specified class more easily; (2) network architectures that are more sensitive to the input are more susceptible to learning these rare spurious correlations; (3) standard data deletion methods, including incremental retraining and influence functions, are unable to forget these rare spurious correlations through deleting the examples that cause these spurious correlations to be learnt. Code available at https://github.com/yangarbiter/rare-spurious-correlation.
TorchAudio: Building Blocks for Audio and Speech Processing
Oct 28, 2021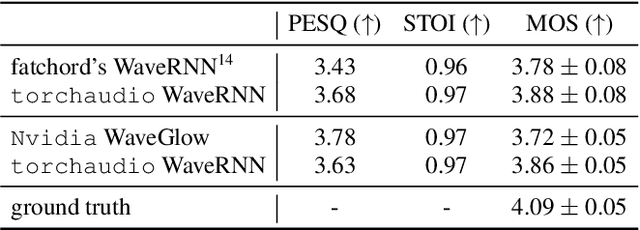
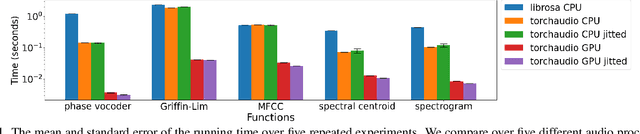


This document describes version 0.10 of torchaudio: building blocks for machine learning applications in the audio and speech processing domain. The objective of torchaudio is to accelerate the development and deployment of machine learning applications for researchers and engineers by providing off-the-shelf building blocks. The building blocks are designed to be GPU-compatible, automatically differentiable, and production-ready. torchaudio can be easily installed from Python Package Index repository and the source code is publicly available under a BSD-2-Clause License (as of September 2021) at https://github.com/pytorch/audio. In this document, we provide an overview of the design principles, functionalities, and benchmarks of torchaudio. We also benchmark our implementation of several audio and speech operations and models. We verify through the benchmarks that our implementations of various operations and models are valid and perform similarly to other publicly available implementations.
Connecting Interpretability and Robustness in Decision Trees through Separation
Feb 14, 2021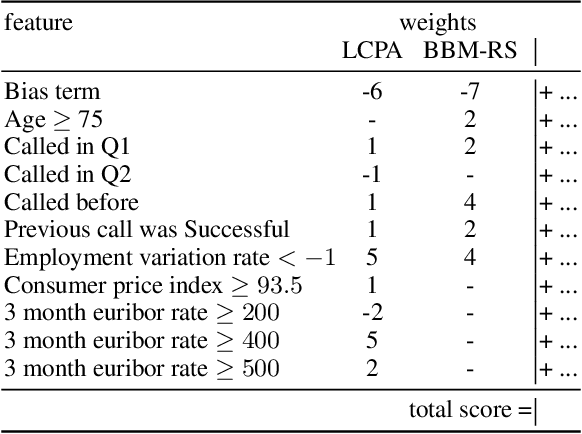
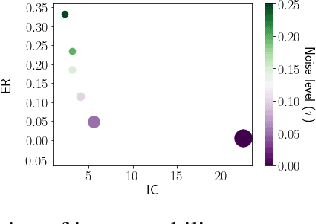
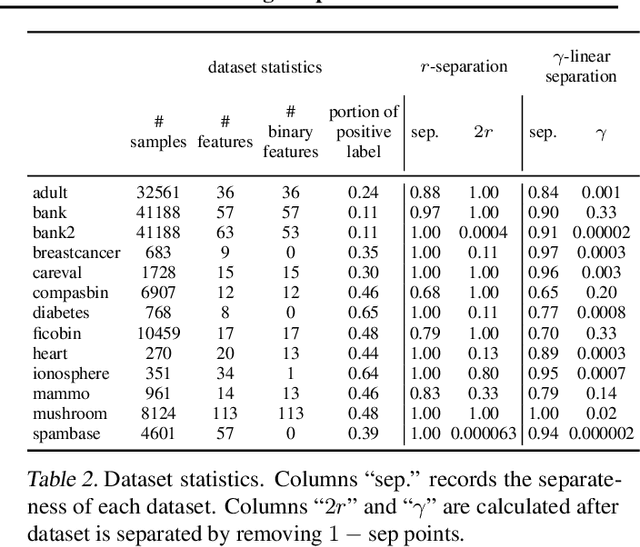
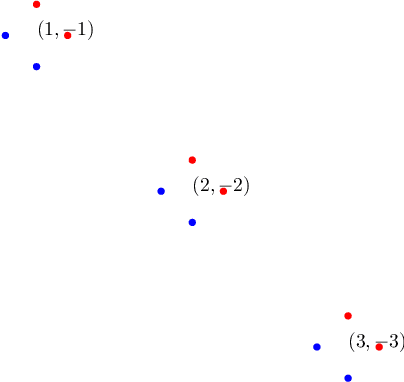
Recent research has recognized interpretability and robustness as essential properties of trustworthy classification. Curiously, a connection between robustness and interpretability was empirically observed, but the theoretical reasoning behind it remained elusive. In this paper, we rigorously investigate this connection. Specifically, we focus on interpretation using decision trees and robustness to $l_{\infty}$-perturbation. Previous works defined the notion of $r$-separation as a sufficient condition for robustness. We prove upper and lower bounds on the tree size in case the data is $r$-separated. We then show that a tighter bound on the size is possible when the data is linearly separated. We provide the first algorithm with provable guarantees both on robustness, interpretability, and accuracy in the context of decision trees. Experiments confirm that our algorithm yields classifiers that are both interpretable and robust and have high accuracy. The code for the experiments is available at https://github.com/yangarbiter/interpretable-robust-trees .
Close Category Generalization
Nov 17, 2020
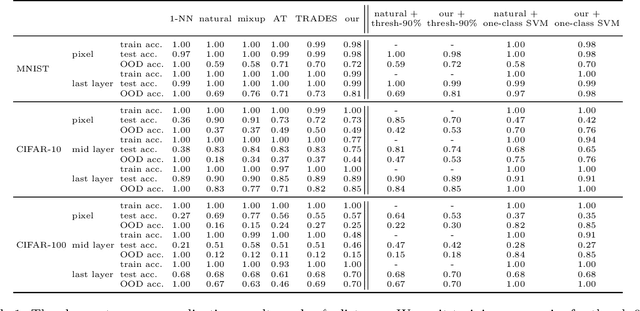
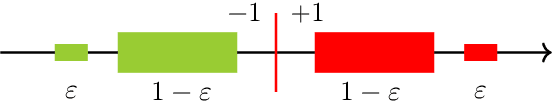
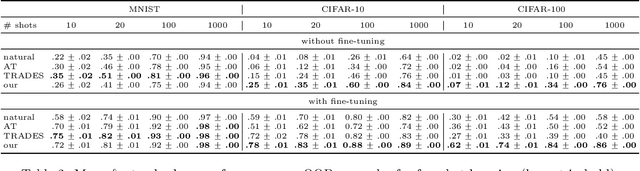
Out-of-distribution generalization is a core challenge in machine learning. We introduce and propose a solution to a new type of out-of-distribution evaluation, which we call close category generalization. This task specifies how a classifier should extrapolate to unseen classes by considering a bi-criteria objective: (i) on in-distribution examples, output the correct label, and (ii) on out-of-distribution examples, output the label of the nearest neighbor in the training set. In addition to formalizing this problem, we present a new training algorithm to improve the close category generalization of neural networks. We compare to many baselines, including robust algorithms and out-of-distribution detection methods, and we show that our method has better or comparable close category generalization. Then, we investigate a related representation learning task, and we find that performing well on close category generalization correlates with learning a good representation of an unseen class and with finding a good initialization for few-shot learning. Code available at https://github.com/yangarbiter/close-category-generalization
Adversarial Robustness Through Local Lipschitzness
Apr 16, 2020
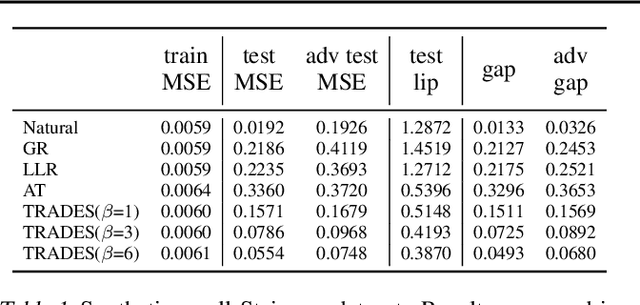
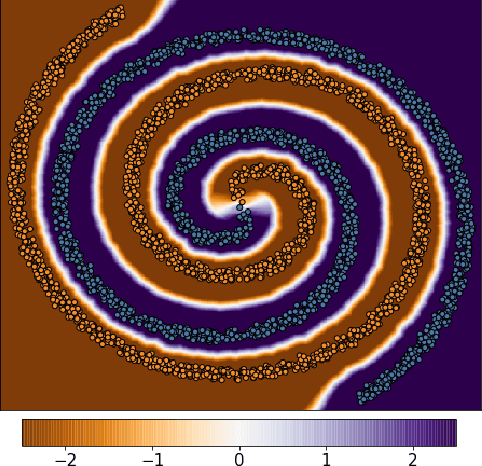
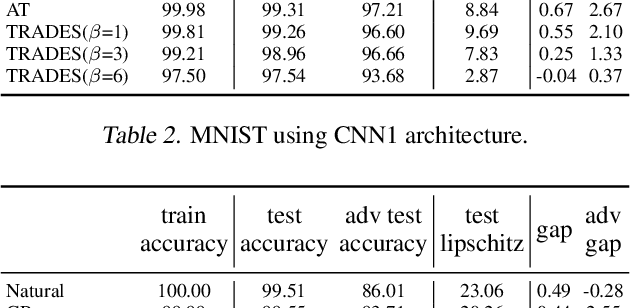
A standard method for improving the robustness of neural networks is adversarial training, where the network is trained on adversarial examples that are close to the training inputs. This produces classifiers that are robust, but it often decreases clean accuracy. Prior work even posits that the tradeoff between robustness and accuracy may be inevitable. We investigate this tradeoff in more depth through the lens of local Lipschitzness. In many image datasets, the classes are separated in the sense that images with different labels are not extremely close in $\ell_\infty$ distance. Using this separation as a starting point, we argue that it is possible to achieve both accuracy and robustness by encouraging the classifier to be locally smooth around the data. More precisely, we consider classifiers that are obtained by rounding locally Lipschitz functions. Theoretically, we show that such classifiers exist for any dataset such that there is a positive distance between the support of different classes. Empirically, we compare the local Lipschitzness of classifiers trained by several methods. Our results show that having a small Lipschitz constant correlates with achieving high clean and robust accuracy, and therefore, the smoothness of the classifier is an important property to consider in the context of adversarial examples. Code available at https://github.com/yangarbiter/robust-local-lipschitz .
Adversarial Examples for Non-Parametric Methods: Attacks, Defenses and Large Sample Limits
Jun 07, 2019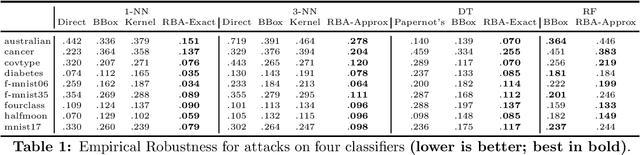
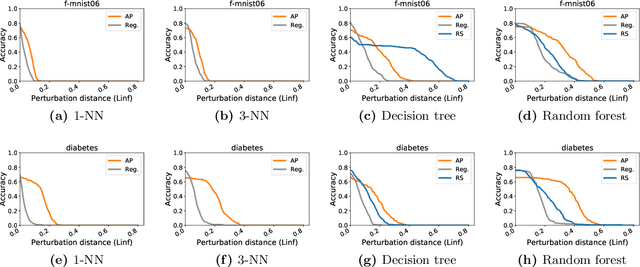
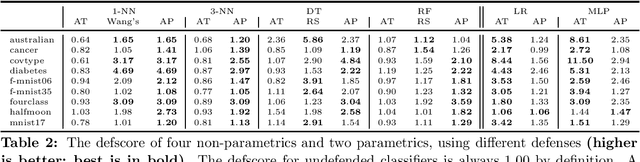
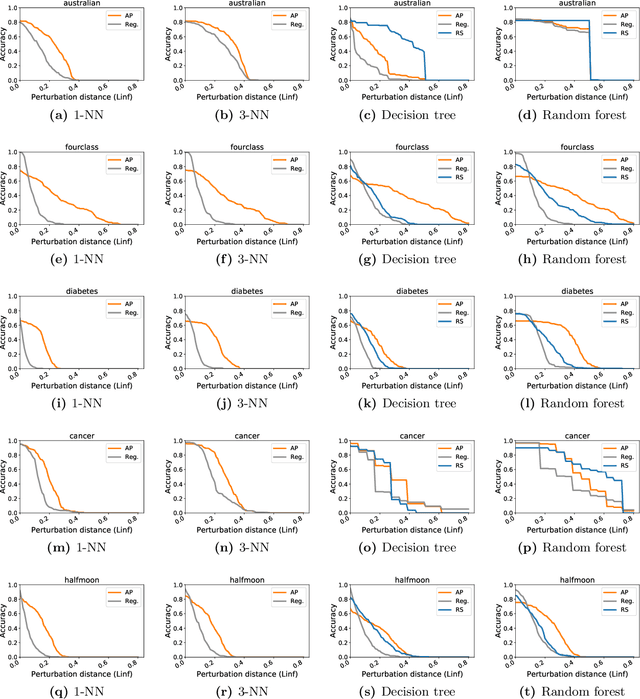
Adversarial examples have received a great deal of recent attention because of their potential to uncover security flaws in machine learning systems. However, most prior work on adversarial examples has been on parametric classifiers, for which generic attack and defense methods are known; non-parametric methods have been only considered on an ad-hoc or classifier-specific basis. In this work, we take a holistic look at adversarial examples for non-parametric methods. We first provide a general region-based attack that applies to a wide range of classifiers, including nearest neighbors, decision trees, and random forests. Motivated by the close connection between non-parametric methods and the Bayes Optimal classifier, we next exhibit a robust analogue to the Bayes Optimal, and we use it to motivate a novel and generic defense that we call adversarial pruning. We empirically show that the region-based attack and adversarial pruning defense are either better than or competitive with existing attacks and defenses for non-parametric methods, while being considerably more generally applicable.
Cost-Sensitive Reference Pair Encoding for Multi-Label Learning
Oct 26, 2018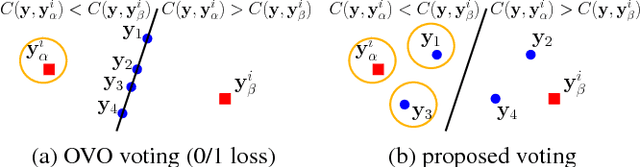
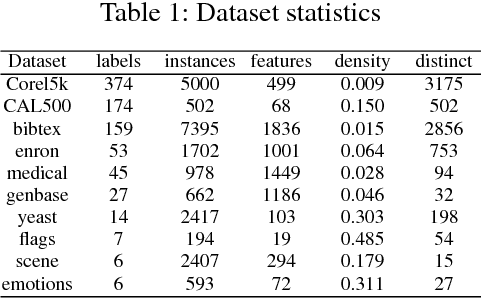
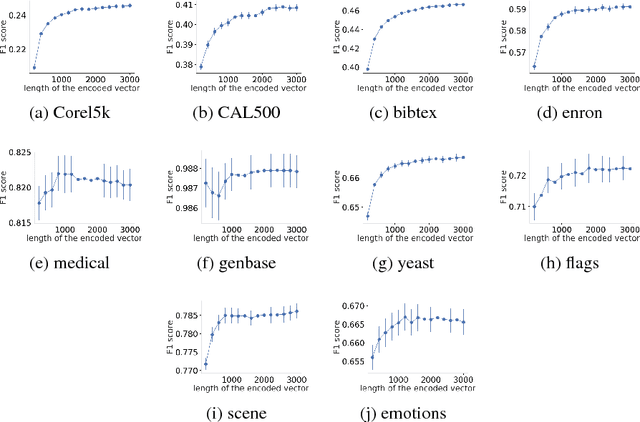
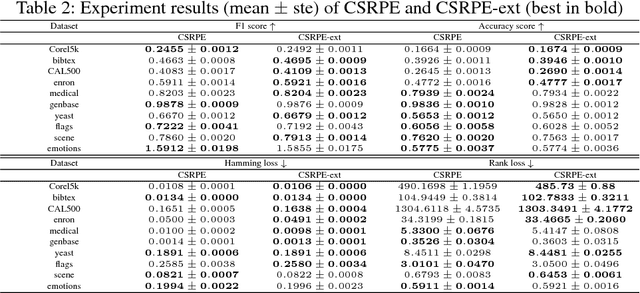
Label space expansion for multi-label classification (MLC) is a methodology that encodes the original label vectors to higher dimensional codes before training and decodes the predicted codes back to the label vectors during testing. The methodology has been demonstrated to improve the performance of MLC algorithms when coupled with off-the-shelf error-correcting codes for encoding and decoding. Nevertheless, such a coding scheme can be complicated to implement, and cannot easily satisfy a common application need of cost-sensitive MLC---adapting to different evaluation criteria of interest. In this work, we show that a simpler coding scheme based on the concept of a reference pair of label vectors achieves cost-sensitivity more naturally. In particular, our proposed cost-sensitive reference pair encoding (CSRPE) algorithm contains cluster-based encoding, weight-based training and voting-based decoding steps, all utilizing the cost information. Furthermore, we leverage the cost information embedded in the code space of CSRPE to propose a novel active learning algorithm for cost-sensitive MLC. Extensive experimental results verify that CSRPE performs better than state-of-the-art algorithms across different MLC criteria. The results also demonstrate that the CSRPE-backed active learning algorithm is superior to existing algorithms for active MLC, and further justify the usefulness of CSRPE.