 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe: A Continuously Reward-Finetuned LLM Query Rewriter for Multi-Stage Context-Aware Relevance in Web-Scale Video Search
Jun 12, 2026LLM-based query rewriters in production face a tension: the training reward must reflect how the rewrite is consumed by the production ranker, yet the training procedure must be cheap enough to support continuous redeployment as data drifts. We present CoRe (Context Relevance), such a system, redeployed weekly for over five months in a major short-video search engine. Our reward uses the deployed multimodal relevance model as its source and a multiplicative ratio form mirroring the production fusion algebra, closing the simulation-production gap that offline reward proxies leave open. A semi-online Mixed Preference Optimization loop makes this reward affordable at multi-million-instance weekly scale: a DPO-style pairwise objective restricts the gradient pass to a small top-k/bottom-k subset of sampled trajectories, and a phase structure reduces trainer/inference-server parameter syncs from per-step to per-phase. An automated promotion gate over reward-like and stability metrics detected and recovered from a real reward-hacking incident in production. Rewriter output is consumed as parallel relevance signals at recall, rawrank, and finerank without displacing the original signals, bounding rewriter-failure blast radius. Online A/B from two sequential production launches, first deploying the rewriter at finerank, then extending consumption to recall and rawrank, delivers statistically significant reductions in change-query rate on rewrite-impacted queries, with all headline relevance and engagement metrics moving in the expected direction.
Dynamic Control Barrier Function Regulation with Vision-Language Models for Safe, Adaptive, and Realtime Visual Navigation
Mar 22, 2026Robots operating in dynamic, unstructured environments must balance safety and efficiency under potentially limited sensing. While control barrier functions (CBFs) provide principled collision avoidance via safety filtering, their behavior is often governed by fixed parameters that can be overly conservative in benign scenes or overly permissive near hazards. We present AlphaAdj, a vision-to-control navigation framework that uses egocentric RGB input to adapt the conservativeness of a CBF safety filter in real time. A vision-language model(VLM) produces a bounded scalar risk estimate from the current camera view, which we map to dynamically update a CBF parameter that modulates how strongly safety constraints are enforced. To address asynchronous inference and non-trivial VLM latency in practice, we combine a geometric, speed-aware dynamic cap and a staleness-gated fusion policy with lightweight implementation choices that reduce end-to-end inference overhead. We evaluate AlphaAdj across multiple static and dynamic obstacle scenarios in a variety of environments, comparing against fixed-parameter and uncapped ablations. Results show that AlphaAdj maintains collision-free navigation while improving efficiency (in terms of path length and time to goal) by up to 18.5% relative to fixed settings and improving robustness and success rate relative to an uncapped baseline.
Empowering Dynamic Urban Navigation with Stereo and Mid-Level Vision
Dec 11, 2025



The success of foundation models in language and vision motivated research in fully end-to-end robot navigation foundation models (NFMs). NFMs directly map monocular visual input to control actions and ignore mid-level vision modules (tracking, depth estimation, etc) entirely. While the assumption that vision capabilities will emerge implicitly is compelling, it requires large amounts of pixel-to-action supervision that are difficult to obtain. The challenge is especially pronounced in dynamic and unstructured settings, where robust navigation requires precise geometric and dynamic understanding, while the depth-scale ambiguity in monocular views further limits accurate spatial reasoning. In this paper, we show that relying on monocular vision and ignoring mid-level vision priors is inefficient. We present StereoWalker, which augments NFMs with stereo inputs and explicit mid-level vision such as depth estimation and dense pixel tracking. Our intuition is straightforward: stereo inputs resolve the depth-scale ambiguity, and modern mid-level vision models provide reliable geometric and motion structure in dynamic scenes. We also curate a large stereo navigation dataset with automatic action annotation from Internet stereo videos to support training of StereoWalker and to facilitate future research. Through our experiments, we find that mid-level vision enables StereoWalker to achieve a comparable performance as the state-of-the-art using only 1.5% of the training data, and surpasses the state-of-the-art using the full data. We also observe that stereo vision yields higher navigation performance than monocular input.
Are LLMs The Way Forward? A Case Study on LLM-Guided Reinforcement Learning for Decentralized Autonomous Driving
Nov 16, 2025Autonomous vehicle navigation in complex environments such as dense and fast-moving highways and merging scenarios remains an active area of research. A key limitation of RL is its reliance on well-specified reward functions, which often fail to capture the full semantic and social complexity of diverse, out-of-distribution situations. As a result, a rapidly growing line of research explores using Large Language Models (LLMs) to replace or supplement RL for direct planning and control, on account of their ability to reason about rich semantic context. However, LLMs present significant drawbacks: they can be unstable in zero-shot safety-critical settings, produce inconsistent outputs, and often depend on expensive API calls with network latency. This motivates our investigation into whether small, locally deployed LLMs (< 14B parameters) can meaningfully support autonomous highway driving through reward shaping rather than direct control. We present a case study comparing RL-only, LLM-only, and hybrid approaches, where LLMs augment RL rewards by scoring state-action transitions during training, while standard RL policies execute at test time. Our findings reveal that RL-only agents achieve moderate success rates (73-89%) with reasonable efficiency, LLM-only agents can reach higher success rates (up to 94%) but with severely degraded speed performance, and hybrid approaches consistently fall between these extremes. Critically, despite explicit efficiency instructions, LLM-influenced approaches exhibit systematic conservative bias with substantial model-dependent variability, highlighting important limitations of current small LLMs for safety-critical control tasks.
LIVEPOINT: Fully Decentralized, Safe, Deadlock-Free Multi-Robot Control in Cluttered Environments with High-Dimensional Inputs
Mar 17, 2025



Fully decentralized, safe, and deadlock-free multi-robot navigation in dynamic, cluttered environments is a critical challenge in robotics. Current methods require exact state measurements in order to enforce safety and liveness e.g. via control barrier functions (CBFs), which is challenging to achieve directly from onboard sensors like lidars and cameras. This work introduces LIVEPOINT, a decentralized control framework that synthesizes universal CBFs over point clouds to enable safe, deadlock-free real-time multi-robot navigation in dynamic, cluttered environments. Further, LIVEPOINT ensures minimally invasive deadlock avoidance behavior by dynamically adjusting agents' speeds based on a novel symmetric interaction metric. We validate our approach in simulation experiments across highly constrained multi-robot scenarios like doorways and intersections. Results demonstrate that LIVEPOINT achieves zero collisions or deadlocks and a 100% success rate in challenging settings compared to optimization-based baselines such as MPC and ORCA and neural methods such as MPNet, which fail in such environments. Despite prioritizing safety and liveness, LIVEPOINT is 35% smoother than baselines in the doorway environment, and maintains agility in constrained environments while still being safe and deadlock-free.
Score: A Rule Engine for the Scone Knowledge Base System
May 07, 2023We present Score, a rule engine designed and implemented for the Scone knowledge base system. Scone is a knowledge base system designed for storing and manipulating rich representations of general knowledge in symbolic form. It represents knowledge in the form of nodes and links in a network structure, and it can perform basic inference about the relationships between different elements efficiently. On its own, Scone acts as a sort of "smart memory" that can interface with other software systems. One area of improvement for Scone is how useful it can be in supplying knowledge to an intelligent agent that can use the knowledge to perform actions and update the knowledge base with its observations. We augment the Scone system with a production rule engine that automatically performs simple inference based on existing and newly-added structures in Scone's knowledge base, potentially improving the capabilities of any planning systems built on top of Scone. Production rule systems consist of "if-then" production rules that try to match their predicates to existing knowledge and fire their actions when their predicates are satisfied. We propose two kinds of production rules, if-added and if-needed rules, that differ in how they are checked and fired to cover multiple use cases. We then implement methods to efficiently check and fire these rules in a large knowledge base. The new rule engine is not meant to be a complex stand-alone planner, so we discuss how it fits into the context of Scone and future work on planning systems.
On Emergent Communication in Competitive Multi-Agent Teams
Mar 04, 2020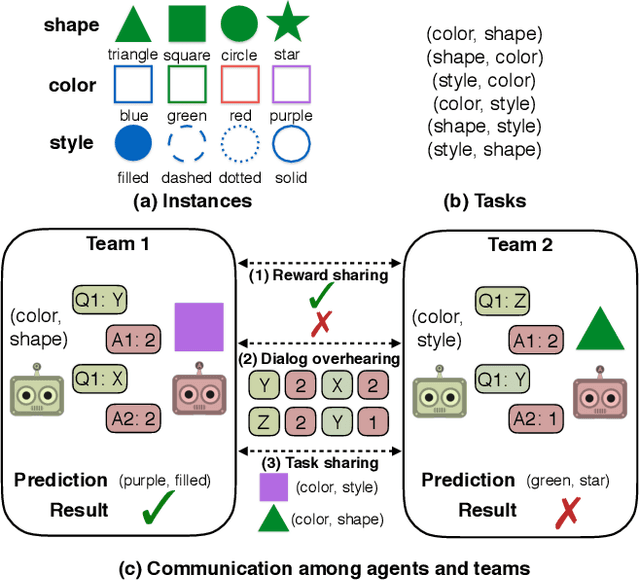
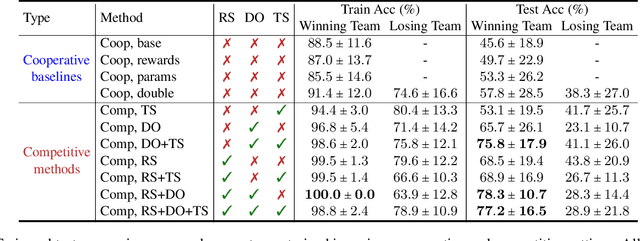
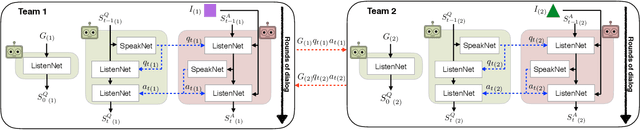
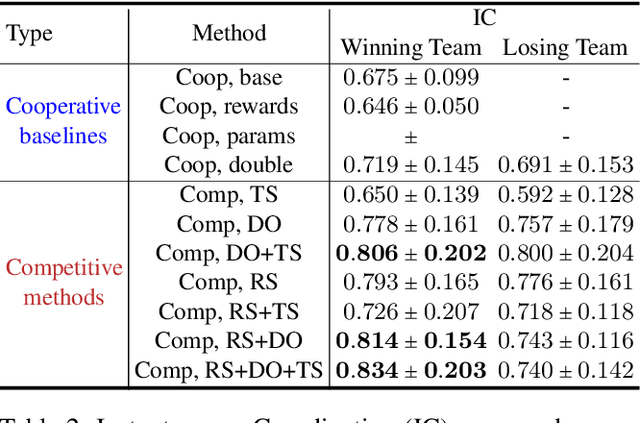
Several recent works have found the emergence of grounded compositional language in the communication protocols developed by mostly cooperative multi-agent systems when learned end-to-end to maximize performance on a downstream task. However, human populations learn to solve complex tasks involving communicative behaviors not only in fully cooperative settings but also in scenarios where competition acts as an additional external pressure for improvement. In this work, we investigate whether competition for performance from an external, similar agent team could act as a social influence that encourages multi-agent populations to develop better communication protocols for improved performance, compositionality, and convergence speed. We start from Task & Talk, a previously proposed referential game between two cooperative agents as our testbed and extend it into Task, Talk & Compete, a game involving two competitive teams each consisting of two aforementioned cooperative agents. Using this new setting, we provide an empirical study demonstrating the impact of competitive influence on multi-agent teams. Our results show that an external competitive influence leads to improved accuracy and generalization, as well as faster emergence of communicative languages that are more informative and compositional.