 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multimodal Routing for Human Multimodal Language
Paper and Code
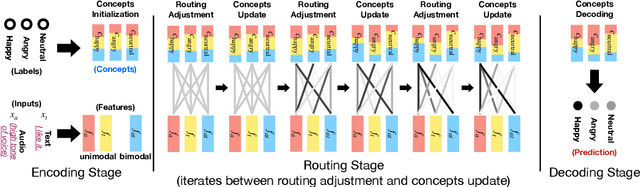
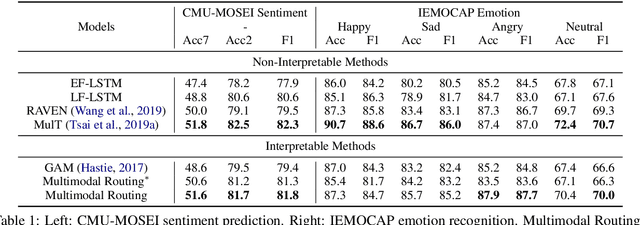
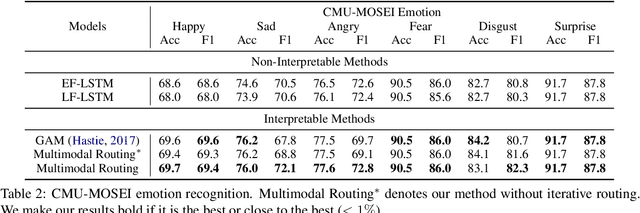

The human language has heterogeneous sources of information, including tones of voice, facial gestures, and spoken language. Recent advances introduced computational models to combine these multimodal sources and yielded strong performance on human-centric tasks. Nevertheless, most of the models are often black-box, which comes with the price of lacking interpretability. In this paper, we propose Multimodal Routing to separate the contributions to the prediction from each modality and the interactions between modalities. At the heart of our method is a routing mechanism that represents each prediction as a concept, i.e., a vector in a Euclidean space. The concept assumes a linear aggregation from the contributions of multimodal features. Then, the routing procedure iteratively 1) associates a feature and a concept by checking how this concept agrees with this feature and 2) updates the concept based on the associations. In our experiments, we provide both global and local interpretation using Multimodal Routing on sentiment analysis and emotion prediction, without loss of performance compared to state-of-the-art methods. For example, we observe that our model relies mostly on the text modality for neutral sentiment predictions, the acoustic modality for extremely negative predictions, and the text-acoustic bimodal interaction for extremely positive predictions.