 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttn-GS: Attention-Guided Context Compression for Efficient Personalized LLMs
Feb 08, 2026Personalizing large language models (LLMs) to individual users requires incorporating extensive interaction histories and profiles, but input token constraints make this impractical due to high inference latency and API costs. Existing approaches rely on heuristic methods such as selecting recent interactions or prompting summarization models to compress user profiles. However, these methods treat context as a monolithic whole and fail to consider how LLMs internally process and prioritize different profile components. We investigate whether LLMs' attention patterns can effectively identify important personalization signals for intelligent context compression. Through preliminary studies on representative personalization tasks, we discover that (a) LLMs' attention patterns naturally reveal important signals, and (b) fine-tuning enhances LLMs' ability to distinguish between relevant and irrelevant information. Based on these insights, we propose Attn-GS, an attention-guided context compression framework that leverages attention feedback from a marking model to mark important personalization sentences, then guides a compression model to generate task-relevant, high-quality compressed user contexts. Extensive experiments demonstrate that Attn-GS significantly outperforms various baselines across different tasks, token limits, and settings, achieving performance close to using full context while reducing token usage by 50 times.
PESCO: Prompt-enhanced Self Contrastive Learning for Zero-shot Text Classification
May 24, 2023We present PESCO, a novel contrastive learning framework that substantially improves the performance of zero-shot text classification. We formulate text classification as a neural text matching problem where each document is treated as a query, and the system learns the mapping from each query to the relevant class labels by (1) adding prompts to enhance label matching, and (2) using retrieved labels to enrich the training set in a self-training loop of contrastive learning. PESCO achieves state-of-the-art performance on four benchmark text classification datasets. On DBpedia, we achieve 98.5\% accuracy without any labeled data, which is close to the fully-supervised result. Extensive experiments and analyses show all the components of PESCO are necessary for improving the performance of zero-shot text classification.
* accepted by ACL 2023
Generation-driven Contrastive Self-training for Zero-shot Text Classification with Instruction-tuned GPT
Apr 24, 2023Moreover, GPT-based zero-shot classification models tend to make independent predictions over test instances, which can be sub-optimal as the instance correlations and the decision boundaries in the target space are ignored. To address these difficulties and limitations, we propose a new approach to zero-shot text classification, namely \ourmodelshort, which leverages the strong generative power of GPT to assist in training a smaller, more adaptable, and efficient sentence encoder classifier with contrastive self-training. Specifically, GenCo applies GPT in two ways: firstly, it generates multiple augmented texts for each input instance to enhance the semantic embedding of the instance and improve the mapping to relevant labels; secondly, it generates augmented texts conditioned on the predicted label during self-training, which makes the generative process tailored to the decision boundaries in the target space. In our experiments, GenCo outperforms previous state-of-the-art methods on multiple benchmark datasets, even when only limited in-domain text data is available.
English Contrastive Learning Can Learn Universal Cross-lingual Sentence Embeddings
Nov 11, 2022Universal cross-lingual sentence embeddings map semantically similar cross-lingual sentences into a shared embedding space. Aligning cross-lingual sentence embeddings usually requires supervised cross-lingual parallel sentences. In this work, we propose mSimCSE, which extends SimCSE to multilingual settings and reveal that contrastive learning on English data can surprisingly learn high-quality universal cross-lingual sentence embeddings without any parallel data. In unsupervised and weakly supervised settings, mSimCSE significantly improves previous sentence embedding methods on cross-lingual retrieval and multilingual STS tasks. The performance of unsupervised mSimCSE is comparable to fully supervised methods in retrieving low-resource languages and multilingual STS. The performance can be further enhanced when cross-lingual NLI data is available. Our code is publicly available at https://github.com/yaushian/mSimCSE.
Toxicity Detection with Generative Prompt-based Inference
May 24, 2022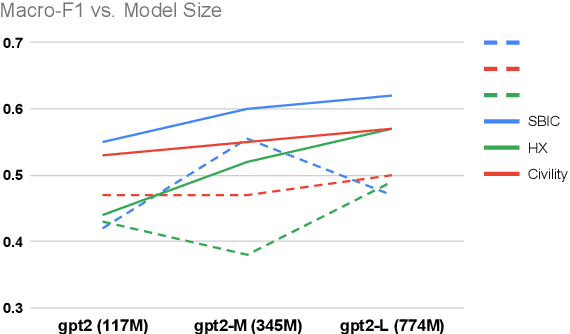

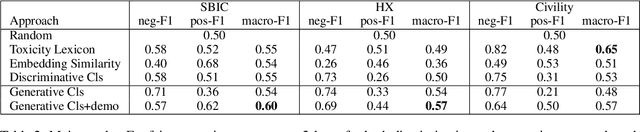
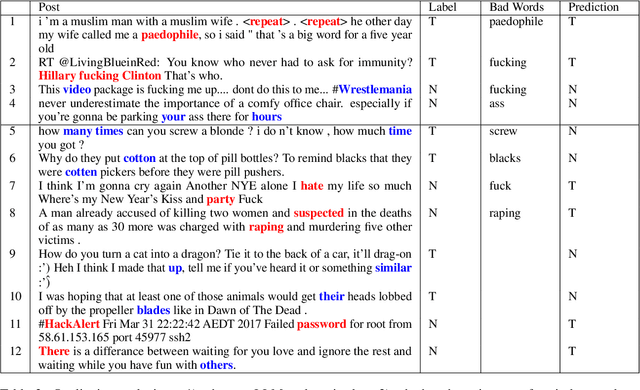
Due to the subtleness, implicity, and different possible interpretations perceived by different people, detecting undesirable content from text is a nuanced difficulty. It is a long-known risk that language models (LMs), once trained on corpus containing undesirable content, have the power to manifest biases and toxicity. However, recent studies imply that, as a remedy, LMs are also capable of identifying toxic content without additional fine-tuning. Prompt-methods have been shown to effectively harvest this surprising self-diagnosing capability. However, existing prompt-based methods usually specify an instruction to a language model in a discriminative way. In this work, we explore the generative variant of zero-shot prompt-based toxicity detection with comprehensive trials on prompt engineering. We evaluate on three datasets with toxicity labels annotated on social media posts. Our analysis highlights the strengths of our generative classification approach both quantitatively and qualitatively. Interesting aspects of self-diagnosis and its ethical implications are discussed.
Long-tailed Extreme Multi-label Text Classification with Generated Pseudo Label Descriptions
Apr 02, 2022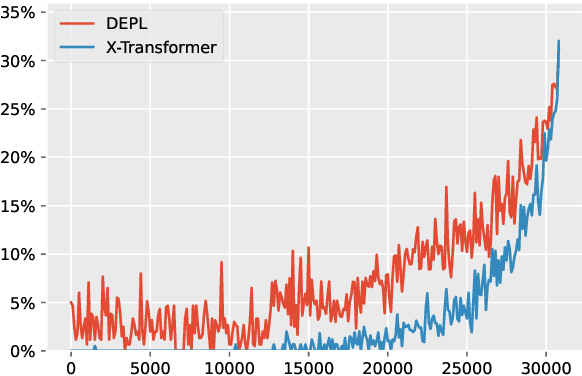
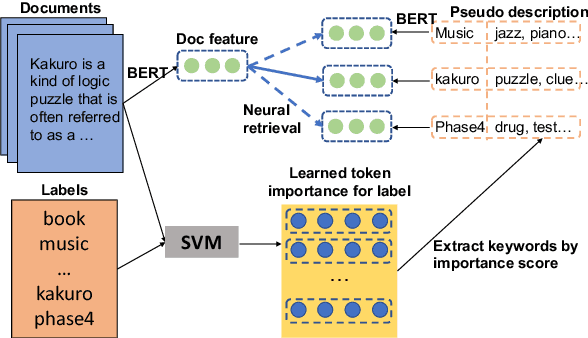
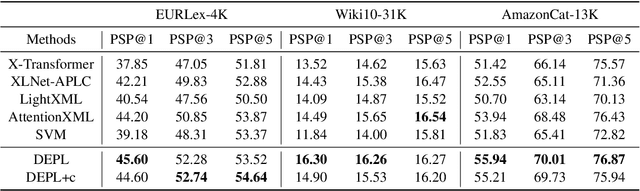
Extreme Multi-label Text Classification (XMTC) has been a tough challenge in machine learning research and applications due to the sheer sizes of the label spaces and the severe data scarce problem associated with the long tail of rare labels in highly skewed distributions. This paper addresses the challenge of tail label prediction by proposing a novel approach, which combines the effectiveness of a trained bag-of-words (BoW) classifier in generating informative label descriptions under severe data scarce conditions, and the power of neural embedding based retrieval models in mapping input documents (as queries) to relevant label descriptions. The proposed approach achieves state-of-the-art performance on XMTC benchmark datasets and significantly outperforms the best methods so far in the tail label prediction. We also provide a theoretical analysis for relating the BoW and neural models w.r.t. performance lower bound.
Exploiting Local and Global Features in Transformer-based Extreme Multi-label Text Classification
Apr 02, 2022
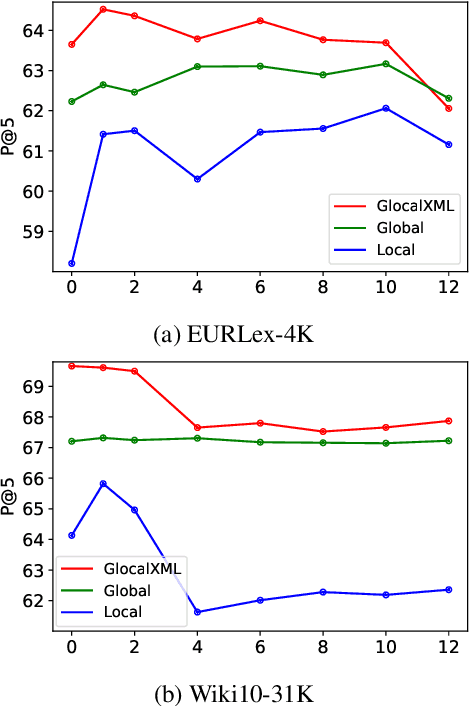
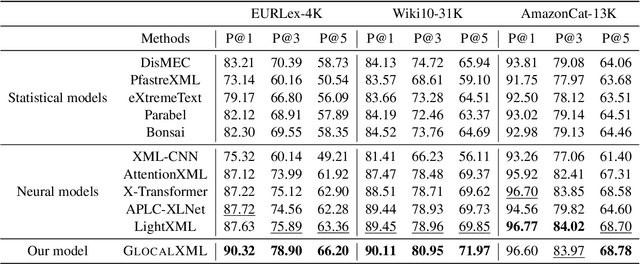
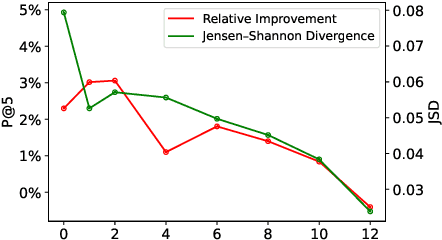
Extreme multi-label text classification (XMTC) is the task of tagging each document with the relevant labels from a very large space of predefined categories. Recently, large pre-trained Transformer models have made significant performance improvements in XMTC, which typically use the embedding of the special CLS token to represent the entire document semantics as a global feature vector, and match it against candidate labels. However, we argue that such a global feature vector may not be sufficient to represent different granularity levels of semantics in the document, and that complementing it with the local word-level features could bring additional gains. Based on this insight, we propose an approach that combines both the local and global features produced by Transformer models to improve the prediction power of the classifier. Our experiments show that the proposed model either outperforms or is comparable to the state-of-the-art methods on benchmark datasets.
Are you doing what I say? On modalities alignment in ALFRED
Oct 12, 2021
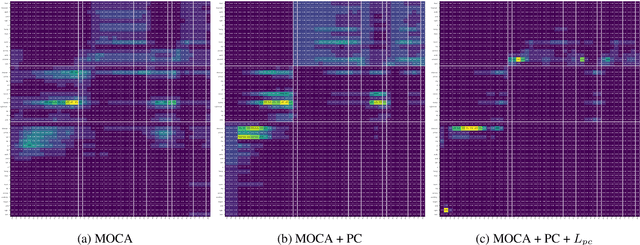
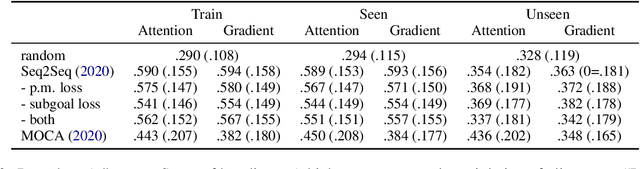
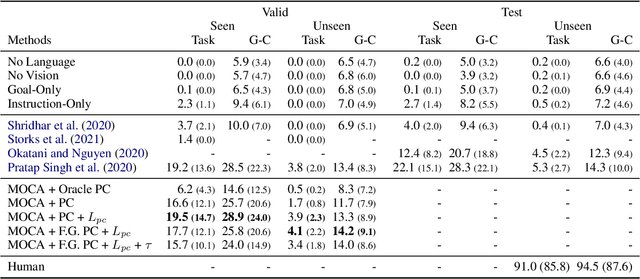
ALFRED is a recently proposed benchmark that requires a model to complete tasks in simulated house environments specified by instructions in natural language. We hypothesize that key to success is accurately aligning the text modality with visual inputs. Motivated by this, we inspect how well existing models can align these modalities using our proposed intrinsic metric, boundary adherence score (BAS). The results show the previous models are indeed failing to perform proper alignment. To address this issue, we introduce approaches aimed at improving model alignment and demonstrate how improved alignment, improves end task performance.
Investigation of Sentiment Controllable Chatbot
Jul 11, 2020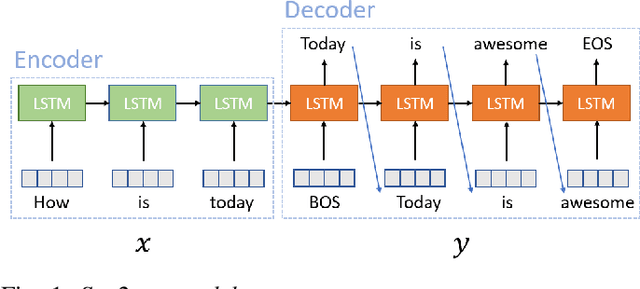
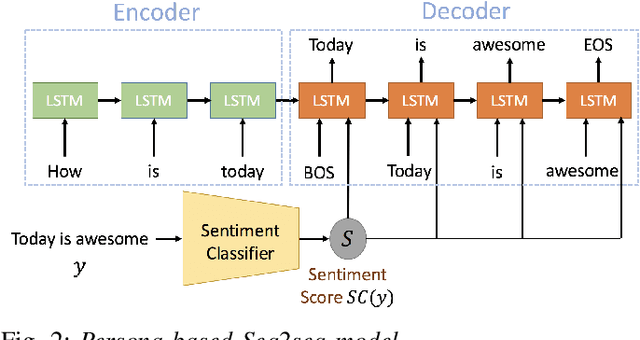
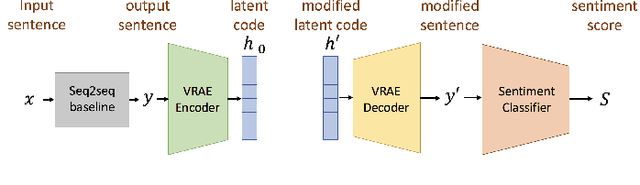
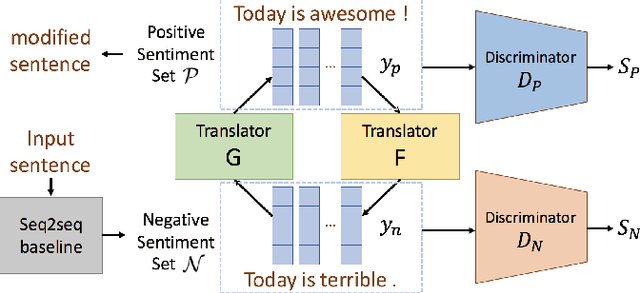
Conventional seq2seq chatbot models attempt only to find sentences with the highest probabilities conditioned on the input sequences, without considering the sentiment of the output sentences. In this paper, we investigate four models to scale or adjust the sentiment of the chatbot response: a persona-based model, reinforcement learning, a plug and play model, and CycleGAN, all based on the seq2seq model. We also develop machine-evaluated metrics to estimate whether the responses are reasonable given the input. These metrics, together with human evaluation, are used to analyze the performance of the four models in terms of different aspects; reinforcement learning and CycleGAN are shown to be very attractive.
Learning Interpretable and Discrete Representations with Adversarial Training for Unsupervised Text Classification
Apr 28, 2020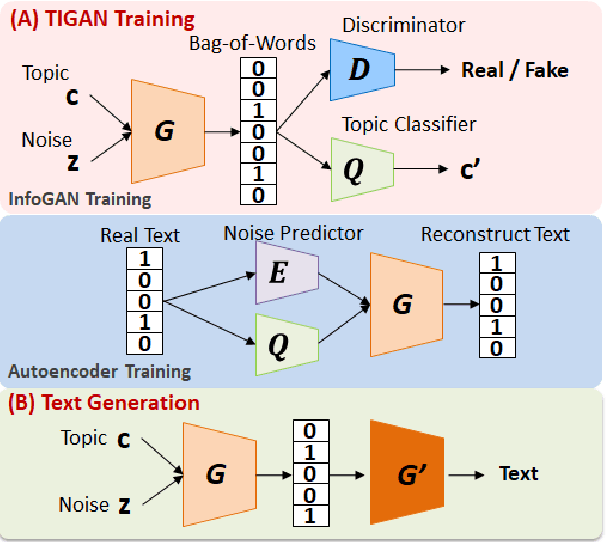
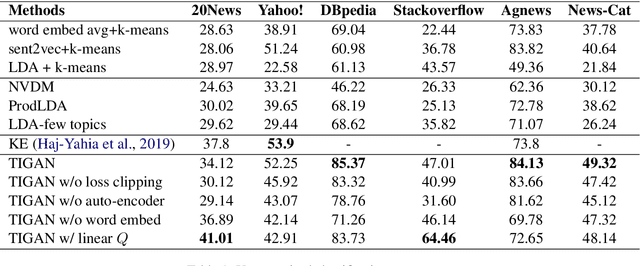
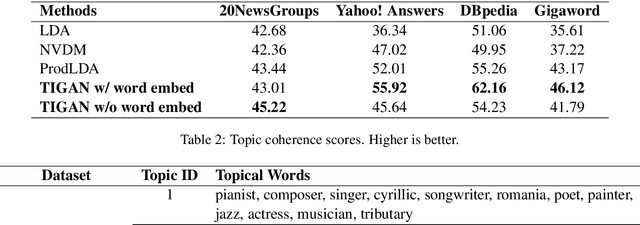

Learning continuous representations from unlabeled textual data has been increasingly studied for benefiting semi-supervised learning. Although it is relatively easier to interpret discrete representations, due to the difficulty of training, learning discrete representations for unlabeled textual data has not been widely explored. This work proposes TIGAN that learns to encode texts into two disentangled representations, including a discrete code and a continuous noise, where the discrete code represents interpretable topics, and the noise controls the variance within the topics. The discrete code learned by TIGAN can be used for unsupervised text classification. Compared to other unsupervised baselines, the proposed TIGAN achieves superior performance on six different corpora. Also, the performance is on par with a recently proposed weakly-supervised text classification method. The extracted topical words for representing latent topics show that TIGAN learns coherent and highly interpretable topics.