 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attribute Attention Network for Interpretable Diagnosis of Thyroid Nodules in Ultrasound Images
Jul 09, 2022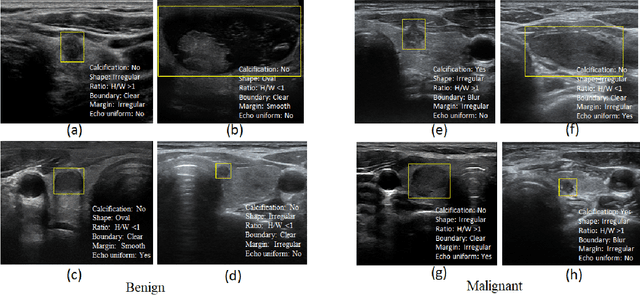
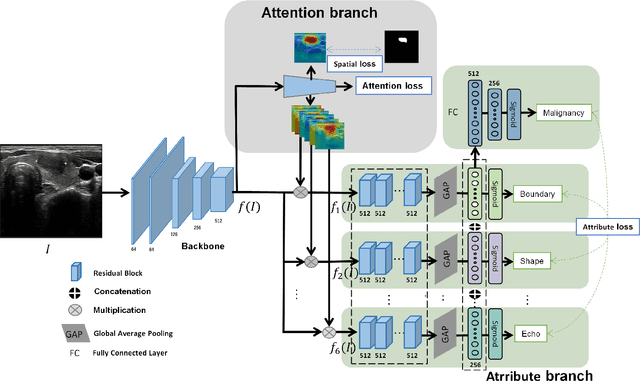
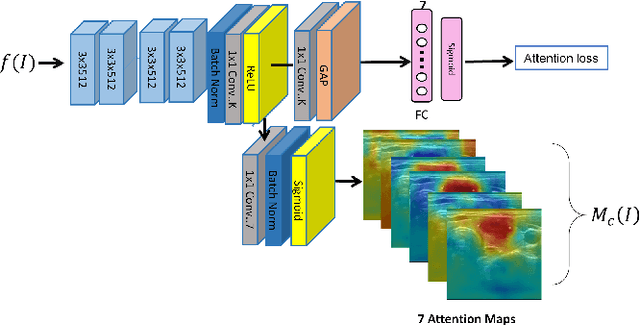
Ultrasound (US) is the primary imaging technique for the diagnosis of thyroid cancer. However, accurate identification of nodule malignancy is a challenging task that can elude less-experienced clinicians. Recently, many computer-aided diagnosis (CAD) systems have been proposed to assist this process. However, most of them do not provide the reasoning of their classification process, which may jeopardize their credibility in practical use. To overcome this, we propose a novel deep learning framework called multi-attribute attention network (MAA-Net) that is designed to mimic the clinical diagnosis process. The proposed model learns to predict nodular attributes and infer their malignancy based on these clinically-relevant features. A multi-attention scheme is adopted to generate customized attention to improve each task and malignancy diagnosis. Furthermore, MAA-Net utilizes nodule delineations as nodules spatial prior guidance for the training rather than cropping the nodules with additional models or human interventions to prevent losing the context information. Validation experiments were performed on a large and challenging dataset containing 4554 patients. Results show that the proposed method outperformed other state-of-the-art methods and provides interpretable predictions that may better suit clinical needs.
Personalized Diagnostic Tool for Thyroid Cancer Classification using Multi-view Ultrasound
Jul 01, 2022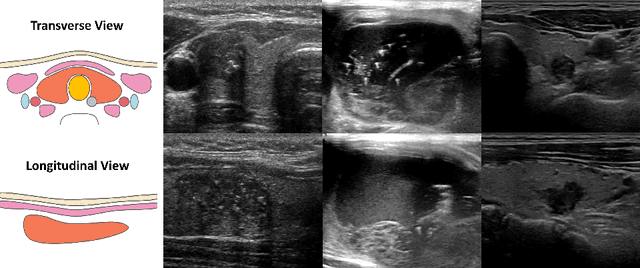
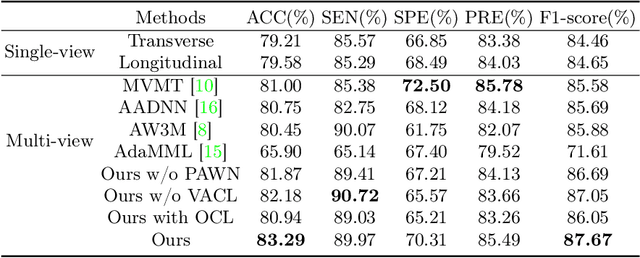
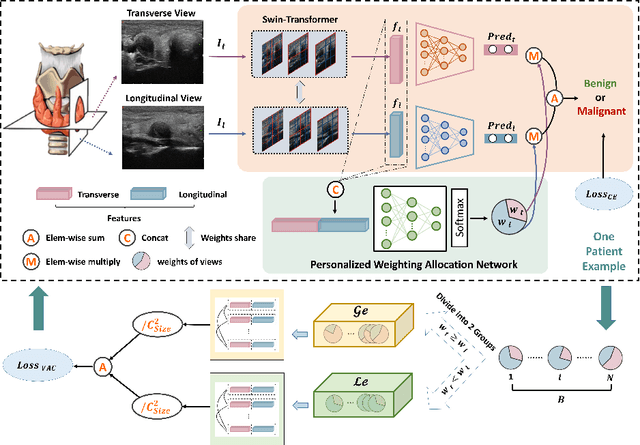
Over the past decades, the incidence of thyroid cancer has been increasing globally. Accurate and early diagnosis allows timely treatment and helps to avoid over-diagnosis. Clinically, a nodule is commonly evaluated from both transverse and longitudinal views using thyroid ultrasound. However, the appearance of the thyroid gland and lesions can vary dramatically across individuals. Identifying key diagnostic information from both views requires specialized expertise. Furthermore, finding an optimal way to integrate multi-view information also relies on the experience of clinicians and adds further difficulty to accurate diagnosis. To address these, we propose a personalized diagnostic tool that can customize its decision-making process for different patients. It consists of a multi-view classification module for feature extraction and a personalized weighting allocation network that generates optimal weighting for different views. It is also equipped with a self-supervised view-aware contrastive loss to further improve the model robustness towards different patient groups. Experimental results show that the proposed framework can better utilize multi-view information and outperform the competing methods.
Fine-grained Correlation Loss for Regression
Jul 01, 2022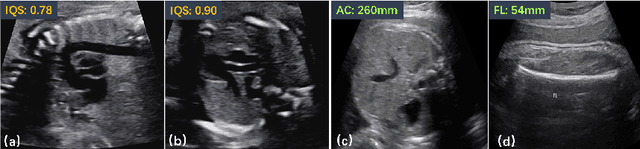
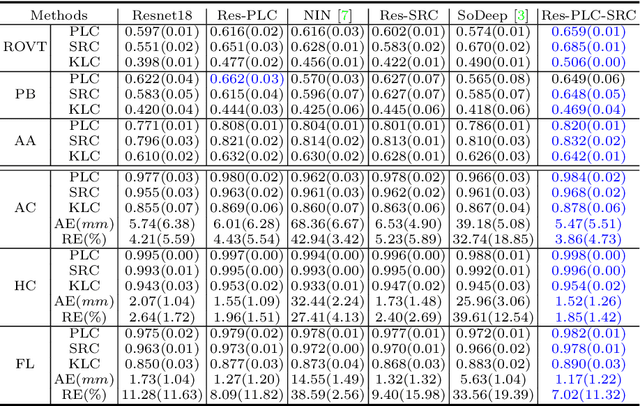
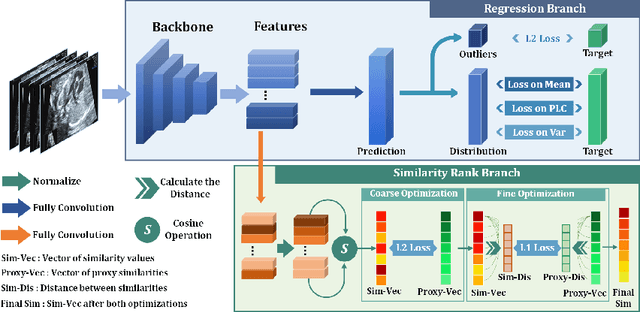
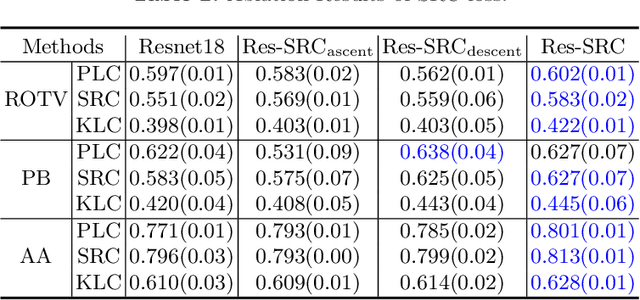
Regression learning is classic and fundamental for medical image analysis. It provides the continuous mapping for many critical applications, like the attribute estimation, object detection, segmentation and non-rigid registration. However, previous studies mainly took the case-wise criteria, like the mean square errors, as the optimization objectives. They ignored the very important population-wise correlation criterion, which is exactly the final evaluation metric in many tasks. In this work, we propose to revisit the classic regression tasks with novel investigations on directly optimizing the fine-grained correlation losses. We mainly explore two complementary correlation indexes as learnable losses: Pearson linear correlation (PLC) and Spearman rank correlation (SRC). The contributions of this paper are two folds. First, for the PLC on global level, we propose a strategy to make it robust against the outliers and regularize the key distribution factors. These efforts significantly stabilize the learning and magnify the efficacy of PLC. Second, for the SRC on local level, we propose a coarse-to-fine scheme to ease the learning of the exact ranking order among samples. Specifically, we convert the learning for the ranking of samples into the learning of similarity relationships among samples. We extensively validate our method on two typical ultrasound image regression tasks, including the image quality assessment and bio-metric measurement. Experiments prove that, with the fine-grained guidance in directly optimizing the correlation, the regression performances are significantly improved. Our proposed correlation losses are general and can be extended to more important applications.
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 20, 2022
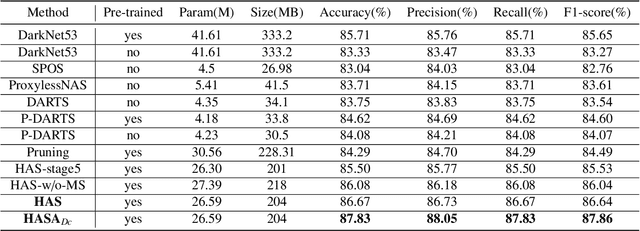
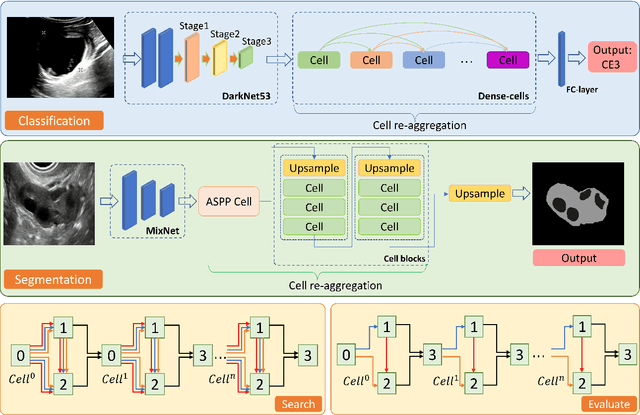
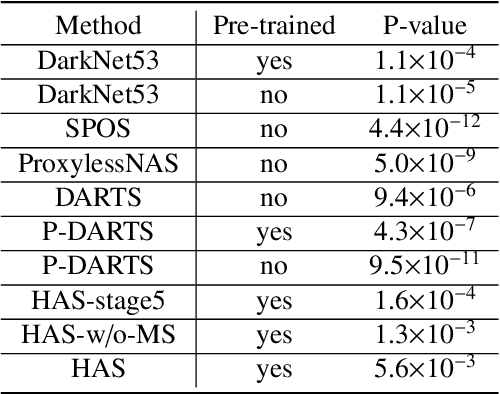
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.
Statistical Dependency Guided Contrastive Learning for Multiple Labeling in Prenatal Ultrasound
Aug 11, 2021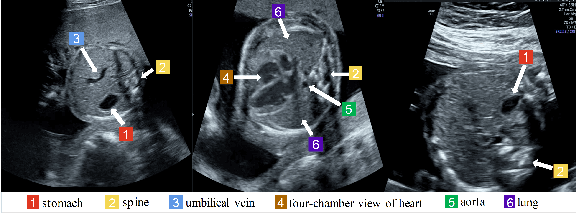
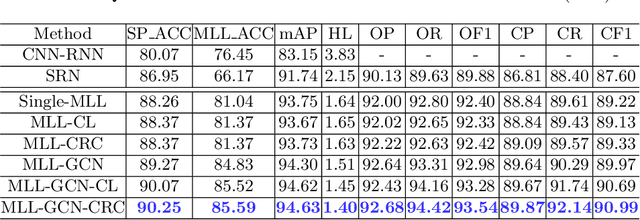
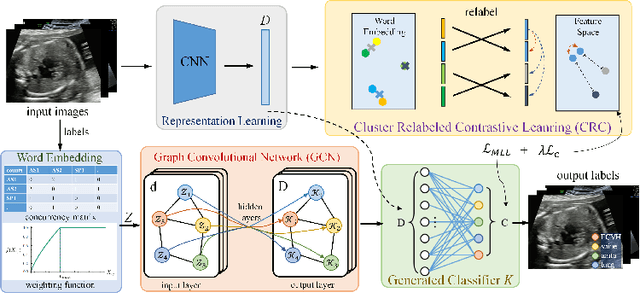
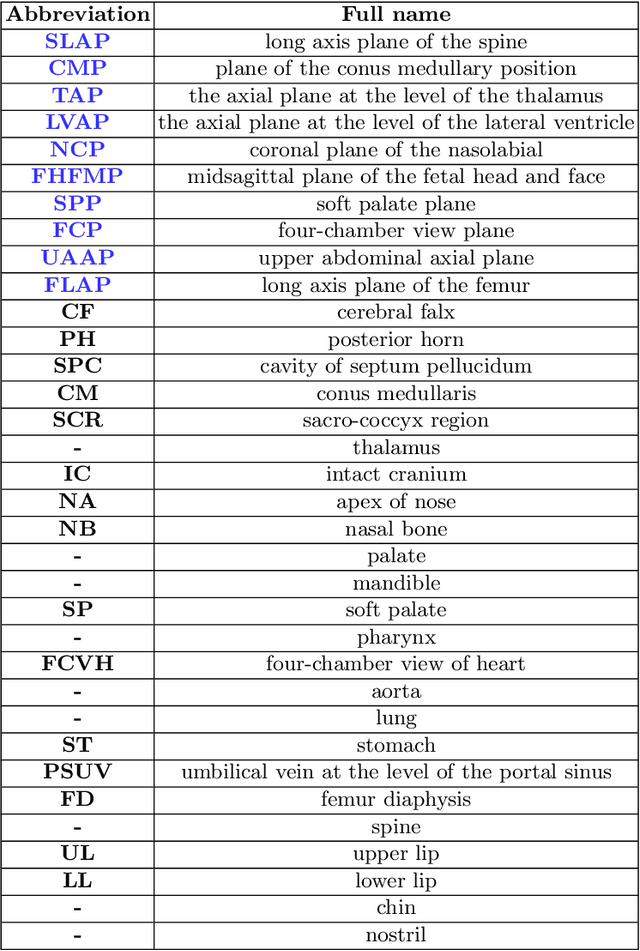
Standard plane recognition plays an important role in prenatal ultrasound (US) screening. Automatically recognizing the standard plane along with the corresponding anatomical structures in US image can not only facilitate US image interpretation but also improve diagnostic efficiency. In this study, we build a novel multi-label learning (MLL) scheme to identify multiple standard planes and corresponding anatomical structures of fetus simultaneously. Our contribution is three-fold. First, we represent the class correlation by word embeddings to capture the fine-grained semantic and latent statistical concurrency. Second, we equip the MLL with a graph convolutional network to explore the inner and outer relationship among categories. Third, we propose a novel cluster relabel-based contrastive learning algorithm to encourage the divergence among ambiguous classes. Extensive validation was performed on our large in-house dataset. Our approach reports the highest accuracy as 90.25% for standard planes labeling, 85.59% for planes and structures labeling and mAP as 94.63%. The proposed MLL scheme provides a novel perspective for standard plane recognition and can be easily extended to other medical image classification tasks.
Searching Collaborative Agents for Multi-plane Localization in 3D Ultrasound
May 22, 2021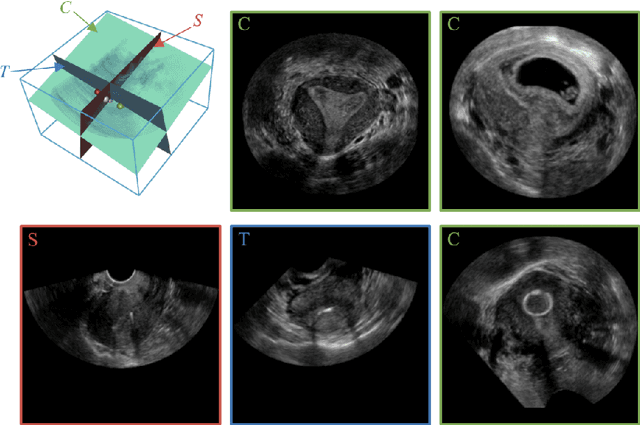
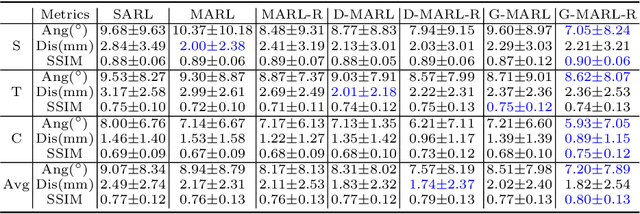
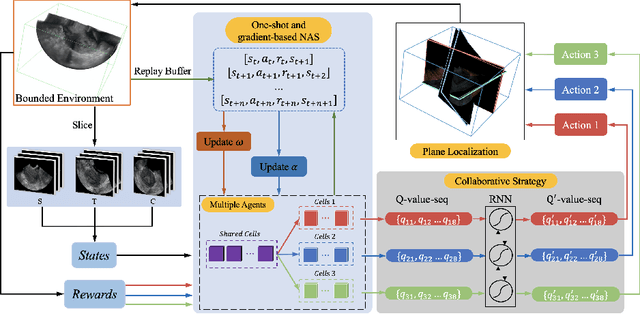

3D ultrasound (US) has become prevalent due to its rich spatial and diagnostic information not contained in 2D US. Moreover, 3D US can contain multiple standard planes (SPs) in one shot. Thus, automatically localizing SPs in 3D US has the potential to improve user-independence and scanning-efficiency. However, manual SP localization in 3D US is challenging because of the low image quality, huge search space and large anatomical variability. In this work, we propose a novel multi-agent reinforcement learning (MARL) framework to simultaneously localize multiple SPs in 3D US. Our contribution is four-fold. First, our proposed method is general and it can accurately localize multiple SPs in different challenging US datasets. Second, we equip the MARL system with a recurrent neural network (RNN) based collaborative module, which can strengthen the communication among agents and learn the spatial relationship among planes effectively. Third, we explore to adopt the neural architecture search (NAS) to automatically design the network architecture of both the agents and the collaborative module. Last, we believe we are the first to realize automatic SP localization in pelvic US volumes, and note that our approach can handle both normal and abnormal uterus cases. Extensively validated on two challenging datasets of the uterus and fetal brain, our proposed method achieves the average localization accuracy of 7.03 degrees/1.59mm and 9.75 degrees/1.19mm. Experimental results show that our light-weight MARL model has higher accuracy than state-of-the-art methods.
Agent with Warm Start and Adaptive Dynamic Termination for Plane Localization in 3D Ultrasound
Mar 26, 2021
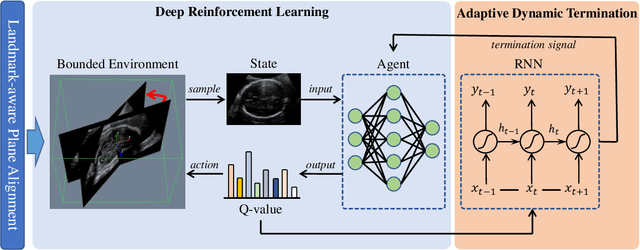
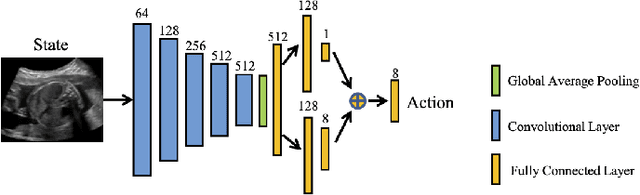
Accurate standard plane (SP) localization is the fundamental step for prenatal ultrasound (US) diagnosis. Typically, dozens of US SPs are collected to determine the clinical diagnosis. 2D US has to perform scanning for each SP, which is time-consuming and operator-dependent. While 3D US containing multiple SPs in one shot has the inherent advantages of less user-dependency and more efficiency. Automatically locating SP in 3D US is very challenging due to the huge search space and large fetal posture variations. Our previous study proposed a deep reinforcement learning (RL) framework with an alignment module and active termination to localize SPs in 3D US automatically. However, termination of agent search in RL is important and affects the practical deployment. In this study, we enhance our previous RL framework with a newly designed adaptive dynamic termination to enable an early stop for the agent searching, saving at most 67% inference time, thus boosting the accuracy and efficiency of the RL framework at the same time. Besides, we validate the effectiveness and generalizability of our algorithm extensively on our in-house multi-organ datasets containing 433 fetal brain volumes, 519 fetal abdomen volumes, and 683 uterus volumes. Our approach achieves localization error of 2.52mm/10.26 degrees, 2.48mm/10.39 degrees, 2.02mm/10.48 degrees, 2.00mm/14.57 degrees, 2.61mm/9.71 degrees, 3.09mm/9.58 degrees, 1.49mm/7.54 degrees for the transcerebellar, transventricular, transthalamic planes in fetal brain, abdominal plane in fetal abdomen, and mid-sagittal, transverse and coronal planes in uterus, respectively. Experimental results show that our method is general and has the potential to improve the efficiency and standardization of US scanning.
Contrastive Rendering for Ultrasound Image Segmentation
Oct 10, 2020
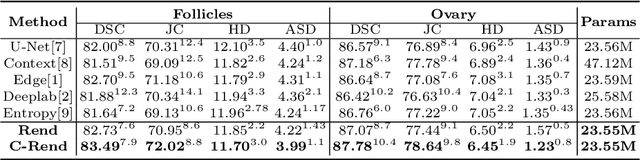
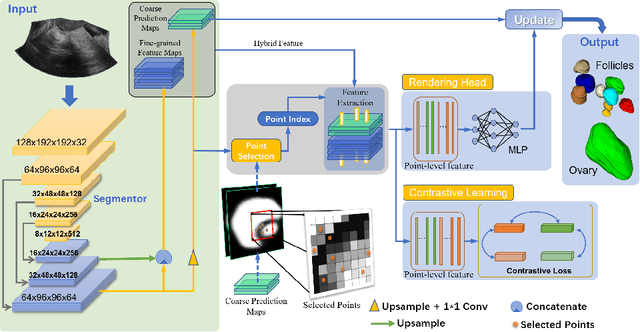
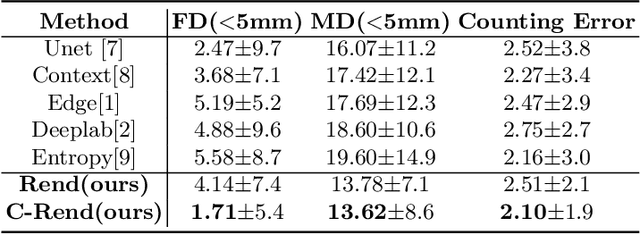
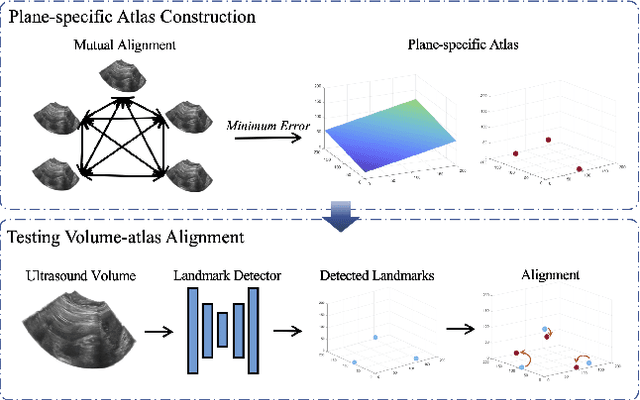
Ultrasound (US) image segmentation embraced its significant improvement in deep learning era. However, the lack of sharp boundaries in US images still remains an inherent challenge for segmentation. Previous methods often resort to global context, multi-scale cues or auxiliary guidance to estimate the boundaries. It is hard for these methods to approach pixel-level learning for fine-grained boundary generating. In this paper, we propose a novel and effective framework to improve boundary estimation in US images. Our work has three highlights. First, we propose to formulate the boundary estimation as a rendering task, which can recognize ambiguous points (pixels/voxels) and calibrate the boundary prediction via enriched feature representation learning. Second, we introduce point-wise contrastive learning to enhance the similarity of points from the same class and contrastively decrease the similarity of points from different classes. Boundary ambiguities are therefore further addressed. Third, both rendering and contrastive learning tasks contribute to consistent improvement while reducing network parameters. As a proof-of-concept, we performed validation experiments on a challenging dataset of 86 ovarian US volumes. Results show that our proposed method outperforms state-of-the-art methods and has the potential to be used in clinical practice.
Region Proposal Network with Graph Prior and IoU-Balance Loss for Landmark Detection in 3D Ultrasound
Apr 01, 2020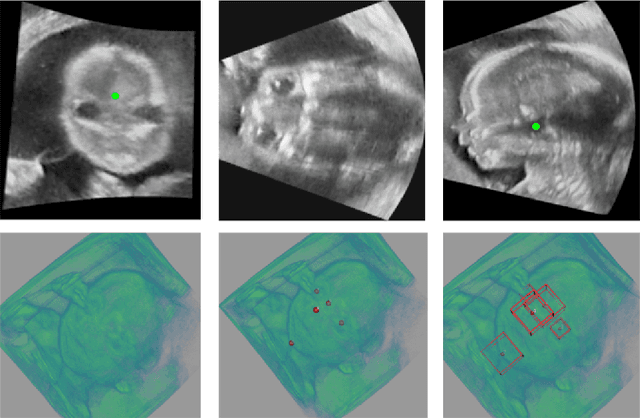
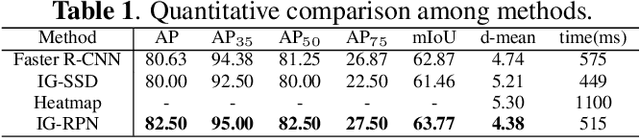
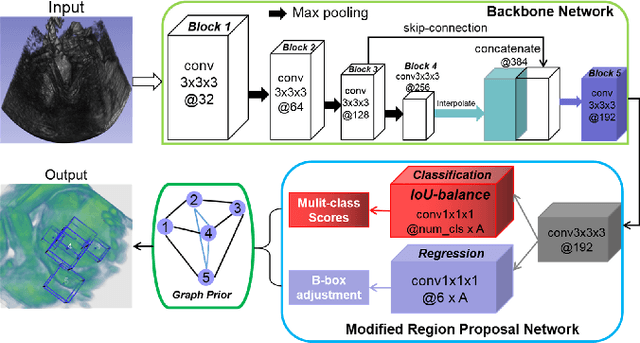
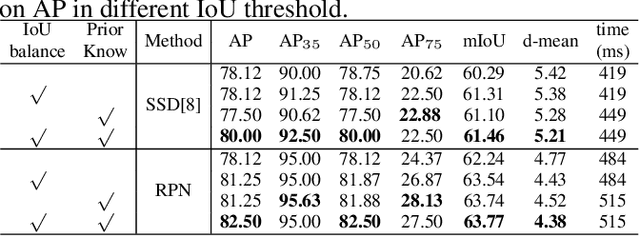
3D ultrasound (US) can facilitate detailed prenatal examinations for fetal growth monitoring. To analyze a 3D US volume, it is fundamental to identify anatomical landmarks of the evaluated organs accurately. Typical deep learning methods usually regress the coordinates directly or involve heatmap-matching. However, these methods struggle to deal with volumes with large sizes and the highly-varying positions and orientations of fetuses. In this work, we exploit an object detection framework to detect landmarks in 3D fetal facial US volumes. By regressing multiple parameters of the landmark-centered bounding box (B-box) with a strict criteria, the proposed model is able to pinpoint the exact location of the targeted landmarks. Specifically, the model uses a 3D region proposal network (RPN) to generate 3D candidate regions, followed by several 3D classification branches to select the best candidate. It also adopts an IoU-balance loss to improve communications between branches that benefits the learning process. Furthermore, it leverages a distance-based graph prior to regularize the training and helps to reduce false positive predictions. The performance of the proposed framework is evaluated on a 3D US dataset to detect five key fetal facial landmarks. Results showed the proposed method outperforms some of the state-of-the-art methods in efficacy and efficiency.
Automated fetal brain extraction from clinical Ultrasound volumes using 3D Convolutional Neural Networks
Nov 19, 2019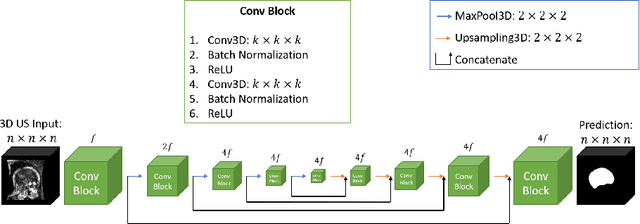
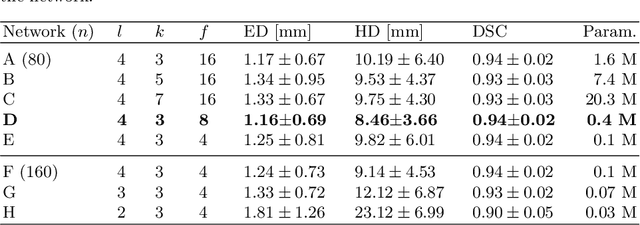
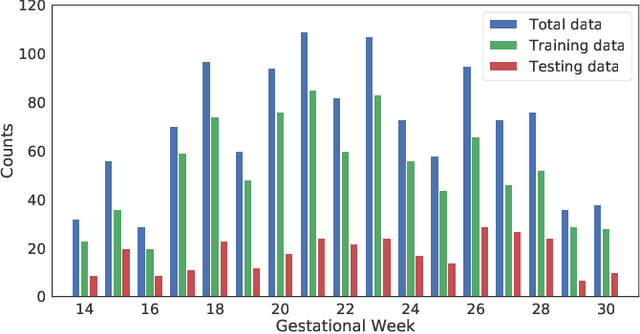
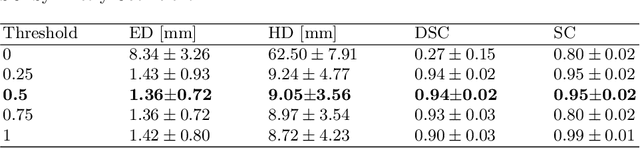
To improve the performance of most neuroimiage analysis pipelines, brain extraction is used as a fundamental first step in the image processing. But in the case of fetal brain development, there is a need for a reliable US-specific tool. In this work we propose a fully automated 3D CNN approach to fetal brain extraction from 3D US clinical volumes with minimal preprocessing. Our method accurately and reliably extracts the brain regardless of the large data variation inherent in this imaging modality. It also performs consistently throughout a gestational age range between 14 and 31 weeks, regardless of the pose variation of the subject, the scale, and even partial feature-obstruction in the image, outperforming all current alternatives.