 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense-Localizing Audio-Visual Events in Untrimmed Videos: A Large-Scale Benchmark and Baseline
Mar 24, 2023



Existing audio-visual event localization (AVE) handles manually trimmed videos with only a single instance in each of them. However, this setting is unrealistic as natural videos often contain numerous audio-visual events with different categories. To better adapt to real-life applications, in this paper we focus on the task of dense-localizing audio-visual events, which aims to jointly localize and recognize all audio-visual events occurring in an untrimmed video. The problem is challenging as it requires fine-grained audio-visual scene and context understanding. To tackle this problem, we introduce the first Untrimmed Audio-Visual (UnAV-100) dataset, which contains 10K untrimmed videos with over 30K audio-visual events. Each video has 2.8 audio-visual events on average, and the events are usually related to each other and might co-occur as in real-life scenes. Next, we formulate the task using a new learning-based framework, which is capable of fully integrating audio and visual modalities to localize audio-visual events with various lengths and capture dependencies between them in a single pass. Extensive experiments demonstrate the effectiveness of our method as well as the significance of multi-scale cross-modal perception and dependency modeling for this task.
Multi-Projection Fusion and Refinement Network for Salient Object Detection in 360° Omnidirectional Image
Dec 23, 2022



Salient object detection (SOD) aims to determine the most visually attractive objects in an image. With the development of virtual reality technology, 360{\deg} omnidirectional image has been widely used, but the SOD task in 360{\deg} omnidirectional image is seldom studied due to its severe distortions and complex scenes. In this paper, we propose a Multi-Projection Fusion and Refinement Network (MPFR-Net) to detect the salient objects in 360{\deg} omnidirectional image. Different from the existing methods, the equirectangular projection image and four corresponding cube-unfolding images are embedded into the network simultaneously as inputs, where the cube-unfolding images not only provide supplementary information for equirectangular projection image, but also ensure the object integrity of the cube-map projection. In order to make full use of these two projection modes, a Dynamic Weighting Fusion (DWF) module is designed to adaptively integrate the features of different projections in a complementary and dynamic manner from the perspective of inter and intra features. Furthermore, in order to fully explore the way of interaction between encoder and decoder features, a Filtration and Refinement (FR) module is designed to suppress the redundant information between the feature itself and the feature. Experimental results on two omnidirectional datasets demonstrate that the proposed approach outperforms the state-of-the-art methods both qualitatively and quantitatively.
Learning Detail-Structure Alternative Optimization for Blind Super-Resolution
Dec 03, 2022



Existing convolutional neural networks (CNN) based image super-resolution (SR) methods have achieved impressive performance on bicubic kernel, which is not valid to handle unknown degradations in real-world applications. Recent blind SR methods suggest to reconstruct SR images relying on blur kernel estimation. However, their results still remain visible artifacts and detail distortion due to the estimation errors. To alleviate these problems, in this paper, we propose an effective and kernel-free network, namely DSSR, which enables recurrent detail-structure alternative optimization without blur kernel prior incorporation for blind SR. Specifically, in our DSSR, a detail-structure modulation module (DSMM) is built to exploit the interaction and collaboration of image details and structures. The DSMM consists of two components: a detail restoration unit (DRU) and a structure modulation unit (SMU). The former aims at regressing the intermediate HR detail reconstruction from LR structural contexts, and the latter performs structural contexts modulation conditioned on the learned detail maps at both HR and LR spaces. Besides, we use the output of DSMM as the hidden state and design our DSSR architecture from a recurrent convolutional neural network (RCNN) view. In this way, the network can alternatively optimize the image details and structural contexts, achieving co-optimization across time. Moreover, equipped with the recurrent connection, our DSSR allows low- and high-level feature representations complementary by observing previous HR details and contexts at every unrolling time. Extensive experiments on synthetic datasets and real-world images demonstrate that our method achieves the state-of-the-art against existing methods. The source code can be found at https://github.com/Arcananana/DSSR.
Bridging Component Learning with Degradation Modelling for Blind Image Super-Resolution
Dec 03, 2022Convolutional Neural Network (CNN)-based image super-resolution (SR) has exhibited impressive success on known degraded low-resolution (LR) images. However, this type of approach is hard to hold its performance in practical scenarios when the degradation process is unknown. Despite existing blind SR methods proposed to solve this problem using blur kernel estimation, the perceptual quality and reconstruction accuracy are still unsatisfactory. In this paper, we analyze the degradation of a high-resolution (HR) image from image intrinsic components according to a degradation-based formulation model. We propose a components decomposition and co-optimization network (CDCN) for blind SR. Firstly, CDCN decomposes the input LR image into structure and detail components in feature space. Then, the mutual collaboration block (MCB) is presented to exploit the relationship between both two components. In this way, the detail component can provide informative features to enrich the structural context and the structure component can carry structural context for better detail revealing via a mutual complementary manner. After that, we present a degradation-driven learning strategy to jointly supervise the HR image detail and structure restoration process. Finally, a multi-scale fusion module followed by an upsampling layer is designed to fuse the structure and detail features and perform SR reconstruction. Empowered by such degradation-based components decomposition, collaboration, and mutual optimization, we can bridge the correlation between component learning and degradation modelling for blind SR, thereby producing SR results with more accurate textures. Extensive experiments on both synthetic SR datasets and real-world images show that the proposed method achieves the state-of-the-art performance compared to existing methods.
Feedback Chain Network For Hippocampus Segmentation
Nov 15, 2022The hippocampus plays a vital role in the diagnosis and treatment of many neurological disorders. Recent years, deep learning technology has made great progress in the field of medical image segmentation, and the performance of related tasks has been constantly refreshed. In this paper, we focus on the hippocampus segmentation task and propose a novel hierarchical feedback chain network. The feedback chain structure unit learns deeper and wider feature representation of each encoder layer through the hierarchical feature aggregation feedback chains, and achieves feature selection and feedback through the feature handover attention module. Then, we embed a global pyramid attention unit between the feature encoder and the decoder to further modify the encoder features, including the pair-wise pyramid attention module for achieving adjacent attention interaction and the global context modeling module for capturing the long-range knowledge. The proposed approach achieves state-of-the-art performance on three publicly available datasets, compared with existing hippocampus segmentation approaches.
PSNet: Parallel Symmetric Network for Video Salient Object Detection
Oct 12, 2022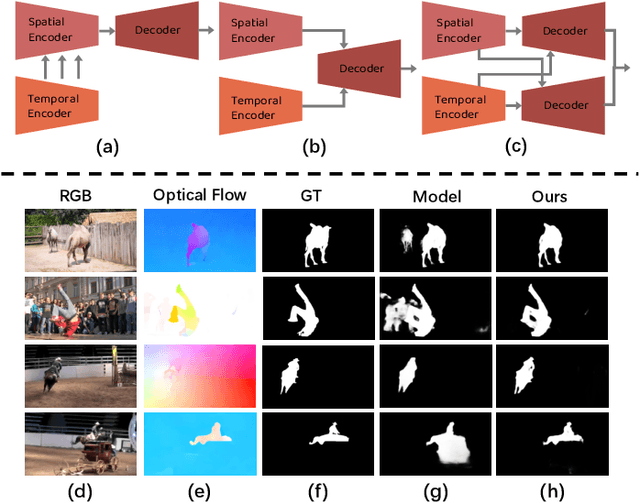
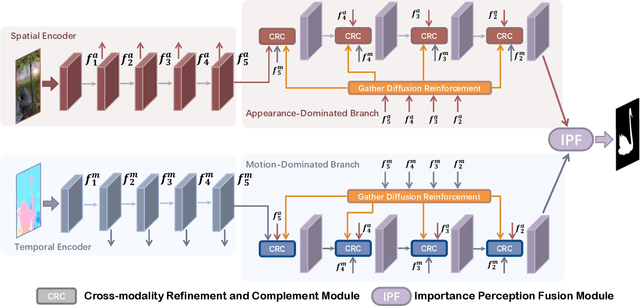
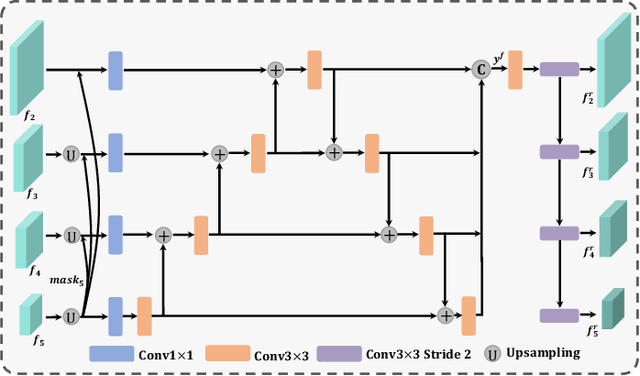
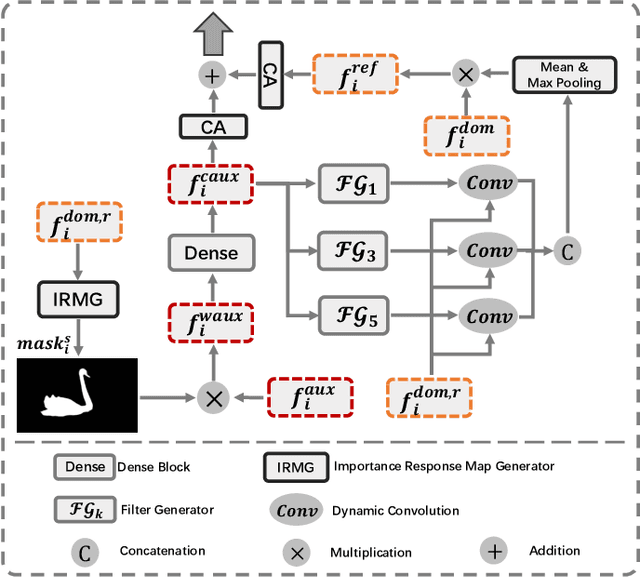
For the video salient object detection (VSOD) task, how to excavate the information from the appearance modality and the motion modality has always been a topic of great concern. The two-stream structure, including an RGB appearance stream and an optical flow motion stream, has been widely used as a typical pipeline for VSOD tasks, but the existing methods usually only use motion features to unidirectionally guide appearance features or adaptively but blindly fuse two modality features. However, these methods underperform in diverse scenarios due to the uncomprehensive and unspecific learning schemes. In this paper, following a more secure modeling philosophy, we deeply investigate the importance of appearance modality and motion modality in a more comprehensive way and propose a VSOD network with up and down parallel symmetry, named PSNet. Two parallel branches with different dominant modalities are set to achieve complete video saliency decoding with the cooperation of the Gather Diffusion Reinforcement (GDR) module and Cross-modality Refinement and Complement (CRC) module. Finally, we use the Importance Perception Fusion (IPF) module to fuse the features from two parallel branches according to their different importance in different scenarios. Experiments on four dataset benchmarks demonstrate that our method achieves desirable and competitive performance.
Does Thermal Really Always Matter for RGB-T Salient Object Detection?
Oct 09, 2022
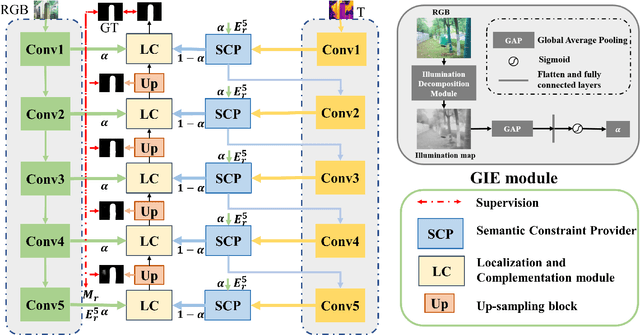
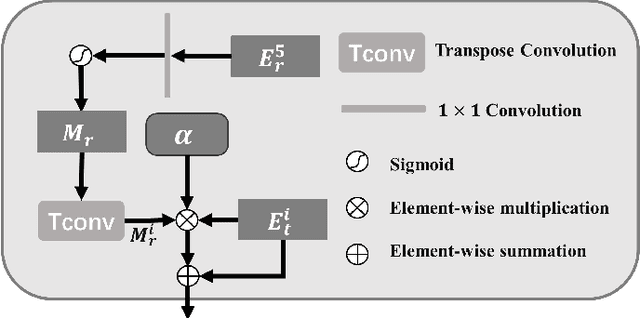

In recent years, RGB-T salient object detection (SOD) has attracted continuous attention, which makes it possible to identify salient objects in environments such as low light by introducing thermal image. However, most of the existing RGB-T SOD models focus on how to perform cross-modality feature fusion, ignoring whether thermal image is really always matter in SOD task. Starting from the definition and nature of this task, this paper rethinks the connotation of thermal modality, and proposes a network named TNet to solve the RGB-T SOD task. In this paper, we introduce a global illumination estimation module to predict the global illuminance score of the image, so as to regulate the role played by the two modalities. In addition, considering the role of thermal modality, we set up different cross-modality interaction mechanisms in the encoding phase and the decoding phase. On the one hand, we introduce a semantic constraint provider to enrich the semantics of thermal images in the encoding phase, which makes thermal modality more suitable for the SOD task. On the other hand, we introduce a two-stage localization and complementation module in the decoding phase to transfer object localization cue and internal integrity cue in thermal features to the RGB modality. Extensive experiments on three datasets show that the proposed TNet achieves competitive performance compared with 20 state-of-the-art methods.
CIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Oct 06, 2022


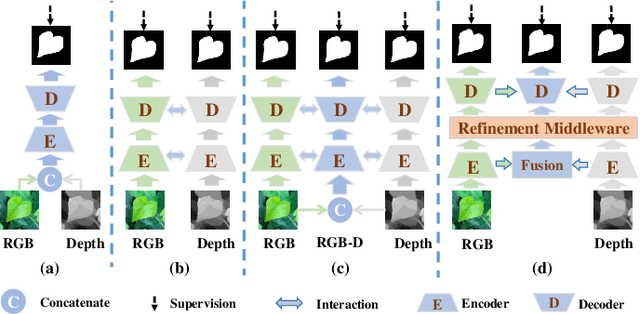
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement. For the cross-modality interaction, 1) a progressive attention guided integration unit is proposed to sufficiently integrate RGB-D feature representations in the encoder stage, and 2) a convergence aggregation structure is proposed, which flows the RGB and depth decoding features into the corresponding RGB-D decoding streams via an importance gated fusion unit in the decoder stage. For the cross-modality refinement, we insert a refinement middleware structure between the encoder and the decoder, in which the RGB, depth, and RGB-D encoder features are further refined by successively using a self-modality attention refinement unit and a cross-modality weighting refinement unit. At last, with the gradually refined features, we predict the saliency map in the decoder stage. Extensive experiments on six popular RGB-D SOD benchmarks demonstrate that our network outperforms the state-of-the-art saliency detectors both qualitatively and quantitatively.
A Weakly Supervised Learning Framework for Salient Object Detection via Hybrid Labels
Sep 07, 2022
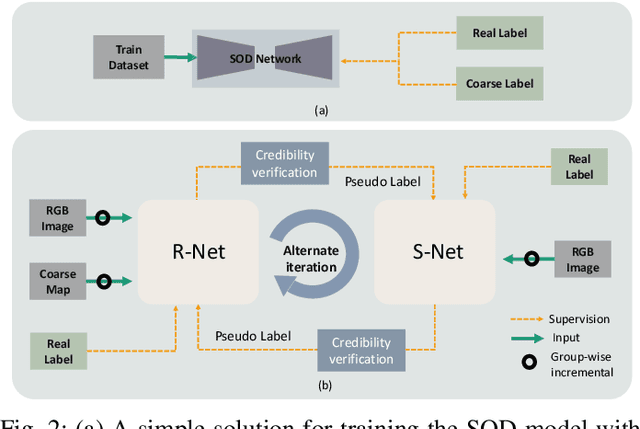
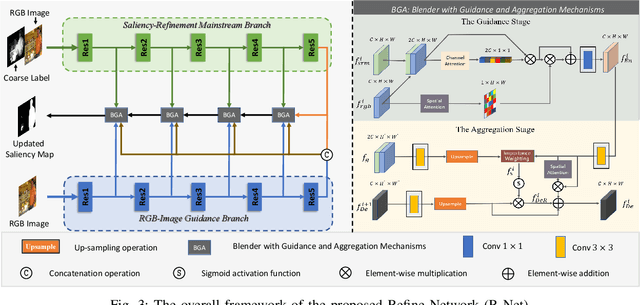
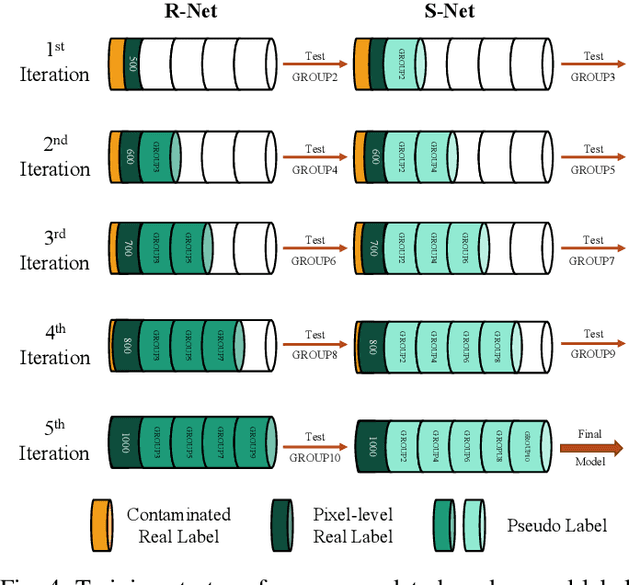
Fully-supervised salient object detection (SOD) methods have made great progress, but such methods often rely on a large number of pixel-level annotations, which are time-consuming and labour-intensive. In this paper, we focus on a new weakly-supervised SOD task under hybrid labels, where the supervision labels include a large number of coarse labels generated by the traditional unsupervised method and a small number of real labels. To address the issues of label noise and quantity imbalance in this task, we design a new pipeline framework with three sophisticated training strategies. In terms of model framework, we decouple the task into label refinement sub-task and salient object detection sub-task, which cooperate with each other and train alternately. Specifically, the R-Net is designed as a two-stream encoder-decoder model equipped with Blender with Guidance and Aggregation Mechanisms (BGA), aiming to rectify the coarse labels for more reliable pseudo-labels, while the S-Net is a replaceable SOD network supervised by the pseudo labels generated by the current R-Net. Note that, we only need to use the trained S-Net for testing. Moreover, in order to guarantee the effectiveness and efficiency of network training, we design three training strategies, including alternate iteration mechanism, group-wise incremental mechanism, and credibility verification mechanism. Experiments on five SOD benchmarks show that our method achieves competitive performance against weakly-supervised/unsupervised methods both qualitatively and quantitatively.
Boundary Guided Semantic Learning for Real-time COVID-19 Lung Infection Segmentation System
Sep 07, 2022
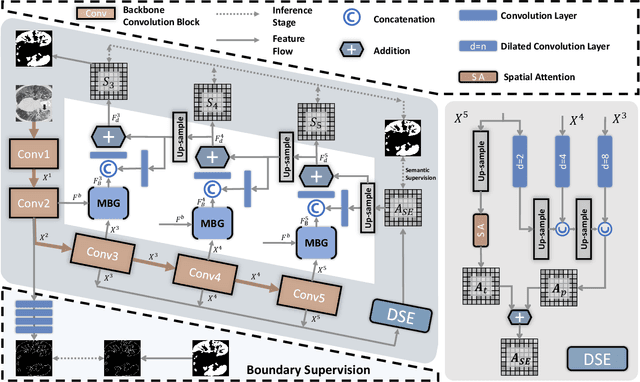
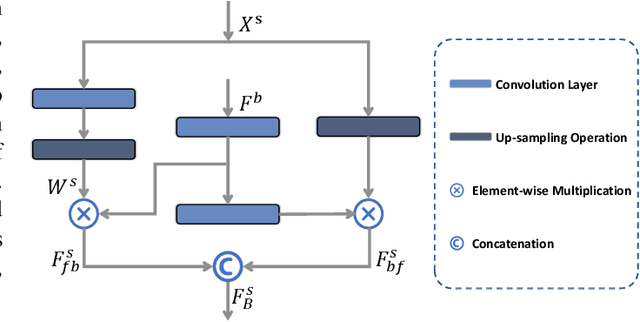
The coronavirus disease 2019 (COVID-19) continues to have a negative impact on healthcare systems around the world, though the vaccines have been developed and national vaccination coverage rate is steadily increasing. At the current stage, automatically segmenting the lung infection area from CT images is essential for the diagnosis and treatment of COVID-19. Thanks to the development of deep learning technology, some deep learning solutions for lung infection segmentation have been proposed. However, due to the scattered distribution, complex background interference and blurred boundaries, the accuracy and completeness of the existing models are still unsatisfactory. To this end, we propose a boundary guided semantic learning network (BSNet) in this paper. On the one hand, the dual-branch semantic enhancement module that combines the top-level semantic preservation and progressive semantic integration is designed to model the complementary relationship between different high-level features, thereby promoting the generation of more complete segmentation results. On the other hand, the mirror-symmetric boundary guidance module is proposed to accurately detect the boundaries of the lesion regions in a mirror-symmetric way. Experiments on the publicly available dataset demonstrate that our BSNet outperforms the existing state-of-the-art competitors and achieves a real-time inference speed of 44 FPS.