 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
May 28, 2025Recent studies on post-training large language models (LLMs) for reasoning through reinforcement learning (RL) typically focus on tasks that can be accurately verified and rewarded, such as solving math problems. In contrast, our research investigates the impact of reward noise, a more practical consideration for real-world scenarios involving the post-training of LLMs using reward models. We found that LLMs demonstrate strong robustness to substantial reward noise. For example, manually flipping 40% of the reward function's outputs in math tasks still allows a Qwen-2.5-7B model to achieve rapid convergence, improving its performance on math tasks from 5% to 72%, compared to the 75% accuracy achieved by a model trained with noiseless rewards. Surprisingly, by only rewarding the appearance of key reasoning phrases (namely reasoning pattern reward, RPR), such as ``first, I need to''-without verifying the correctness of answers, the model achieved peak downstream performance (over 70% accuracy for Qwen-2.5-7B) comparable to models trained with strict correctness verification and accurate rewards. Recognizing the importance of the reasoning process over the final results, we combined RPR with noisy reward models. RPR helped calibrate the noisy reward models, mitigating potential false negatives and enhancing the LLM's performance on open-ended tasks. These findings suggest the importance of improving models' foundational abilities during the pre-training phase while providing insights for advancing post-training techniques. Our code and scripts are available at https://github.com/trestad/Noisy-Rewards-in-Learning-to-Reason.
Extended Inductive Reasoning for Personalized Preference Inference from Behavioral Signals
May 23, 2025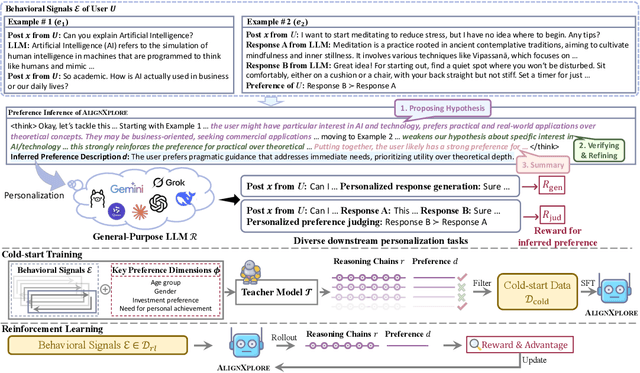

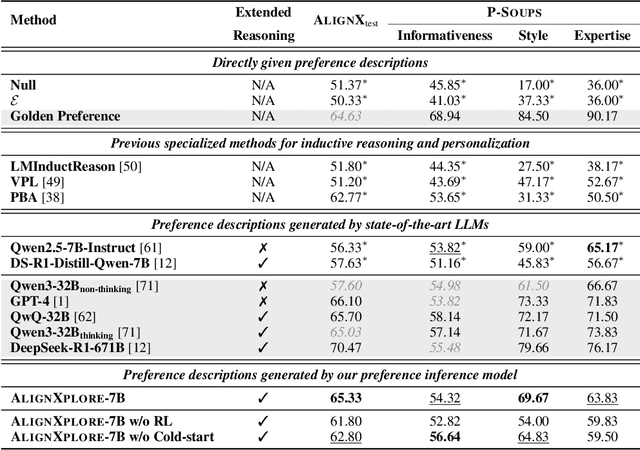
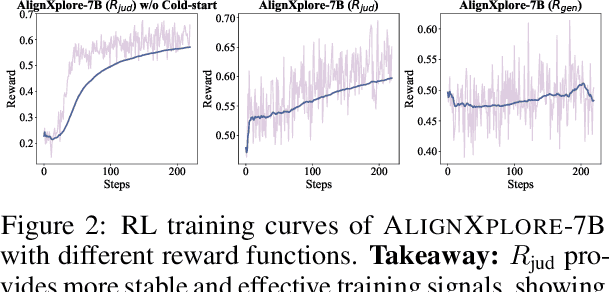
Large language models (LLMs) have demonstrated significant success in complex reasoning tasks such as math and coding. In contrast to these tasks where deductive reasoning predominates, inductive reasoning\textemdash the ability to derive general rules from incomplete evidence, remains underexplored. This paper investigates extended inductive reasoning in LLMs through the lens of personalized preference inference, a critical challenge in LLM alignment where current approaches struggle to capture diverse user preferences. The task demands strong inductive reasoning capabilities as user preferences are typically embedded implicitly across various interaction forms, requiring models to synthesize consistent preference patterns from scattered signals. We propose \textsc{AlignXplore}, a model that leverages extended reasoning chains to enable systematic preference inference from behavioral signals in users' interaction histories. We develop \textsc{AlignXplore} by combining cold-start training based on synthetic data with subsequent online reinforcement learning. Through extensive experiments, we demonstrate that \textsc{AlignXplore} achieves substantial improvements over the backbone model by an average of 11.05\% on in-domain and out-of-domain benchmarks, while maintaining strong generalization ability across different input formats and downstream models. Further analyses establish best practices for preference inference learning through systematic comparison of reward modeling strategies, while revealing the emergence of human-like inductive reasoning patterns during training.
R-Genie: Reasoning-Guided Generative Image Editing
May 23, 2025While recent advances in image editing have enabled impressive visual synthesis capabilities, current methods remain constrained by explicit textual instructions and limited editing operations, lacking deep comprehension of implicit user intentions and contextual reasoning. In this work, we introduce a new image editing paradigm: reasoning-guided generative editing, which synthesizes images based on complex, multi-faceted textual queries accepting world knowledge and intention inference. To facilitate this task, we first construct a comprehensive dataset featuring over 1,000 image-instruction-edit triples that incorporate rich reasoning contexts and real-world knowledge. We then propose R-Genie: a reasoning-guided generative image editor, which synergizes the generation power of diffusion models with advanced reasoning capabilities of multimodal large language models. R-Genie incorporates a reasoning-attention mechanism to bridge linguistic understanding with visual synthesis, enabling it to handle intricate editing requests involving abstract user intentions and contextual reasoning relations. Extensive experimental results validate that R-Genie can equip diffusion models with advanced reasoning-based editing capabilities, unlocking new potentials for intelligent image synthesis.
Beyond Static Testbeds: An Interaction-Centric Agent Simulation Platform for Dynamic Recommender Systems
May 22, 2025Evaluating and iterating upon recommender systems is crucial, yet traditional A/B testing is resource-intensive, and offline methods struggle with dynamic user-platform interactions. While agent-based simulation is promising, existing platforms often lack a mechanism for user actions to dynamically reshape the environment. To bridge this gap, we introduce RecInter, a novel agent-based simulation platform for recommender systems featuring a robust interaction mechanism. In RecInter platform, simulated user actions (e.g., likes, reviews, purchases) dynamically update item attributes in real-time, and introduced Merchant Agents can reply, fostering a more realistic and evolving ecosystem. High-fidelity simulation is ensured through Multidimensional User Profiling module, Advanced Agent Architecture, and LLM fine-tuned on Chain-of-Thought (CoT) enriched interaction data. Our platform achieves significantly improved simulation credibility and successfully replicates emergent phenomena like Brand Loyalty and the Matthew Effect. Experiments demonstrate that this interaction mechanism is pivotal for simulating realistic system evolution, establishing our platform as a credible testbed for recommender systems research.
Divide-Fuse-Conquer: Eliciting "Aha Moments" in Multi-Scenario Games
May 22, 2025Large language models (LLMs) have been observed to suddenly exhibit advanced reasoning abilities during reinforcement learning (RL), resembling an ``aha moment'' triggered by simple outcome-based rewards. While RL has proven effective in eliciting such breakthroughs in tasks involving mathematics, coding, and vision, it faces significant challenges in multi-scenario games. The diversity of game rules, interaction modes, and environmental complexities often leads to policies that perform well in one scenario but fail to generalize to others. Simply combining multiple scenarios during training introduces additional challenges, such as training instability and poor performance. To overcome these challenges, we propose Divide-Fuse-Conquer, a framework designed to enhance generalization in multi-scenario RL. This approach starts by heuristically grouping games based on characteristics such as rules and difficulties. Specialized models are then trained for each group to excel at games in the group is what we refer to as the divide step. Next, we fuse model parameters from different groups as a new model, and continue training it for multiple groups, until the scenarios in all groups are conquered. Experiments across 18 TextArena games show that Qwen2.5-32B-Align trained with the Divide-Fuse-Conquer strategy reaches a performance level comparable to Claude3.5, achieving 7 wins and 4 draws. We hope our approach can inspire future research on using reinforcement learning to improve the generalization of LLMs.
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Bridge the Gap between Past and Future: Siamese Model Optimization for Context-Aware Document Ranking
May 20, 2025In the realm of information retrieval, users often engage in multi-turn interactions with search engines to acquire information, leading to the formation of sequences of user feedback behaviors. Leveraging the session context has proven to be beneficial for inferring user search intent and document ranking. A multitude of approaches have been proposed to exploit in-session context for improved document ranking. Despite these advances, the limitation of historical session data for capturing evolving user intent remains a challenge. In this work, we explore the integration of future contextual information into the session context to enhance document ranking. We present the siamese model optimization framework, comprising a history-conditioned model and a future-aware model. The former processes only the historical behavior sequence, while the latter integrates both historical and anticipated future behaviors. Both models are trained collaboratively using the supervised labels and pseudo labels predicted by the other. The history-conditioned model, referred to as ForeRanker, progressively learns future-relevant information to enhance ranking, while it singly uses historical session at inference time. To mitigate inconsistencies during training, we introduce the peer knowledge distillation method with a dynamic gating mechanism, allowing models to selectively incorporate contextual information. Experimental results on benchmark datasets demonstrate the effectiveness of our ForeRanker, showcasing its superior performance compared to existing methods.
Unify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
Adaptive Gradient Learning for Spiking Neural Networks by Exploiting Membrane Potential Dynamics
May 17, 2025Brain-inspired spiking neural networks (SNNs) are recognized as a promising avenue for achieving efficient, low-energy neuromorphic computing. Recent advancements have focused on directly training high-performance SNNs by estimating the approximate gradients of spiking activity through a continuous function with constant sharpness, known as surrogate gradient (SG) learning. However, as spikes propagate among neurons, the distribution of membrane potential dynamics (MPD) will deviate from the gradient-available interval of fixed SG, hindering SNNs from searching the optimal solution space. To maintain the stability of gradient flows, SG needs to align with evolving MPD. Here, we propose adaptive gradient learning for SNNs by exploiting MPD, namely MPD-AGL. It fully accounts for the underlying factors contributing to membrane potential shifts and establishes a dynamic association between SG and MPD at different timesteps to relax gradient estimation, which provides a new degree of freedom for SG learning. Experimental results demonstrate that our method achieves excellent performance at low latency. Moreover, it increases the proportion of neurons that fall into the gradient-available interval compared to fixed SG, effectively mitigating the gradient vanishing problem.