 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Inductive Reasoning for Personalized Preference Inference from Behavioral Signals
Paper and Code
May 23, 2025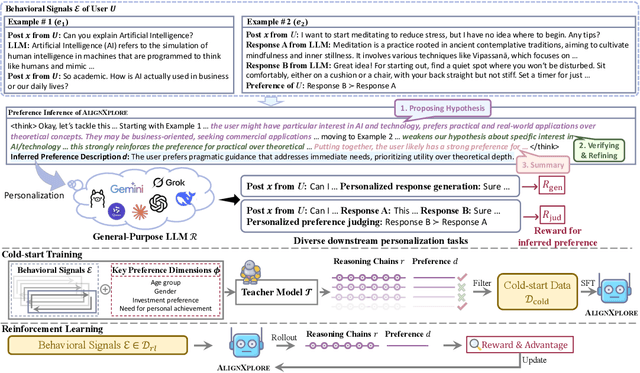

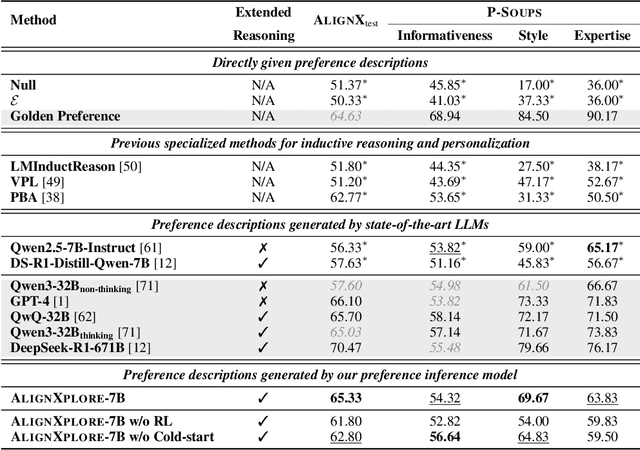
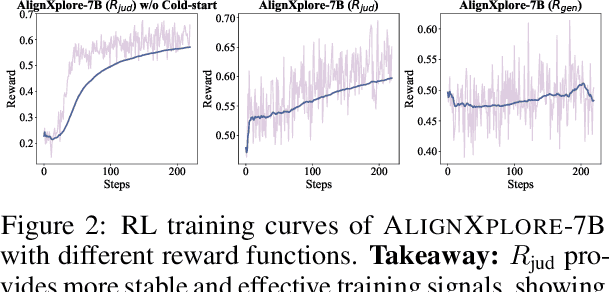
Large language models (LLMs) have demonstrated significant success in complex reasoning tasks such as math and coding. In contrast to these tasks where deductive reasoning predominates, inductive reasoning\textemdash the ability to derive general rules from incomplete evidence, remains underexplored. This paper investigates extended inductive reasoning in LLMs through the lens of personalized preference inference, a critical challenge in LLM alignment where current approaches struggle to capture diverse user preferences. The task demands strong inductive reasoning capabilities as user preferences are typically embedded implicitly across various interaction forms, requiring models to synthesize consistent preference patterns from scattered signals. We propose \textsc{AlignXplore}, a model that leverages extended reasoning chains to enable systematic preference inference from behavioral signals in users' interaction histories. We develop \textsc{AlignXplore} by combining cold-start training based on synthetic data with subsequent online reinforcement learning. Through extensive experiments, we demonstrate that \textsc{AlignXplore} achieves substantial improvements over the backbone model by an average of 11.05\% on in-domain and out-of-domain benchmarks, while maintaining strong generalization ability across different input formats and downstream models. Further analyses establish best practices for preference inference learning through systematic comparison of reward modeling strategies, while revealing the emergence of human-like inductive reasoning patterns during training.