 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-Assisted Multi-Frequency Attention Network for Pansharpening
Feb 07, 2025



Pansharpening aims to combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (LRMS) image to produce a high-resolution multispectral (HRMS) image. Although pansharpening in the frequency domain offers clear advantages, most existing methods either continue to operate solely in the spatial domain or fail to fully exploit the benefits of the frequency domain. To address this issue, we innovatively propose Multi-Frequency Fusion Attention (MFFA), which leverages wavelet transforms to cleanly separate frequencies and enable lossless reconstruction across different frequency domains. Then, we generate Frequency-Query, Spatial-Key, and Fusion-Value based on the physical meanings represented by different features, which enables a more effective capture of specific information in the frequency domain. Additionally, we focus on the preservation of frequency features across different operations. On a broader level, our network employs a wavelet pyramid to progressively fuse information across multiple scales. Compared to previous frequency domain approaches, our network better prevents confusion and loss of different frequency features during the fusion process. Quantitative and qualitative experiments on multiple datasets demonstrate that our method outperforms existing approaches and shows significant generalization capabilities for real-world scenarios.
DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
Jan 16, 2025Stereo matching is a key technique for metric depth estimation in computer vision and robotics. Real-world challenges like occlusion and non-texture hinder accurate disparity estimation from binocular matching cues. Recently, monocular relative depth estimation has shown remarkable generalization using vision foundation models. Thus, to facilitate robust stereo matching with monocular depth cues, we incorporate a robust monocular relative depth model into the recurrent stereo-matching framework, building a new framework for depth foundation model-based stereo-matching, DEFOM-Stereo. In the feature extraction stage, we construct the combined context and matching feature encoder by integrating features from conventional CNNs and DEFOM. In the update stage, we use the depth predicted by DEFOM to initialize the recurrent disparity and introduce a scale update module to refine the disparity at the correct scale. DEFOM-Stereo is verified to have comparable performance on the Scene Flow dataset with state-of-the-art (SOTA) methods and notably shows much stronger zero-shot generalization. Moreover, DEFOM-Stereo achieves SOTA performance on the KITTI 2012, KITTI 2015, Middlebury, and ETH3D benchmarks, ranking 1st on many metrics. In the joint evaluation under the robust vision challenge, our model simultaneously outperforms previous models on the individual benchmarks. Both results demonstrate the outstanding capabilities of the proposed model.
Fine-grained Video-Text Retrieval: A New Benchmark and Method
Dec 31, 2024The ability of perceiving fine-grained spatial and temporal information is crucial for video-language retrieval. However, the existing video retrieval benchmarks, such as MSRVTT and MSVD, fail to efficiently evaluate the fine-grained retrieval ability of video-language models (VLMs) due to a lack of detailed annotations. To address this problem, we present FIBER, a FIne-grained BEnchmark for text to video Retrieval, containing 1,000 videos sourced from the FineAction dataset. Uniquely, our FIBER benchmark provides detailed human-annotated spatial annotations and temporal annotations for each video, making it possible to independently evaluate the spatial and temporal bias of VLMs on video retrieval task. Besides, we employ a text embedding method to unlock the capability of fine-grained video-language understanding of Multimodal Large Language Models (MLLMs). Surprisingly, the experiment results show that our Video Large Language Encoder (VLLE) performs comparably to CLIP-based models on traditional benchmarks and has a stronger capability of fine-grained representation with lower spatial-temporal bias. Project page: https://fiber-bench.github.io.
CRM: Retrieval Model with Controllable Condition
Dec 18, 2024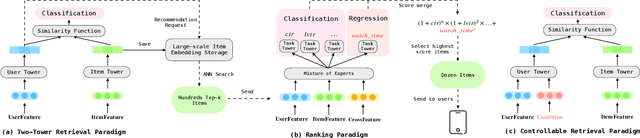

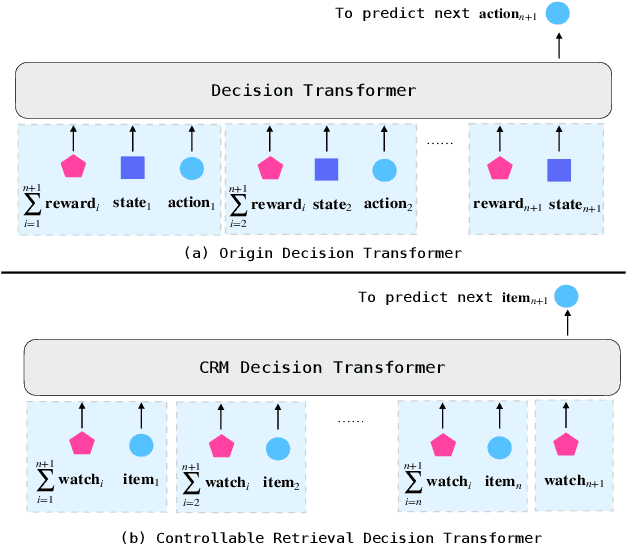
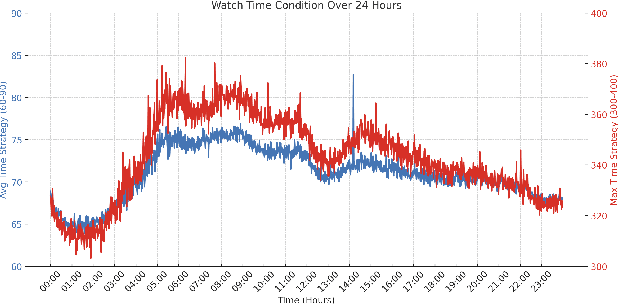
Recommendation systems (RecSys) are designed to connect users with relevant items from a vast pool of candidates while aligning with the business goals of the platform. A typical industrial RecSys is composed of two main stages, retrieval and ranking: (1) the retrieval stage aims at searching hundreds of item candidates satisfied user interests; (2) based on the retrieved items, the ranking stage aims at selecting the best dozen items by multiple targets estimation for each item candidate, including classification and regression targets. Compared with ranking model, the retrieval model absence of item candidate information during inference, therefore retrieval models are often trained by classification target only (e.g., click-through rate), but failed to incorporate regression target (e.g., the expected watch-time), which limit the effectiveness of retrieval. In this paper, we propose the Controllable Retrieval Model (CRM), which integrates regression information as conditional features into the two-tower retrieval paradigm. This modification enables the retrieval stage could fulfill the target gap with ranking model, enhancing the retrieval model ability to search item candidates satisfied the user interests and condition effectively. We validate the effectiveness of CRM through real-world A/B testing and demonstrate its successful deployment in Kuaishou short-video recommendation system, which serves over 400 million users.
Grasp What You Want: Embodied Dexterous Grasping System Driven by Your Voice
Dec 14, 2024In recent years, as robotics has advanced, human-robot collaboration has gained increasing importance. However, current robots struggle to fully and accurately interpret human intentions from voice commands alone. Traditional gripper and suction systems often fail to interact naturally with humans, lack advanced manipulation capabilities, and are not adaptable to diverse tasks, especially in unstructured environments. This paper introduces the Embodied Dexterous Grasping System (EDGS), designed to tackle object grasping in cluttered environments for human-robot interaction. We propose a novel approach to semantic-object alignment using a Vision-Language Model (VLM) that fuses voice commands and visual information, significantly enhancing the alignment of multi-dimensional attributes of target objects in complex scenarios. Inspired by human hand-object interactions, we develop a robust, precise, and efficient grasping strategy, incorporating principles like the thumb-object axis, multi-finger wrapping, and fingertip interaction with an object's contact mechanics. We also design experiments to assess Referring Expression Representation Enrichment (RERE) in referring expression segmentation, demonstrating that our system accurately detects and matches referring expressions. Extensive experiments confirm that EDGS can effectively handle complex grasping tasks, achieving stability and high success rates, highlighting its potential for further development in the field of Embodied AI.
GTPC-SSCD: Gate-guided Two-level Perturbation Consistency-based Semi-Supervised Change Detection
Nov 28, 2024



Semi-supervised change detection (SSCD) employs partially labeled data and a substantial amount of unlabeled data to identify differences between images captured in the same geographic area but at different times. However, existing consistency regularization-based SSCD methods only implement perturbations at a single level and can not exploit the full potential of unlabeled data. In this paper, we introduce a novel Gate-guided Two-level Perturbation Consistency regularization-based SSCD method (GTPC-SSCD), which simultaneously maintains strong-to-weak consistency at the image level and perturbation consistency at the feature level, thus effectively utilizing the unlabeled data. Moreover, a gate module is designed to evaluate the training complexity of different samples and determine the necessity of performing feature perturbations on each sample. This differential treatment enables the network to more effectively explore the potential of unlabeled data. Extensive experiments conducted on six public remote sensing change detection datasets demonstrate the superiority of our method over seven state-of-the-art SSCD methods.
Training an Open-Vocabulary Monocular 3D Object Detection Model without 3D Data
Nov 23, 2024



Open-vocabulary 3D object detection has recently attracted considerable attention due to its broad applications in autonomous driving and robotics, which aims to effectively recognize novel classes in previously unseen domains. However, existing point cloud-based open-vocabulary 3D detection models are limited by their high deployment costs. In this work, we propose a novel open-vocabulary monocular 3D object detection framework, dubbed OVM3D-Det, which trains detectors using only RGB images, making it both cost-effective and scalable to publicly available data. Unlike traditional methods, OVM3D-Det does not require high-precision LiDAR or 3D sensor data for either input or generating 3D bounding boxes. Instead, it employs open-vocabulary 2D models and pseudo-LiDAR to automatically label 3D objects in RGB images, fostering the learning of open-vocabulary monocular 3D detectors. However, training 3D models with labels directly derived from pseudo-LiDAR is inadequate due to imprecise boxes estimated from noisy point clouds and severely occluded objects. To address these issues, we introduce two innovative designs: adaptive pseudo-LiDAR erosion and bounding box refinement with prior knowledge from large language models. These techniques effectively calibrate the 3D labels and enable RGB-only training for 3D detectors. Extensive experiments demonstrate the superiority of OVM3D-Det over baselines in both indoor and outdoor scenarios. The code will be released.
QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024



In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.
KuaiFormer: Transformer-Based Retrieval at Kuaishou
Nov 15, 2024In large-scale content recommendation systems, retrieval serves as the initial stage in the pipeline, responsible for selecting thousands of candidate items from billions of options to pass on to ranking modules. Traditionally, the dominant retrieval method has been Embedding-Based Retrieval (EBR) using a Deep Neural Network (DNN) dual-tower structure. However, applying transformer in retrieval tasks has been the focus of recent research, though real-world industrial deployment still presents significant challenges. In this paper, we introduce KuaiFormer, a novel transformer-based retrieval framework deployed in a large-scale content recommendation system. KuaiFormer fundamentally redefines the retrieval process by shifting from conventional score estimation tasks (such as click-through rate estimate) to a transformer-driven Next Action Prediction paradigm. This shift enables more effective real-time interest acquisition and multi-interest extraction, significantly enhancing retrieval performance. KuaiFormer has been successfully integrated into Kuaishou App's short-video recommendation system since May 2024, serving over 400 million daily active users and resulting in a marked increase in average daily usage time of Kuaishou users. We provide insights into both the technical and business aspects of deploying transformer in large-scale recommendation systems, addressing practical challenges encountered during industrial implementation. Our findings offer valuable guidance for engineers and researchers aiming to leverage transformer models to optimize large-scale content recommendation systems.
CFPNet: Improving Lightweight ToF Depth Completion via Cross-zone Feature Propagation
Nov 07, 2024



Depth completion using lightweight time-of-flight (ToF) depth sensors is attractive due to their low cost. However, lightweight ToF sensors usually have a limited field of view (FOV) compared with cameras. Thus, only pixels in the zone area of the image can be associated with depth signals. Previous methods fail to propagate depth features from the zone area to the outside-zone area effectively, thus suffering from degraded depth completion performance outside the zone. To this end, this paper proposes the CFPNet to achieve cross-zone feature propagation from the zone area to the outside-zone area with two novel modules. The first is a direct-attention-based propagation module (DAPM), which enforces direct cross-zone feature acquisition. The second is a large-kernel-based propagation module (LKPM), which realizes cross-zone feature propagation by utilizing convolution layers with kernel sizes up to 31. CFPNet achieves state-of-the-art (SOTA) depth completion performance by combining these two modules properly, as verified by extensive experimental results on the ZJU-L5 dataset. The code will be made public.