 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fused State Representations for Control from Multi-View Observations
Feb 03, 2025



Multi-View Reinforcement Learning (MVRL) seeks to provide agents with multi-view observations, enabling them to perceive environment with greater effectiveness and precision. Recent advancements in MVRL focus on extracting latent representations from multiview observations and leveraging them in control tasks. However, it is not straightforward to learn compact and task-relevant representations, particularly in the presence of redundancy, distracting information, or missing views. In this paper, we propose Multi-view Fusion State for Control (MFSC), firstly incorporating bisimulation metric learning into MVRL to learn task-relevant representations. Furthermore, we propose a multiview-based mask and latent reconstruction auxiliary task that exploits shared information across views and improves MFSC's robustness in missing views by introducing a mask token. Extensive experimental results demonstrate that our method outperforms existing approaches in MVRL tasks. Even in more realistic scenarios with interference or missing views, MFSC consistently maintains high performance.
Understanding and Addressing the Pitfalls of Bisimulation-based Representations in Offline Reinforcement Learning
Oct 26, 2023



While bisimulation-based approaches hold promise for learning robust state representations for Reinforcement Learning (RL) tasks, their efficacy in offline RL tasks has not been up to par. In some instances, their performance has even significantly underperformed alternative methods. We aim to understand why bisimulation methods succeed in online settings, but falter in offline tasks. Our analysis reveals that missing transitions in the dataset are particularly harmful to the bisimulation principle, leading to ineffective estimation. We also shed light on the critical role of reward scaling in bounding the scale of bisimulation measurements and of the value error they induce. Based on these findings, we propose to apply the expectile operator for representation learning to our offline RL setting, which helps to prevent overfitting to incomplete data. Meanwhile, by introducing an appropriate reward scaling strategy, we avoid the risk of feature collapse in representation space. We implement these recommendations on two state-of-the-art bisimulation-based algorithms, MICo and SimSR, and demonstrate performance gains on two benchmark suites: D4RL and Visual D4RL. Codes are provided at \url{https://github.com/zanghyu/Offline_Bisimulation}.
Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
Oct 12, 2023



Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at https://github.com/Improbable-AI/dw-offline-rl.
* Accepted NeurIPS 2023
Combining Spatial and Temporal Abstraction in Planning for Better Generalization
Sep 30, 2023



Inspired by human conscious planning, we propose Skipper, a model-based reinforcement learning agent that utilizes spatial and temporal abstractions to generalize learned skills in novel situations. It automatically decomposes the task at hand into smaller-scale, more manageable subtasks and hence enables sparse decision-making and focuses its computation on the relevant parts of the environment. This relies on the definition of a high-level proxy problem represented as a directed graph, in which vertices and edges are learned end-to-end using hindsight. Our theoretical analyses provide performance guarantees under appropriate assumptions and establish where our approach is expected to be helpful. Generalization-focused experiments validate Skipper's significant advantage in zero-shot generalization, compared to existing state-of-the-art hierarchical planning methods.
Harnessing Mixed Offline Reinforcement Learning Datasets via Trajectory Weighting
Jun 22, 2023



Most offline reinforcement learning (RL) algorithms return a target policy maximizing a trade-off between (1) the expected performance gain over the behavior policy that collected the dataset, and (2) the risk stemming from the out-of-distribution-ness of the induced state-action occupancy. It follows that the performance of the target policy is strongly related to the performance of the behavior policy and, thus, the trajectory return distribution of the dataset. We show that in mixed datasets consisting of mostly low-return trajectories and minor high-return trajectories, state-of-the-art offline RL algorithms are overly restrained by low-return trajectories and fail to exploit high-performing trajectories to the fullest. To overcome this issue, we show that, in deterministic MDPs with stochastic initial states, the dataset sampling can be re-weighted to induce an artificial dataset whose behavior policy has a higher return. This re-weighted sampling strategy may be combined with any offline RL algorithm. We further analyze that the opportunity for performance improvement over the behavior policy correlates with the positive-sided variance of the returns of the trajectories in the dataset. We empirically show that while CQL, IQL, and TD3+BC achieve only a part of this potential policy improvement, these same algorithms combined with our reweighted sampling strategy fully exploit the dataset. Furthermore, we empirically demonstrate that, despite its theoretical limitation, the approach may still be efficient in stochastic environments. The code is available at https://github.com/Improbable-AI/harness-offline-rl.
Think Before You Act: Decision Transformers with Internal Working Memory
May 24, 2023Large language model (LLM)-based decision-making agents have shown the ability to generalize across multiple tasks. However, their performance relies on massive data and compute. We argue that this inefficiency stems from the forgetting phenomenon, in which a model memorizes its behaviors in parameters throughout training. As a result, training on a new task may deteriorate the model's performance on previous tasks. In contrast to LLMs' implicit memory mechanism, the human brain utilizes distributed memory storage, which helps manage and organize multiple skills efficiently, mitigating the forgetting phenomenon. Thus inspired, we propose an internal working memory module to store, blend, and retrieve information for different downstream tasks. Evaluation results show that the proposed method improves training efficiency and generalization in both Atari games and meta-world object manipulation tasks. Moreover, we demonstrate that memory fine-tuning further enhances the adaptability of the proposed architecture.
Behavior Prior Representation learning for Offline Reinforcement Learning
Nov 02, 2022



Offline reinforcement learning (RL) struggles in environments with rich and noisy inputs, where the agent only has access to a fixed dataset without environment interactions. Past works have proposed common workarounds based on the pre-training of state representations, followed by policy training. In this work, we introduce a simple, yet effective approach for learning state representations. Our method, Behavior Prior Representation (BPR), learns state representations with an easy-to-integrate objective based on behavior cloning of the dataset: we first learn a state representation by mimicking actions from the dataset, and then train a policy on top of the fixed representation, using any off-the-shelf Offline RL algorithm. Theoretically, we prove that BPR carries out performance guarantees when integrated into algorithms that have either policy improvement guarantees (conservative algorithms) or produce lower bounds of the policy values (pessimistic algorithms). Empirically, we show that BPR combined with existing state-of-the-art Offline RL algorithms leads to significant improvements across several offline control benchmarks.
Discrete Factorial Representations as an Abstraction for Goal Conditioned Reinforcement Learning
Nov 01, 2022Goal-conditioned reinforcement learning (RL) is a promising direction for training agents that are capable of solving multiple tasks and reach a diverse set of objectives. How to \textit{specify} and \textit{ground} these goals in such a way that we can both reliably reach goals during training as well as generalize to new goals during evaluation remains an open area of research. Defining goals in the space of noisy and high-dimensional sensory inputs poses a challenge for training goal-conditioned agents, or even for generalization to novel goals. We propose to address this by learning factorial representations of goals and processing the resulting representation via a discretization bottleneck, for coarser goal specification, through an approach we call DGRL. We show that applying a discretizing bottleneck can improve performance in goal-conditioned RL setups, by experimentally evaluating this method on tasks ranging from maze environments to complex robotic navigation and manipulation. Additionally, we prove a theorem lower-bounding the expected return on out-of-distribution goals, while still allowing for specifying goals with expressive combinatorial structure.
Expressiveness and Learnability: A Unifying View for Evaluating Self-Supervised Learning
Jun 02, 2022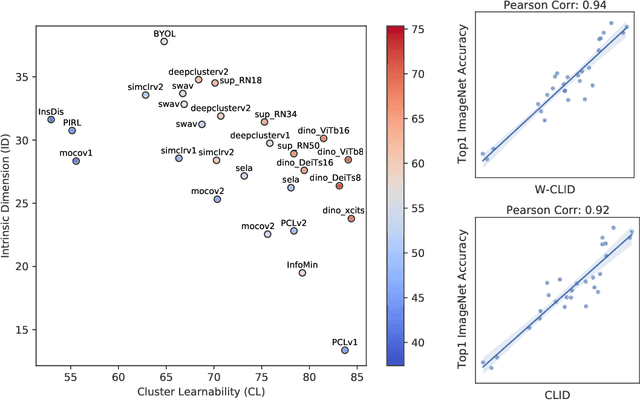
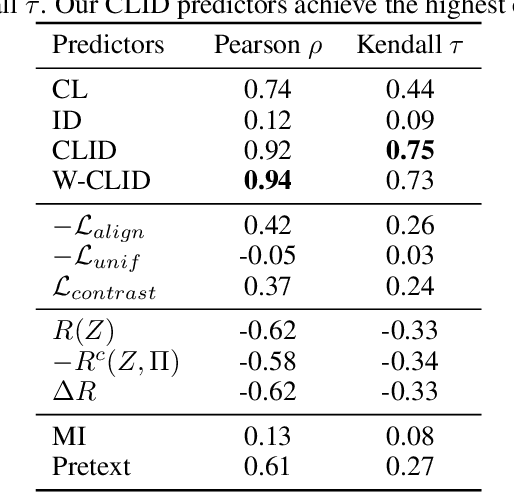
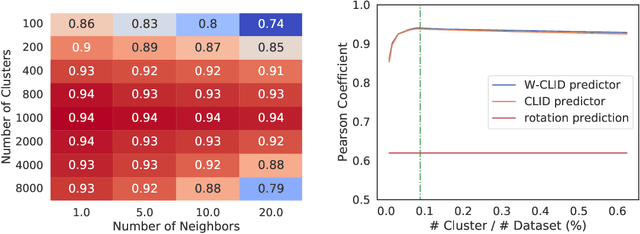
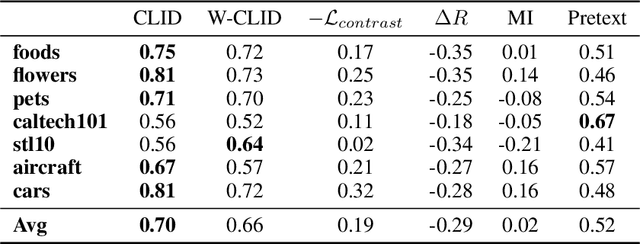
We propose a unifying view to analyze the representation quality of self-supervised learning (SSL) models without access to supervised labels, while being agnostic to the architecture, learning algorithm or data manipulation used during training. We argue that representations can be evaluated through the lens of expressiveness and learnability. We propose to use the Intrinsic Dimension (ID) to assess expressiveness and introduce Cluster Learnability (CL) to assess learnability. CL is measured as the learning speed of a KNN classifier trained to predict labels obtained by clustering the representations with K-means. We thus combine CL and ID into a single predictor: CLID. Through a large-scale empirical study with a diverse family of SSL algorithms, we find that CLID better correlates with in-distribution model performance than other competing recent evaluation schemes. We also benchmark CLID on out-of-domain generalization, where CLID serves as a predictor of the transfer performance of SSL models on several classification tasks, yielding improvements with respect to the competing baselines.
Incorporating Explicit Uncertainty Estimates into Deep Offline Reinforcement Learning
Jun 02, 2022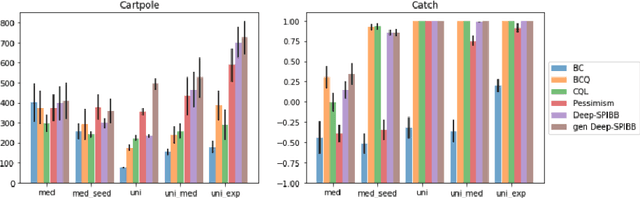

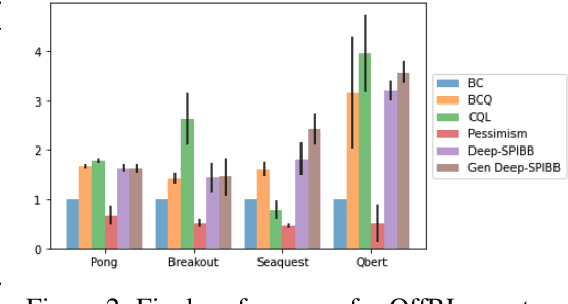
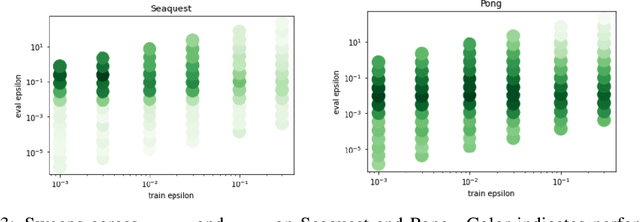
Most theoretically motivated work in the offline reinforcement learning setting requires precise uncertainty estimates. This requirement restricts the algorithms derived in that work to the tabular and linear settings where such estimates exist. In this work, we develop a novel method for incorporating scalable uncertainty estimates into an offline reinforcement learning algorithm called deep-SPIBB that extends the SPIBB family of algorithms to environments with larger state and action spaces. We use recent innovations in uncertainty estimation from the deep learning community to get more scalable uncertainty estimates to plug into deep-SPIBB. While these uncertainty estimates do not allow for the same theoretical guarantees as in the tabular case, we argue that the SPIBB mechanism for incorporating uncertainty is more robust and flexible than pessimistic approaches that incorporate the uncertainty as a value function penalty. We bear this out empirically, showing that deep-SPIBB outperforms pessimism based approaches with access to the same uncertainty estimates and performs at least on par with a variety of other strong baselines across several environments and datasets.